

Abstract
The distribution of diversity can vary considerably from clade to clade. Attempts to understand these patterns often employ state-dependent speciation and extinction models to determine whether the evolution of a particular novel trait has increased speciation rates and/or decreased their extinction rates. It is still unclear, however, whether these models are uncovering important drivers of diversification, or whether they are simply pointing to more complex patterns involving many unmeasured and co-distributed factors. Here we describe an extension to the popular state-dependent speciation and extinction models that specifically accounts for the presence of unmeasured factors that could impact diversification rates estimated for the states of any observed trait, solving at least one major criticism of BiSSE methods. Specifically, our model, which we refer to as HiSSE (Hidden-State Speciation and Extinction), assumes that related to each observed state in the model are “hidden” states that exhibit potentially distinct diversification dynamics and transition rates than the observed states in isolation. Under rigorous simulation tests and when applied to empirical data, we find that HiSSE performs reasonably well, and can at least detect net diversification rate differences between observed and hidden states and detect when diversification rate differences do not correlate with observed states. We also discuss the remaining issues with state-dependent speciation and extinction models in general, and the important ways in which HiSSE provides a more nuanced understanding of trait-dependent diversification.
A key question in biology is why some groups are much more diverse than others. Discussions of such questions are often focused on whether there is something unique about exceptionally diverse lineages, such as the presence of some novel trait, which has increased their speciation rate and/or decreased their extinction rates. The BiSSE model (Binary-State Speciation and Extinction; Maddison et al. 2007) was derived specifically as a means of examining the effect that the presence or absence of a single character could have on diversification rates, while also accounting for possible transitions between states. In theory, this model could be used not only for identifying differences in diversification, but also detecting differences in transitions between character states, or even some interplay of the two. In practice, however, it has mainly been used to focus on diversification rate differences (e.g., Goldberg et al. 2010; Wilson et al. 2011; Price et al. 2012; Beaulieu and Donoghue 2013; Weber and Agrawal, 2014).
It is somewhat surprising, perhaps, that studies that employ BiSSE often find that the prediction of a trait leading to higher diversification rates is supported by the data. In fact, all sorts of traits have been implicated as potential drivers of diversity patterns, ranging from the evolution of herbivory in mammals (Price et al. 2012), to the evolution of extra-floral nectaries in flowering plants (Weber and Agrawal 2014), to even the evolution of particular body plans in fungi (i.e., gasteroid vs. nongasteroid forms; Wilson et al. 2011). Some important caveats are needed, however. First, Rabosky and Goldberg (2015) recently showed that for realistically complex data sets, BiSSE methods almost always incorrectly finds that a neutral trait is correlated with higher diversification. Maddison and FitzJohn (2014) raise a more philosophical concern regarding the inability of these methods to properly account for independence. Consider, for instance, that the carpel, which encloses the seeds of angiosperms, has evolved only once. They argue that the inheritance of a single event becomes problematic – even if BiSSE uncovers a significant correlation between the carpel and diversification, it is unclear whether the carpel is an important driver of the immense diversity of flowering plants, or whether this diversity is simply coincidental. Finally, it was pointed out by Beaulieu and Donoghue (2013) that even in the case of multiple origins of a trait, it could be that only one clade actually has a higher diversification rate associated with the focal trait, which is strong enough to return higher diversification rates for that trait as a whole. In their case, it appeared that plants with an achene (a fruit resembling a bare seed, as in “sunflower seeds”) had a higher diversification rate, but upon subdividing the tree it appeared that this was from the inclusion of one clade in particular, the highly diverse Asteraceae, or the sunflower family. They argue that it is far more likely that some combination of the achene and another unmeasured, co-distributed trait led to a higher diversification rate (on this point, also see Maddison et al. 2007).
All these caveats more or less relate to the broader issue of whether the proximate drivers of diversification are really ever just the focal traits themselves. At greater phylogenetic scales this issue seems the most relevant, where the context of a shared trait is unlikely to be consistent across many taxonomically distinct clades. In other words, a characters’ effect on diversification will often be contingent on other factors, such as the assembly of particular combinations of characters (e.g., a “synnovation” as defined by Donoghue and Sanderson 2015) and/or movements into new geographic regions (e.g., de Querioz 2002; Moore and Donoghue 2007). Recent generalizations of the BiSSE model (i.e., MuSSE: Multistate Speciation and Extinction; FitzJohn 2012) do allow for additional binary characters to be accounted for when examining the correlation between a binary trait and net diversification. However, it may not always be clear what the exact characters might be, and in the absence of such information, it should be difficult to ever confidently view any character state as the true underlying cause of increased diversification rates.
Here we describe a potential way forward for trait-dependent models of diversification by extending the BiSSE framework to account for the presence of unmeasured factors that could impact diversification rates estimated for the states of any observed trait. Our model, which we refer to as HiSSE (Hidden State Speciation and Extinction), assumes that related to each observed state in the model are “hidden” states that exhibit potentially distinct diversification dynamics and transition rates than the observed states in isolation. In this way, HiSSE is a state-dependent speciation and extinction form of a Hidden Markov model (HMM). As we will show, HiSSE can adequately distinguish higher net diversification rates within clades exhibiting a particular character state when they exist, and can provide a much more refined understanding of how particular observed character states may influence the diversification process.
The Hidden State Speciation and Extinction Model
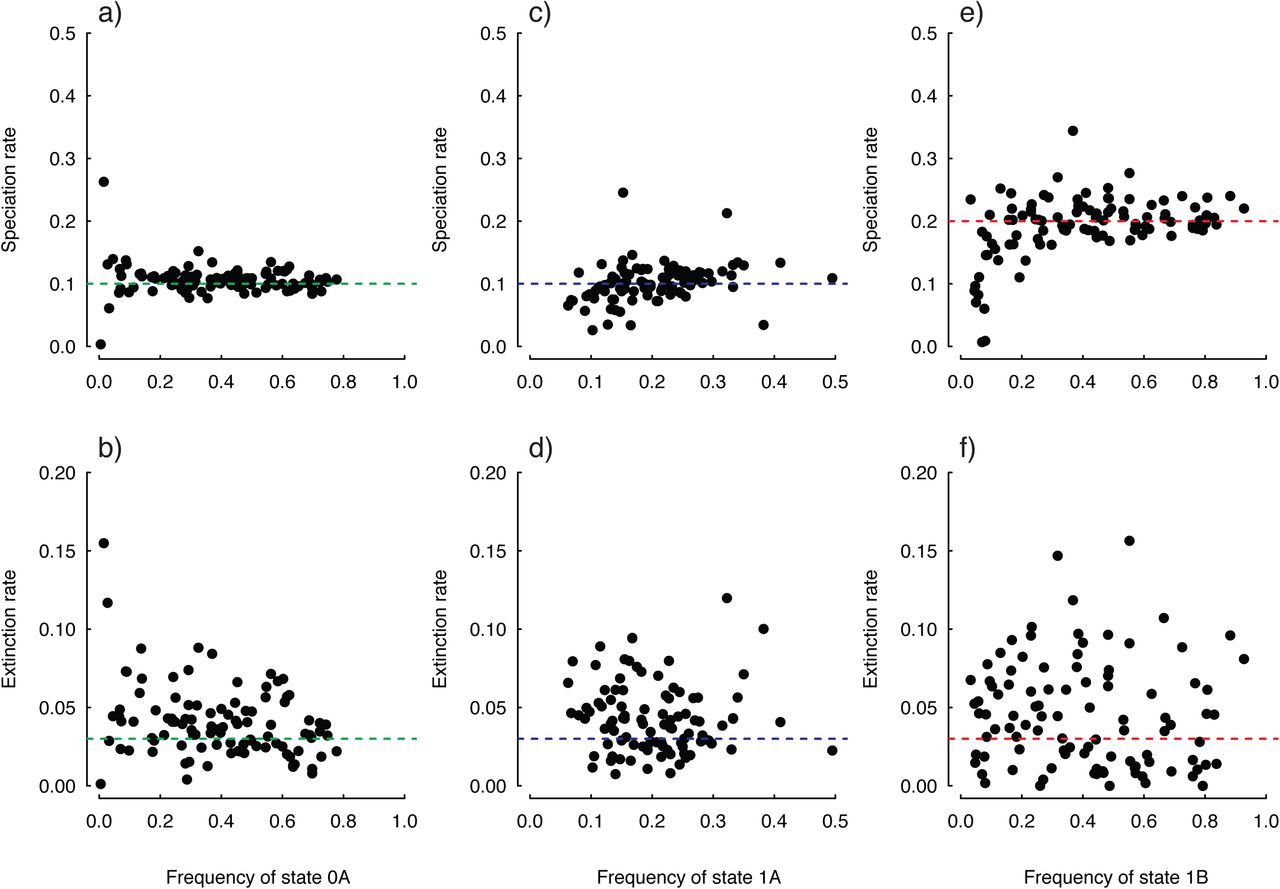
Despite the important methodological advancement and power afforded by the BiSSE model, it can still provide a rather coarse-grained view of trait-based patterns of diversification. Specifically, what may appear like a causal connection when examining particular characters in isolation may actually be due to other unmeasured factors, or because the analysis included a nested clade that exhibits both the focal character plus “something” else (Maddison et al. 2007; Beaulieu and Donoghue 2013; Beaulieu and O'Meara 2014). This particular point is illustrated in Figure 1. Here the true underlying model is one in which state 0 and 1 have identical diversification rates. However, there is some other trait with states A and B, and state B has twice the diversification rate of A. We call this trait a “hidden” trait, because it is not observed in the tip data (though it could be observable if we knew what it was). If state 1 happens to be a prerequisite for evolving state B (or even by chance), all the state 0 branches will have state A, but some branches in state 1 will have state A and some will have state B. Thus state 1 actually takes on two states, 1A when the hidden state with higher diversification rate is absent, and 1B when the hidden state with higher diversification rate is present. As indicated by the model, transitions to this unmeasured variable produce nested shifts towards higher rates of diversification within clades comprised of species in state 1. Necessarily, BiSSE can only infer parameters for characters that we can observe, and since all origins of state 1 are lumped together, the model incorrectly infers state 1 as being associated with significantly higher diversification rates.

We attempt to solve this problem by deriving an extension to the BiSSE model that allows for the inference of these hidden states. For the example in Figure 1, we can assume that all observations of state 1 are actually ambiguous for being in each of the possible hidden states, 1A (i.e., hidden state absent) or state 1B (i.e., hidden state present). We then include transition rates and parameters for the diversification process associated with this hidden state. Our model, which we refer to hereafter as the HiSSE model (Hidden State Speciation and Extinction model), is actually a modified form of the MuSSE model (Multi-State Speciation and Extinction; FitzJohn 2012) that extends BiSSE type analyses to allow for multiple binary characters or characters with more than two states. Thus, the HiSSE model is general, and, in theory, can have a number of observed states and a number of hidden states (i.e., observed states 0, 1, 2, and hidden states A, B, C, resulting in nine possible state combinations).
The likelihood DN,i(t), of any HiSSE model, is proportional to the probability that a lineage in state i (e.g., i = 0A, 1A, or 1B) at time t before the present (t=0) evolved the exact branching structure and character states as observed. Changes in DN,i over time along a branch are described by the following ordinary differential equation:
 where Ei(t) is the probability that a lineage in state i at time, t, goes completely extinct by the present, and is described by:
where Ei(t) is the probability that a lineage in state i at time, t, goes completely extinct by the present, and is described by:

These series of equations are solved numerically along each edge starting tipward and moving rootward. The initial conditions for DN,i(0) are set to 1 when the trait is consistent with the observed data, and 0 otherwise. In the case of the hidden state scenario described above, we set the probability to 1 for both state 1A and 1B for all species exhibiting state 1: that is, the probability of observing a tip demonstrating state 1 is 1 if the true underlying state is 1A or 1B (note this could be done with states 1C, 1D, and so forth). In the general case, we would also set the probability to 1 for 0A, 0B, etc. for all species state exhibiting state 0, and could do the same for states 2, 3, and higher (though the current implementation currently allows a binary observed state and four or fewer hidden states). The initial conditions for Ei(0) are all set to zero (i.e., we observe the tip in the present). Incomplete sampling can be allowed by incorporating a state-specific or even clade-specific sampling frequency, f, and setting the initial conditions for DN,i(0) as fi if the corresponding tip, n, is in state i, and 0 otherwise, and for 1-fi for Ei(0) (FitzJohn et al., 2009). We assume the sampling frequency of the hidden state to be identical to the state with which it is associated (e.g., f1A = f1B, f0A = f0B).
At each ancestral node, A, that joins descendant lineages N and M, we multiply the probabilities of both daughter lineages together with the rate of speciation:
 and the resulting values become the initial conditions for the subtending branch. The overall likelihood is the product of DR,i(t) calculated at the root. We condition this likelihood by (1-Ei(t))2, which is the probability that the two descendant lineages of the root, evolving under the same estimates of speciation and extinction, survived to the present and were sampled (Nee et al. 1994). Finally, we follow the procedure described by FitzJohn et al. (2009) and also weight the overall likelihood by the likelihood that each possible state gave rise to the observed data. Note that in the absence of a hidden state, our likelihood calculation reduces exactly to a two-state BiSSE model.
and the resulting values become the initial conditions for the subtending branch. The overall likelihood is the product of DR,i(t) calculated at the root. We condition this likelihood by (1-Ei(t))2, which is the probability that the two descendant lineages of the root, evolving under the same estimates of speciation and extinction, survived to the present and were sampled (Nee et al. 1994). Finally, we follow the procedure described by FitzJohn et al. (2009) and also weight the overall likelihood by the likelihood that each possible state gave rise to the observed data. Note that in the absence of a hidden state, our likelihood calculation reduces exactly to a two-state BiSSE model.
As stated above, the HiSSE model can include any number of hidden states associated with the observed states of a binary character. For example, it is straightforward in this framework to generate the SSE equivalent of the “precursor” model described by Marazzi et al. (2012) or the “hidden rates” model (HRM) described by Beaulieu et al. (2013). In the latter case, consider a HiSSE model with “two rate classes”, A and B. We can define speciation and extinction parameters for states 0A, 1A, 0B, and 1B, and then define a set of transitions to account for transitioning between all character state combinations:

Thus, HiSSE can be used to account for differences in the diversification process while simultaneously identifying different classes of transition rates within a binary character. Our implementation allows for this and more complex models, including those that allow for dual transitions between both the observed trait and the hidden trait (e.g., q0A↔q1B).
An important issue was recently raised by Rabosky and Goldberg (2015), who demonstrated that on empirical trees even traits evolving under a neutral, diversification-independent model will still tend to be best fit by a BiSSE model. While this behavior is seemingly troubling, it is important to bear in mind that BiSSE, HiSSE, and any other model of state-dependent speciation and extinction are not models of trait evolution, but rather are joint models for the underlying tree and the traits. A trait evolution model like those in Pagel (1994) or Hansen (1997) maximizes the probability of the observed states at the tips, given the tree and model – the tree certainly affects the likelihood of the tip data, but that is the only way it enters the calculation. A trait-based diversification model, on the other hand, maximizes the probability of the observed states at the tips and the observed tree, given the model. If a tree violates a single regime birth-death model due to any number of causes (e.g., mass extinction events, trait-dependent speciation or extinction, maximum carrying capacity, climate change affecting speciation rates, etc.), then even if the tip data are perfectly consistent with a simple model, the tip data plus the tree are not. In such a case, it should not be surprising that a more complex model will tend to be chosen over a nested simpler model, particularly if the underlying tree is large enough.
Furthermore, as is well known in statistics, rejecting the null model does not imply that the alternative model is true. It simply means that the alternative model fits better. This will often be the case when looking at models in any complex system where the true model may not be one of the included models. For example, Rabosky and Goldberg (2015) showed, among several other empirical examples, that data sets simulated under a model with characters having no effect on diversification rate on an empirical tree of cetaceans (i.e., whales, dolphins, and relatives) almost always rejected the null model. Though presented as a Type I error (i.e., incorrectly rejecting a true null), it is not. While the chosen character model is wrong, the cetacean tree is almost certainly not evolving with a single speciation and extinction rate for the entire clade (see Slater et al. 2010; Morlon et al. 2011). BiSSE is correct in saying that the simple model is not correct, but it is very wrong in assigning rate differences to the simulated traits.
The broader point here is that in comparative biology we often compare trivial nulls. For instance, we often ask questions like, “is there a single rate of evolution over the whole tree?” The answer is often an unsurprising, “no”, because for most complex real data a comparison between a simple model and one with even slightly more complexity will very likely yield strong support for the latter. In our view, a fairer comparison would involve some sort of null model that contains the same degree of complexity in terms of numbers of parameters to allow for comparisons among any complex model of interest. Such tests should avoid falling into the trap of choosing a model purely on the basis of it having more parameters, and, in theory, should solve the issue raised by Rabosky and Goldberg (2015).
Here we propose two null models that are devised to equal the complexity with respect to the number of parameters for the diversification process [i.e., same number of free speciation and extinction rates under the Maddison et al. (2007) parameterization] as a general BiSSE or HiSSE model, but without actually linking them to the observed traits. Thus, these null models explicitly assume that the evolution of a binary character is independent of the diversification process without forcing diversification process to be constant across the entire tree, which is the normal null used in these types of analyses.
The first model, which we refer to as “null-two”, contains four diversification process parameters that account for trait-dependent diversification solely on the two states of an unobserved, hidden trait (e.g., for speciation rates, λ0A= λ1A, λ0B= λ1B). In this way, null-two contains the same amount of complexity in terms of diversification as a BiSSE model. However, the possible transition rates under this model take the form described in Eq. (3) to account for the possible transitions among all state combinations. These transition rates can be general by allowing them all to be freely estimated, or simplified in various ways such as assuming they are all equal. The second model, which we refer to as “null-four” contains the same number of diversification parameters as in the general HiSSE model that are linked across four hidden states (e.g., for speciation rates, λ0A= λ1A, λ0B= λ1B, λ0C=λ1C, λ0D= λ1D). The transition rates under this model are set up to account for transitions between the different four rate categories, as well as between the states of the binary character and, in matrix form, they are set up as follows:

To simplify the number of transitions in the model there are two natural assumptions: assume either all transition rates are equal, or assume there are three distinct transition rates: one rate describing transitions among the different hidden states (i.e., the rates in columns and rows 1-4, and columns and rows 5-8), and two rates for transitions between the observed character states (i.e., one rate for columns 5-8, rows 1-4, and one rate for columns 1-4, and rows 5-8).
Implementation
We implemented the above models in the R package “hisse” available through CRAN. As input all that hisse requires is a phylogeny with branch lengths and a data file that contains the observed states of a binary character. Note that this is an entirely new implementation, not a fork of the existing diversitree package, as we employ modified optimization procedures and model configurations. For example, rather than optimizing λi and μi separately, hisse optimizes orthogonal transformations of these variables: we let “i = λi+μi define “net turnover”, and we let εi = μi /λi define the extinction fraction. This reparameterization alleviates problems associated with over-fitting when λi and μi are highly correlated, but both matter in explaining the diversity pattern (e.g., Goldberg et al. 2010; Beaulieu and Donoghue 2013). With empirical data we often see good estimates for diversification rate but correlations for birth and death rate estimates. For example, Beaulieu and Donoghue (2013) (their Figure S2) showed that the confidence region for birth and death rates tightly follows a diagonal line, with different characters having lines of the same slope but different intercepts. This leads to a behavior where looking at the confidence or credibility intervals for birth or death show overlap between the characters but intervals for diversification rates do not overlap between characters. However, the only way to fit this in the normal parameterization is with two birth rates and two death rates. Reparameterizing, as we do, allows us to have the same turnover rate for both states but estimate different diversification rates, resulting in a less complex, but better fitting, model. Thus, users specify configurations of models that variously fix τi and εi. Note that estimates of τi and εi can be easily backtransformed to reflect estimates of λi and μi by

 which can be used to derive other measures of diversification process parameters, such as net diversification (λi-μi).
which can be used to derive other measures of diversification process parameters, such as net diversification (λi-μi).
The hisse package assigns the probability of each ancestral state to an internal node using marginal ancestral state reconstruction (Yang et al.1995; Schluter et al., 1997). These probabilities can be used to “paint” areas of a phylogeny where the diversification rate has increased or decreased due to some unmeasured character. In our implementation the marginal probability of state i for a focal node is simply the overall likelihood of the tree and data when the state of the focal node is fixed in state i. Note that the likeliest tip states can also be estimated: we observe state 1, but the underlying state could either be state 1A or 1B. Thus, for any given node or tip we traverse the entire tree as many times as there are states in the model. As the size of the tree grows, however, these repeated tree traversals can slow the calculation down considerably. For this reason, we also include a function that allows the marginal calculation to be conducted in parallel across any number of independent computer processors.
Simulations
We evaluated the performance of the HiSSE model by simulating trees and characters states under various scenarios and then estimating the fit and bias of the inferred rates from these trees. Our initial simulations first tested scenarios along the lines of the single hidden state situation described in Figure 1; the known parameters for each scenario are described in detail in Table 1. We also included BiSSE scenarios to test whether we could correctly conclude that there was no support for a HiSSE model in the absence of a hidden state in the generating model. For each scenario, trees and trait data were simulated using diversitree (FitzJohn 2012) to contain 50, 100, 200, or 400 species, with 100 replicates for each taxon set. When the generating model included a hidden state, we simulated trees that could transition between three possible states: 0, 1, or 2. After each simulation replicate was completed, we created the hidden state by simply switching the state of all tips observed in state 2 to be in state 1.
Summary of model support for simulated scenarios with and without a hidden trait, where calculating the average Akaike weight (wi) for all models assessed the fit. We also calculated a null expectation of the Akaike weight as the average Akaike weight if we assumed an equal likelihood across all models. Thus, the null expectation is based solely on the penalty term in the AIC calculation.
Each simulated data set was evaluated under the generating model, as well as 13 additional models that variously added, removed, or constrained certain parameters. The entire model set is described in Table 1. For all models under a given scenario, model fit was assessed by calculating the average Akaike weight (wi), which represents the relative likelihood that model i is the best model given a set of models (Burnham and Anderson 2002). We also calculated a null expectation of the Akaike weight across our model set, as the average Akaike weight assuming an equal likelihood across all models. Thus, our null expectation is based solely on the penalty term in the AIC calculation – in the absence of information from the model, we would expect to see these weights returned, rather than equal weights for all models. Moreover, since BiSSE is nested within HiSSE, they could return the same likelihood, so even with infinite amounts of data the weight of the HiSSE model should drop to this null expectation, but, counterintuitively, not to zero.
Comparing the model-average of the parameters against the known parameters provided an assessment of the bias and precision of the inferred parameters. However, rather than averaging parameters across the entire model set, we only averaged across models that included similar parameters. For example, when estimating the bias in the HiSSE scenarios we only model-averaged parameters for models that included the hidden state. This required reformulating the Akaike weights to reflect the truncated model set. Finally, we assessed the reliability of the ancestral state reconstructions by comparing the true node states from each simulated tree to the marginal probabilities calculated from the model-averaged parameter estimates.
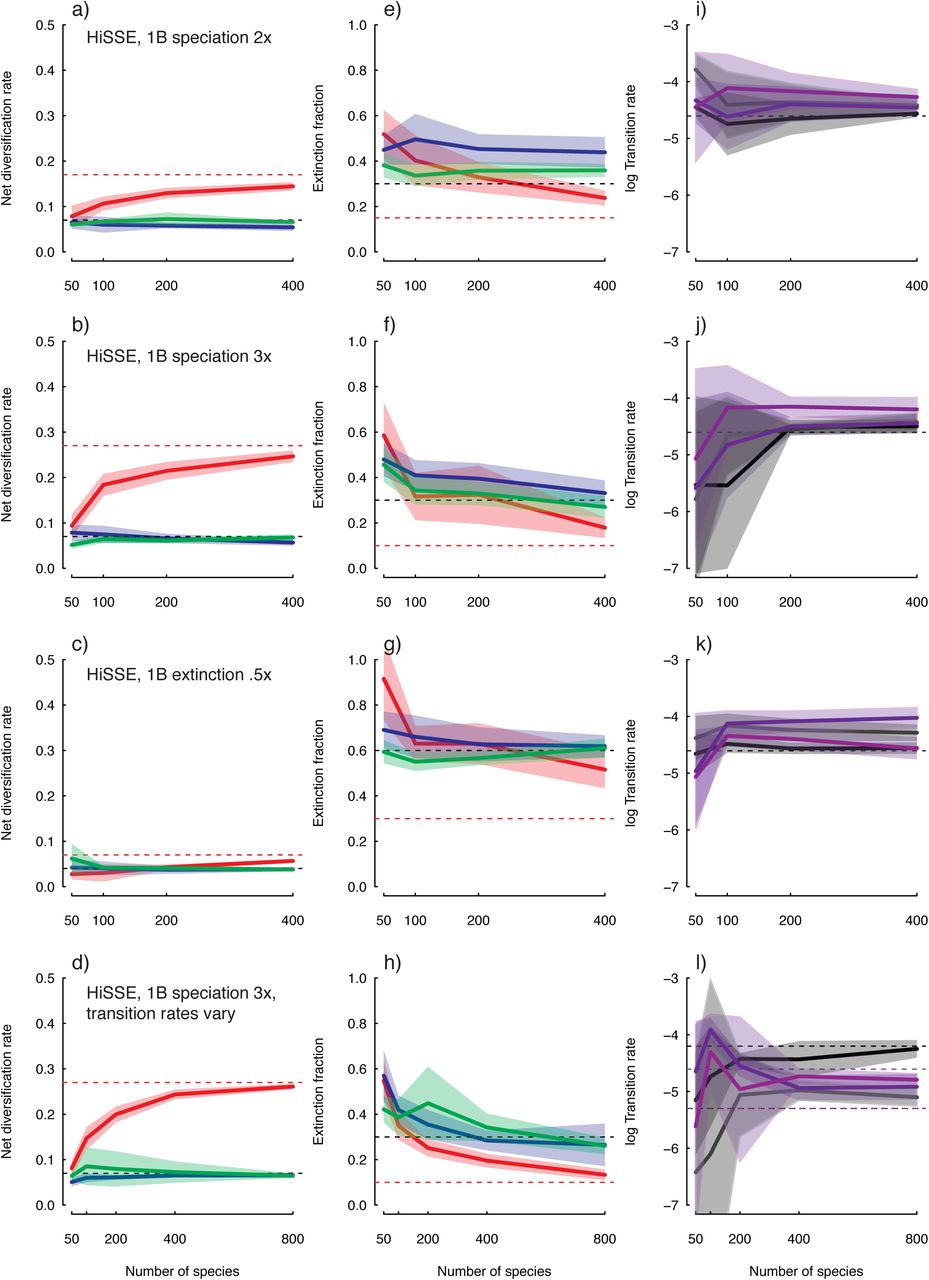
From a model comparison perspective, our simulations indicated that data sets that lack hidden states could generally be distinguished from those that do, especially with larger data sets (Table 1). When the generating model is a BiSSE model with only two observable states, there were low levels of support for all seven HiSSE models. In fact, as sample size increased, the average Akaike weight of the HiSSE models converged towards the null Akaike weight based only on the penalty term (Table 1). When evaluating data sets that included a hidden state, the ability to correctly favor a HiSSE model over any of the BiSSE models depended not just on the size of the data set, but also the underlying generating model. For example, when the generating model assumed a hidden state with higher speciation rates, data sets that contained 200 or more taxa were required to provide strong support for a HiSSE model that varied the turnover rate (Table 1). However, when the main effect of the generating model assumed lower extinction fractions for the hidden state there remained strong support for a BiSSE model that assumed both equal turnover rates and extinction fractions. Interestingly, when we simulated under a HiSSE scenario that combines the processes of higher speciation rates and asymmetrical transition rates, the issue of incorrectly favoring a BiSSE model disappears (Table 1).
It is important to point out that in all simulation scenarios we never recovered strong support for a model consistent with the model that actually generated the data. That is, whether we vary the speciation rate or the extinction rate, which affects both net turnover and extinction fraction, we always found support for a simplified model that either allowed τ to vary or ε to vary, but not both. This is likely a consequence of the uncertainty and upward biases in estimates of extinction fraction (Fig. 2), making it difficult for the model to infer multiple extinction fractions, at least with smaller data sets.

It is well known that there can be difficulties, generally, in obtaining precise estimates of the extinction rates (i.e., μi) under the BiSSE framework (Maddison et al. 2007). Backtransforming estimates of net turnover and extinction fraction shows that HiSSE suffers the same precision issues in regards to the rate of extinction (Fig. 3, Fig. S2). Recently, it was reported that biases in the tip state ratios could also generally impact all parameter estimates (see Davis et al. 2013). Our simulations did not specifically test issues related to tip state biases. However, we did find that with HiSSE, the precision in extinction rate estimates remains fairly low regardless of the ratio of the states at the tips, especially when estimating extinction for the hidden state (Fig. 3). Interestingly, the lack of precision for extinction rates seems to have a relatively minor impact on estimates of net turnover or net diversification (Fig. 2; Fig. S1), though there is a general bias for net diversification to be underestimated as a consequence of inflated extinction rates.
Nevertheless, it appears HiSSE correctly and qualitatively distinguishes differences in diversification among the various states in the model. And, as the number of species increases, the trajectory of the downward bias in net diversification suggests it will eventually disappear, and rate differences can be distinguished even if the differences are trivial (e.g., Fig. 2c).
One issue of concern from our simulations is that transition rates are almost always overestimated. This behavior appears unique to the HiSSE model in our simulations (Fig. 2), given that when evaluating data sets under BiSSE scenarios, transition rates are estimated reasonably well (Fig. S3). One suggestion from Rich FitzJohn (personal communication) is that this can occur when some states are present in low frequency, and since HiSSE has more states than BiSSE, it is likely that many state combinations are in very low frequencies. There are also relatively large confidence intervals surrounding each of the transition rate estimates that naturally favor models that assume equal transition rates, which should be reflected in the model-averaged rates. Indeed, as in the case of the HiSSE scenario that assumed pronounced differences in the transition rates, even 800 taxa was still not enough to unequivocally reject models that assumed equal transition rates (Table 1). We also examined the impact each parameter had on a fixed set of equilibrium frequencies, by randomly sampling sets of values and retaining those that estimated the same frequency within a small measure of error (see Supplemental Materials). The proportional range of values for the transition rates were more than double those found for the speciation rate, indicating that state frequencies are fairly resilient to changes in the transition rates. Taken together, estimating unique transition rates (and to some extent the rate of extinction) appears to be a naturally difficult problem, which is not made any easier by HiSSE's increase in state space. That is to say, conceptually, HiSSE requires more from the data by including additional parameters without providing any more observable information. It is likely that in many cases far larger data sets with many more state origins than the ones we have generated here may be required to adequately estimate these particular parameters.
In regards to inference of ancestral states, the simulations indicate that HiSSE correctly identifies and locates regions of the tree where supposed diversification rate differences have taken place (Fig. 4). The degree of reliability does, of course, depend on the size of the data set. For the HiSSE scenario that assumed a doubled speciation rate for state 1B, for example, data sets comprised of 50 taxa, 84.1% of the nodes, on average, have the state correctly inferred, and data sets comprised of 400 taxa 92.4% are correct. However, we note that there is also a general tendency for HiSSE to infer high marginal probabilities for the incorrect state (e.g., Fig. 4), which could provide misleadingly confident state reconstructions.

Finally, we evaluated the performance of the general HiSSE model and our two null models of character-independent diversification. Our goal was to test not just the fit and biases of the general trait-dependent HiSSE model, but also our ability to accept or properly rule out the trait-independent models under scenarios of trait-dependent diversification. We were concerned at the outset that our null models would always fit at least as well, if not better, than a trait-dependent BiSSE or HiSSE model. That is to say, these models were constructed such that they are not constrained by character states and can assign rates wherever they want in order to maximize the likelihood. Table 2 describes the known parameters for the three scenarios evaluated. As before, diversitree was used to simulate trees and trait data that contained 400 species, repeated 100 times, with transitions allowed between four possible states, 0, 1, 2, or 3. As before, after each simulation replicate was completed, we created the hidden state by simply switching the state of all tips observed in state 2 to be in state 0, and all tips in state 3 to be in state 1.
Summary of the model support for simulated scenarios that tested the performance of the general HiSSE model and two null models (null-two, null-four; see text). All data sets tested contained 400 species, and calculating the average Akaike weight (wi) for all models assessed the fit. As with Table 1, we calculated a null expectation of the Akaike weight as the average Akaike weight if we assumed an equal likelihood across all models.
The fit of alternative models of achene fruit evolution in the Dipsidae. The best model, based on λAIC and Akaike weights (wi) is denoted in bold.
We also included a scenario that was designed to test whether the general HiSSE model is immune to empirical issues of spurious assignment of importance to state combinations that have no true effect on diversification. In other words, is HiSSE still favored in situations where the trees and traits evolved under a very different model than the one used for inference? Here we generated trees containing 400 taxa using code from Rabosky (2010). A symmetric Markov model for trait evolution alone (no influence by diversification) was used to simulate binary traits on this tree (using the R package geiger; Harmon et al. 2008; Pennell et al. 2014). The Rabosky (2010) model was used, as it is very different from the model assumed by BiSSE/HiSSE; speciation rates evolve gradually on branches, rather than moving discretely between distinct levels based on a trait (hidden or not). Though the rate change is gradual under the Rabosky (2010) model, the speciation rate does not evolve under a Brownian, Ornstein-Uhlenbeck, or similar processes, but in a hetergeneous way that depends on the timing of speciation events (Beaulieu and O'Meara 2015). Thus, as with many empirical data sets, this diversification model is quite different from HiSSE's model, providing a difficult challenge. The Rabosky (2010) model has also been very influential in affecting biologists' attitudes towards estimating extinction rates, and so we include it as a semi-realistic “worst-case” scenario.
In the four scenarios described above, each simulated data set was evaluated under the generating model, as well as nine additional models, that variously added, removed, or constrained certain parameters, with model fit being assessed by calculating the average Akaike weight (wi). The entire model set is described in Table 2. For simplicity, all models in the set assumed equal transition rates.
Overall, we found that HiSSE was able to distinguish between generating models that assumed diversification rates differences are trait-dependent (e.g., when speciation is two-fold greater for state 1B), or when the diversification rate difference is trait-independent and due to simply to the presence of a hidden trait only (e.g., when speciation is two-fold greater for hidden state B) (Table 2). We also found that, contrary to our concerns, when the generating model assumed some form of trait-dependent diversification neither the null-two, nor the null-four model had much support. In regards to parameter estimates, we found that the model-average parameters largely resembled the generating model (Fig. 5, S4). However, similar to the previous set of simulations, there is a large amount of uncertainty and upward biases in estimates of extinction fraction. This is likely the reason why we always found greater support for a simplified model that allowed τ to vary, but not both τ and ε (Table 2).
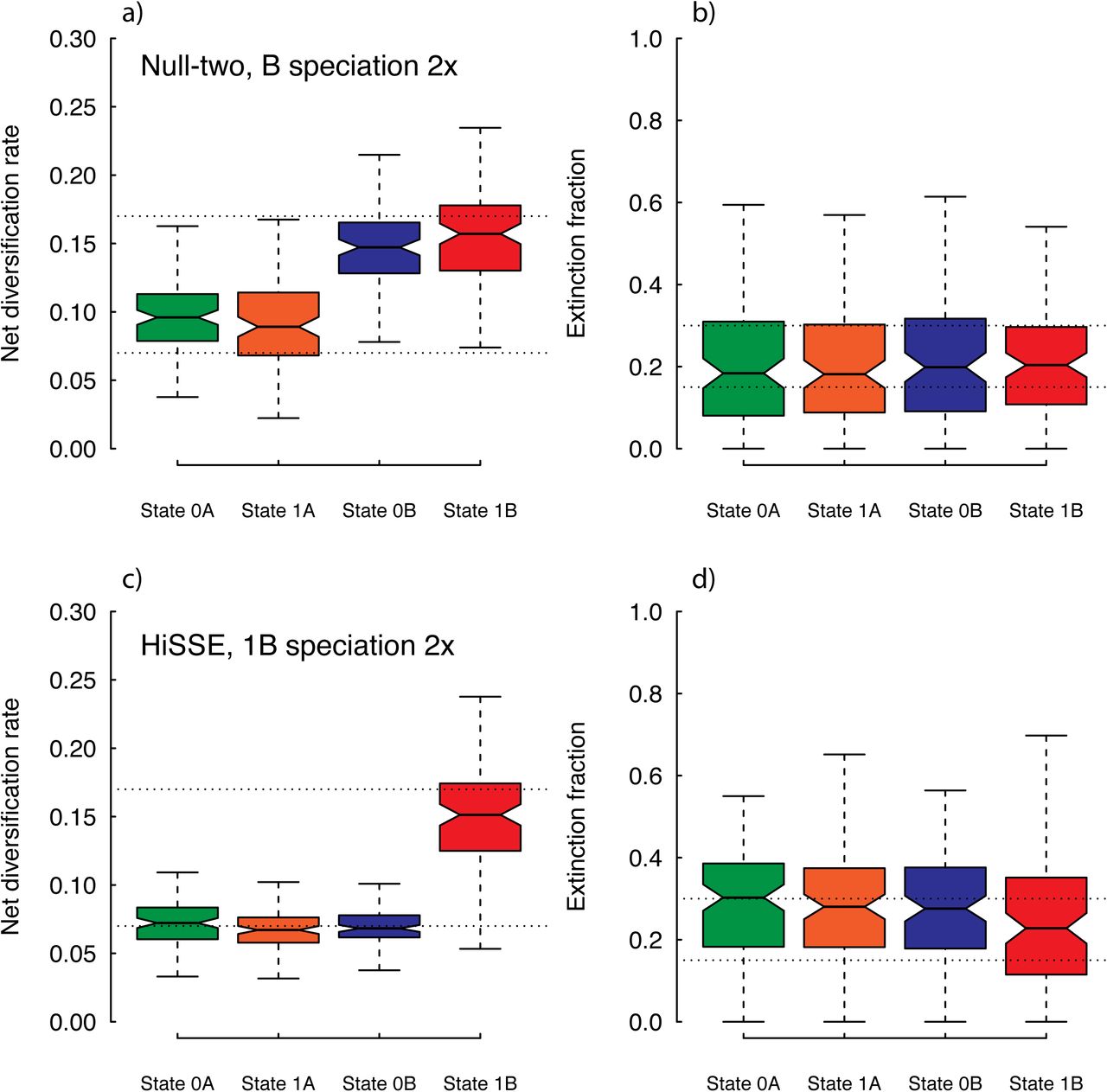
For the “worst-case” scenario, which simulated a neutral binary character along trees generated from a complex heterogeneous rate branching process, it truly falls into the zone where BiSSE has issues (87% of data sets favored a state-dependent BiSSE model over a single-rate diversification model, and the average Akaike weight for state-dependent models across data sets was 91%; see Table S1). Thus, these simulation conditions create difficult data sets of the sort used by Rabosky and Goldberg (2015). The addition of merely the null-two model dramatically fixed this, where the average weight for the state-dependent models went from 91% to 1.1%, and all data sets chose the null-two model as best (see Table S1). When the full HiSSE model set was examined, we found that the null-four trait independent model had the highest support on average across the entire set of models (Table 2), and was the best overall in 71% of the simulations. Although this null model still assumes shifts among distinct levels, it is the model in the set that more closely resembles the conditions by which these data sets were generated. We note, however, that there was some support for a trait-dependent HiSSE model with the same number of diversification parameters (Table 2). And, in spite of the Akaike weight across all data sets showing greater support for the null-four model on average, 29% of the individual data sets would favor some form of the general HiSSE model. Nevertheless, there was only a 1.02% difference in the mean diversification rate between states 0 and 1 (though, focusing on just the set of trees for which a HiSSE model was best, the percent difference is 16% – still relatively small for diversification studies, but clearly not as good). Taken together, these results indicate that in these “worst-case” trait-independent scenarios, likely encountered in many empirical data sets, the inclusion of the null models can fix the issue of spuriously accepting trait-dependent diversification. The addition of models that allow some dependence with the observed traits and some with hidden traits, the rates of falsely assessing some state-dependence somewhat increases, but with the benefit of being able to better detect hidden effects when they are true (see earlier simulation results).
The evolution of achene fruits
The development of this model was inspired by results from recent empirical work that applied BiSSE to understand the macroevolutionary consequences of evolving particular fruit types within a large flowering plant clade (i.e., campanulids; Beaulieu and Donoghue 2013). This study investigated whether diversification rates differences could explain why more than 80% of campanulid species exhibit fruits that are indehiscent (i.e., do not open mechanically), dry, and contain only a single seed. From a terminological standpoint, these fruits were broadly referred to as “achene” or “achene-like” to unify the various terms used to identify the same basic fruit character configuration (e.g., “cypselas” of the Asteraceae – sunflowers and their relatives – or the single-seeded “mericarps” of the Apiaceae – carrots and their relatives). According to the BiSSE model, the preponderance of achene fruits within campanulids can be explained by strong differences in diversification rates, with achene lineages having a rate that was roughly three times higher than non-achene lineages.
While these results are seemingly straightforward, they are complicated by the fact that the correlation between net diversification rates and the achene character state differed among the major campanulid lineages and was driven entirely by the inclusion of the Asterales clade (Beaulieu and Donoghue 2013). Within the Apiales and the Dipsacales, the two remaining major achene-bearing clades, the diversification rate differences were not technically significant. However, in both these clades there were qualitative differences in the predicted direction, likely as a consequence of one or more shifts in diversification nested within one of the major achene-bearing clades. Together, these point to a more complex scenario for the interaction between achene fruits and diversification patterns that is not being adequately explained by BiSSE.
We illustrate an empirical application of HiSSE by examining the Dipsidae (Paracryphiales+Dipsacales; Tank and Donoghue 2010) portion of the achene data set of Beaulieu and Donoghue (2013). Specifically, we used HiSSE to locate and “paint” potential areas within Dipsidae that may be inflating the estimates of net diversification rates for achene lineages as a whole. We modified the original data set of Beaulieu and Donoghue (2013) in three important ways. First, we re-estimated the original molecular branch lengths using PAUP* (Swofford 2000), as opposed to relying on the branch lengths from the original RAxML (Stamatakis 2006) analysis, because PAUP* provides better optimization precision. Second, the molecular branch lengths were re-scaled in units of time using treePL (Smith and O'Meara 2012), an implementation of the penalized likelihood dating method of Sanderson (2002) specifically designed for large trees. We applied the same temporal constraints for Dipsidae as in the original Beaulieu and Donoghue (2013) study, and used cross-validation to determine the smoothing value that best predicted the rates of terminal branches pruned from the tree. Third, we conservatively removed various taxa of dubious taxonomic distinction, taxa considered varietals or subspecies of a species already contained within the tree, and tips that treePL assigned very short branch lengths (i.e., <1.0 Myr) – all of which have the tendency to negatively impact accuracy of estimating diversification rates (though in this case, rerunning the analyses including such tips did not have a qualitative effect on the results). The exclusion of these taxa resulted in a data set comprised of 417 species from the original 457.
We fit 24 different models to the achene data set for Dipsidae. Four of these models corresponded to BiSSE models that either removed or constrained particular parameters, 16 corresponded to various HiSSE models that assumed a hidden state associated with both the observed states (i.e., non-achene+, achene+), and four corresponded to various forms of our trait-independent null models (i.e., null-two, null-four). In all cases, we incorporated a unique sampling frequency scheme to the model. Rather than assuming random sampling for the entire tree (see above), we included the sampling frequency for each major clade included in the tree (see Table S2). In order to generate a measure of confidence for parameters estimated under a given model, we implemented an “adaptive search” procedure that provides an estimate of the parameter space that is some pre-defined likelihood distance (e.g., 2lnL units) from the maximum likelihood estimate (MLE), which follows from Edwards (1992). We also took into account both state uncertainty and uncertainty in the model when “painting” diversification rates across the tree. Our procedure first calculated a weighted average of the likeliest state and rate combination for every node and tip for each model in the set, using the marginal probability as the weights, which were then averaged across all models using the Akaike weights. All analyses were carried out in hisse.
The best model, based on Akaike weights, was a relatively simple HiSSE model with regards to the number of free parameters it contained (Table 2). The model suggests character-dependent diversification with fruit type, where only rates for non-achene+ and achene+ are allowed to be free, and where transitions between state 0B and 1B were disallowed. This model had a pronounced improvement over the set of BiSSE models, where none had an Akaike weight that was greater than 0.001. However, before describing the parameter estimates of the best model, we note that, with a modified tree and character set, the parameter estimates under the BiSSE models were different from those reported by Beaulieu and Donoghue (2013). Specifically, the higher diversification rates estimated for achene lineages (rachene=0.148, support range: [0.121,0.161]) compared to non-achene lineages (rnon-achene=0.065, support range: [0.0498,0.083]) were indeed significant based on a sampling of points falling within 2lnL units away from the MLE. The parameters estimated under the HiSSE model, on the other hand, suggest a more nuanced interpretation of this result. The higher diversification rates of clades bearing achenes as a whole is likely due to a hidden state nested within some of these lineages that is associated with exceptionally high diversification rates (rachene+=0.199, support region: [0.179,0.221]). In fact, the model suggests that achene lineages not associated with the high diversification hidden state have a diversification rate that is identical to the non-achene diversification rate (rnon-achene-= rachene-=0.059, support range: []0.049,0.068]). Non-achene lineages associated with the high diversification hidden state also show elevated diversification rates (rnon-achene-=0.158, support region: [0.138,0.185]), relative to the rate of the non-achene state with the other hidden state, suggesting strong rate heterogeneity even in Dipsidae lineages that bear other fruit types.
Character reconstructions identified two transitions to the hidden fast state in achene-lineages, and thus a higher diversification rate: one shift occurred along the stem leading to crown Dipsacaceae and the other occurred along the stem leading to “core Valerianaceae” (the most inclusive clade that excludes Patrinia, Nardostachys, and Valeriana celtica)(Fig. 6). It is important to note that in the case of non-achene lineages, the model identified four shifts to the hidden fast state – one at the base of Caprifolieae (Lonicera, Symphoricarpus, Leycesteria, and Triosteum), and three within Viburnum (Fig. 6). The several shifts detected in Viburnum are noteworthy in that they correspond almost exactly with the inferred shifts detected in a more focused study of the genus that applied various character-independent models of diversification (Spriggs et al. 2015).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In regards to achene lineages, the general location of the inferred shifts is intriguing, as they appear to coincide with specific clades that exhibit specialized structures related to achene dispersal. In the Dipsacaceae, for example, there is tremendous diversity in the shape of the “epicalyx”, a tubular structure that subtends the calyx and encloses the ovary (Donoghue et al. 2003; Carlson et al. 2009), which is often associated with elaborated structures (e.g., “wings”, “pappus-like” bristles) that accompany their achene fruits. Interestingly, many of these same general forms are observed throughout the core Valerianaceae, although they arise from modifications to the calyx (Donoghue et al. 2003; Jacobs et al. 2010). While the significance of these structures is thought to improve protection, germination, and dispersal of the seed, we emphasize that, at this stage, it is difficult to confidently rule out other important factors, such important biogeographic movements due to increased dispersal abilities (i.e., “key opportunities” sensu Moore and Donoghue 2007), or even purely genetic changes, such as gene and genome duplications (Hildago et al. 2010; Carlson et al. 2011). But, we can at least confidently conclude that the achene by itself is likely not a strong correlate of diversity patterns within the Dipsidae clade.
Discussion
Progress in biology comes from confronting reality with our hypotheses and either confirming that our view of the world is correct, or, more excitingly, finding out that we still have a lot left to discover. With studies of diversification, we have mostly been limited to doing the former – we have an idea about a trait that may affect diversification rates based on intuition about its potential effect (e.g., an achene might allow greater dispersal, and thus easier colonization of new habitats to form new species) as well as some knowledge of its distribution (e.g., some very large plant clades have achenes) and then run an analysis. Typical outcomes are yes, there is a difference in diversification in the way we expected, or there is no difference but maybe we just lack the necessary power. In any case, chances are we are at least vaguely correct that the trait we think credibly has a mechanism for increasing diversification rate actually has an effect (at least once there is enough power), or, less compellingly, clades we identify for such a test from eyeballing the data return a significant result despite no underlying reality.
Surprise is a necessary part of discovery that, to put it bluntly, has been relatively lacking in trait-dependent diversification studies until now. With HiSSE we can still test our intuitions about a particular character, but we can also discover that rates are driven by some unknown and unmeasured character state, allowing the data to help us generate new hypotheses – Is the diversification rate correlated with the achene, or is the achene simply a necessary precursor to some other trait that is more likely to be driving diversification? This lets us go from a scenario where we simply reject trivial nulls, such as whether diversification rates of clades with and without some focal trait are precisely equal, to being potentially surprised by the results – No, it is not the achene per se, but it is something else nested within these particular clades in addition to the achene fruit type.
Currently, diversification models are divided between those that look at one or more focal traits only, integrating over any other factors (e.g., BiSSE, Maddison et al. 2007; BiSSE-ness, Magnuson-Ford and Otto, 2012; ClaSSE, Goldberg and Igic, 2012; sister group comparisons, Mitter et al. 1988), and those that fit rates to trees but ignore trait information altogether (e.g., MEDUSA, Alfaro et al. 2009; BAMM, Rabosky 2014). Our HiSSE model spans this range. If the true model is strictly trait-dependent diversification, it can detect this (Fig. 1-5), as a BiSSE analysis would. If the true model is rates varying due to some other unexamined factor (a physical trait, a property of the environment, etc.) HiSSE recovers this too, as in the case of achene evolution in the Dipsidae clade (Fig. 6). Uniquely, HiSSE can also give an intermediate answer where a focal trait explains some but not all of the diversification difference.
The HiSSE framework also provides a solution to some of the recent important criticisms levied against state speciation and extinction models (Maddison and FitzJohn 2014, Rabosky and Goldberg 2015). Specifically, our method no longer requires the assumption that focal character states are associated with diversification rate differences. Instead, it allows this assumption to be explored as part of a more flexible overall model, as opposed to relying on separate tests for uncovering character-dependent and character-independent rates of diversification (e.g., Beaulieu and Donoghue 2013; Weber and Agrawal 2014; Spriggs et al. 2015). Including our null models of trait-independent diversification in a set of alternative trait-dependent models should also alleviate concerns of spurious assignments of diversification rate differences between observed character states in cases where trees are evolving separate from the focal trait (c.f., Rabosky and Goldberg 2015). These character-independent diversification models are designed specifically to be as complex as competing BiSSE or HiSSE models, which provides a fairer comparison over more trivial “equal-rate” nulls.
We do, however, highlight one important statistical concern in which HiSSE requires significant caution in its use. This involves its indifference to number of changes (c.f., Maddison and FitzJohn 2014). As with BiSSE, we should find it more credible that a particular character state enhances diversification rates if we see a rate increase in each of the 10 times it evolves than if it evolved just once but had the same magnitude of rate increase. A good solution to this problem has not yet been proposed, and we urge a healthy skepticism of any result based on a trait that has evolved only a few times.
There are other practical concerns in empirical applications of the HiSSE model. While it could be used over a set of trees (i.e., bootstrap or Bayesian post-burnin tree samples), the model assumes that the branch lengths, topology, and states are known without error. Certain kinds of phylogenetic errors, such as terminal branch lengths that are too long (as may occur with sequencing errors in the data used to make the tree) can result in particular biases in estimates of speciation and/or extinction (also see Beaulieu and O'Meara 2015). Similarly, if one clade were reconstructed to be younger than it actually is, due to a substitution rate slowdown caused by some other trait (e.g., life-history; Smith and Donoghue 2008), it could be interpreted as having a faster diversification rate, perhaps even inferred to have its own hidden state. For trees that come from Bayesian dating analyses, whether a birth-death or Yule prior was used may affect results unless the data is strong enough to overwhelm this (Condamine et al. 2015). Future simulation studies will focus on better understanding the impact that these and other branch length error scenarios can have on the interpretation and estimation of various model parameters. Also, we point out that the HiSSE model assumes discrete characters, whether they be hidden or observed, but it could be that a continuous parameter is the cause of a diversification rate difference (e.g., perhaps extinction risk varies inversely with mean of the dispersal kernel). However, this may only enter the model as an unseen discrete character, perhaps corresponding to low and high values of the continuous character.
Our HiSSE model is part of a long tradition in comparative methods of identifying, and then fixing, perceived shortcomings. For instance, Felsenstein (1985) pointed out the pitfalls of treating species values as independent data points and provided two alternatives (i.e., independent contrasts and dividing a tree into pairs of tips) to address those issues. Maddison (2006) realized the issue of not accounting for diversification in transition-based methods (i.e., Pagel 1994) and not accounting for differential transitions in diversification models, which led to the development of state-dependent speciation and extinction models (Maddison et al. 2007; FitzJohn et al. 2009). Recently, Rabosky and Goldberg (2015) pointed out a serious problem with interpretations in state speciation and extinction analyses in general, and our work largely addresses these concerns. We caution users that it is important to keep a perspective: all methods have flaws, and all will fail given a strong enough violation of their underlying assumptions. For example, it appears difficult for HiSSE to adequately estimate different transition rates when the model assumes any number of hidden states, and so many estimates will be biased. Even with the increasing efforts to test new methods (in our case, over 17,000 computer-days were devoted to conducting simulations and analyses) there will be flaws that may have gone undetected. We urge skepticism towards all models, but also skepticism towards statements of fatal flaws in some models while leaving newer, competing models relatively untested.
There is no question that state-dependent speciation and extinction models are an important advancement for understanding characters' impact on diversification patterns. They have greatly improved statistical power over older, simpler sister-clade comparisons, and the explicit inference of differences in speciation and extinction has the potential for a much more fine-grained analysis of diversification. But, in a way, these models have also allowed us to retreat to the old comforts of reducing complex organisms into units of single, independently evolving characters, and offering adaptive interpretations to each (c.f., Gould and Lewontin 1979). To be fair, of course, it is unlikely that any trait of great interest to biologists has exactly zero effect on speciation and/or extinction rates, but it is certainly unlikely that this trait acts in isolation. Thus, we hope HiSSE is viewed as a step away from this line of thinking, as we no longer have to necessarily focus analyses, or even interpret the results, by reference to the focal trait by itself, but can instead estimate how important it is as a component of diversification overall. It is in this way that analyses focused on “hidden” factors promoting diversification will afford us a more refined understanding of why certain clades become extraordinarily diverse, while still allowing us to examine our hypotheses about effects of observed traits.
Acknowledgements
We thank Nathan Jackson, Nick Matzke, Kathryn Massana, Chuck Bell, and Andrew Leslie for helpful discussions. Rich FitzJohn and two anonymous reviewers provided very useful comments on the manuscript. We are deeply indebted to Tanja Stadler for her suggestion to consider null models. We also thank Jeffrey Oliver and Elizabeth Spriggs for feedback on the method implementation. JMB would like to thank Michael Donoghue for wonderful discussions over the years regarding some of the concepts described here. Support for JMB has been provided by the National Institute for Mathematical and Biological Synthesis, an Institute sponsored by the National Science Foundation, the U.S. Department of Homeland Security, and the U.S. Department of Agriculture through NSF Award #EF-0832858, with additional support from The University of Tennessee, Knoxville.
References




