

Abstract
While forming and updating beliefs about future life outcomes, people tend to consider good news and to disregard bad news. This tendency is supposed to support the optimism bias. Whether this learning bias is specific to “high-level” abstract belief update or a particular expression of a more general “low-level” reinforcement learning process is unknown. Here we report evidence in favor of the second hypothesis. In a simple instrumental learning task, participants incorporated better-than-expected outcomes at a higher rate compared to worse-than-expected ones. In addition, functional imaging indicated that inter-individual difference in the expression of optimistic update corresponds to enhanced prediction error signaling in the reward circuitry. Our results constitute a new step in the understanding of the genesis of optimism bias at the neurocomputational level.
Introduction
"It is the peculiar and perpetual error of the human understanding to be more moved and excited by affirmatives than negatives; whereas it ought properly to hold itself indifferently disposed towards both alike" (p36.)*
People typically overestimate the likelihood of positive events and underestimate the likelihood of negative events. This cognitive trait in (healthy) humans is known as the optimism bias and has been repeatedly evidenced in many different guises and populations1–3 such as students projecting their salary after graduation4, women estimating their risk of getting breast cancer5 or heavy smokers assessing their risk of premature mortality6. One mechanism hypothesized to underlie this phenomenon is an asymmetry in belief updating, colloquially referred to as “the good news / bad news effect”7,8. Indeed, preferentially revising one’s beliefs when provided with favorable compared to unfavorable information constitutes a learning bias which could, in principle, generates and sustains an overestimation of the likelihood of desired events and a concomitant underestimation of the likelihood of undesired events (optimism bias)9.
This good news/bad news effect has recently been demonstrated in the case where outcomes are hypothetical future prospects associated with a strong a priori desirability or undesirability (estimation of post-graduation salary or the probability of getting cancer)4,5. In this experimental context, belief formation triggers complex interactions between episodic, affective and executive cognitive functions7,8,10, and belief updating relies on a learning process involving abstract probabilistic information7,11–13. However, it remains unclear whether this learning asymmetry also applies to immediate reinforcement events driving instrumental learning directed to affectively neutral options (i.e. with no a priori desirability or undesirability). If an asymmetric update is also found in a task involving neutral items and direct feedback, then the good news/bad news effect could be considered as a specific – cognitive – manifestation of a general reinforcement learning asymmetry. If the asymmetry were not found at the basic reinforcement learning level, this would mean that the asymmetry is specific to abstract belief updating, and this would require a theory explaining this discrepancy.
To arbitrate between these two alternative hypotheses, we fitted instrumental behavior of subjects performing a simple two-armed bandit task, involving neutral stimuli and actual and immediate monetary outcomes, with two learning models. The first model (a standard RL algorithm) confounded individual learning rates for positive and negative feedback and the second one differentiated them, potentially accounting for learning asymmetries.
Over two experiments, we found that subjects’ behavior was better explained by the asymmetric model, with an overall difference in learning rates consistent with preferential learning from positive, compared to negative, prediction errors.
Previous studies suggest that the good news/bad news effect is highly variable across subjects11. Behavioral differences in optimistic beliefs and optimistic update have been shown to be reflected by differences in brain activation in the prefrontal cortex7. However, the question remains whether or not and how such inter-individual behavioral differences are related to the inter-individual neural differences in the extensively documented reward circuitry14. Our imaging results indicate that the inter-individual variability in the tendency in optimistic learning correlates with prediction error-related signals in the reward system, including the striatum and the ventro-medial prefrontal cortex (vmPFC).
Results
Behavioral task and dependent variables
Healthy subjects performed a probabilistic instrumental learning task with monetary feedback, previously used in brain imaging, pharmacological and clinical studies15–17 (Fig. 1A). In this task, options (abstract cues) were presented in fixed pairs (i.e. conditions). In all conditions each cue was associated with a stationary probability of reward. In asymmetric conditions, the two reward probabilities differed between cues (25/75%). From asymmetric conditions we extracted the rate of “correct” response (selection of the best option) as a measure of performance (Fig. 1B, left). In symmetric conditions, both cues had the same reward probabilities (25/25% or 75/75%), such that there was no intrinsic “correct response”. In symmetric conditions we extracted for each subject and each symmetric pair, a “preferred response” rate, defined as the choice rate of the option most frequently selected by a given subject (i.e. by definition in more than 50% of trials). The preferred response rate, especially in the 25/25% condition, should be taken as a measure of the tendency to overestimate the value of one instrumental cue compared to the other, in absence of actual outcome-based evidence. (Fig. 1B, right). In a first experiment (N=50) that subjects performed while being fMRI scanned, the task involved reward (+0.5€) and reward omission (0.0€), as the best and worst outcome respectively. In a second purely behavioral experiment (N=35), the task involved reward (+0.5€) and punishment (-0.5€), as the best and worst outcome respectively. All the results presented in the main text concern Experiment 1, except those of the last section entitled "Optimistic reinforcement learning is robust across different outcome valences". Detailed behavioral and computational analyses concerning Experiment 2 are presented in Supplementary Materials.

(A) Task’s conditions and contingencies. Subjects selected between left and right symbols. Each symbol was associated with a stationary probability (p = 0.25 or 0.75) of winning 0.50€ and a reciprocal probability (1 – p) of getting nothing (first experiment) or losing 0.50€ (second experiment). In two conditions (rightmost column) the reward probability was the same for both symbols (“symmetric” conditions) and in two other conditions (leftmost column) the reward probability was different across symbols (“asymmetric” conditions). Note that the assignment between symbols conditions was randomized across subjects. (B) Dependent variables. In the leftmost panel, the histograms show the correct choice rate (i.e. choices directed toward the most rewarding stimulus in the asymmetric conditions). In the rightmost panel the histograms show the preferred option choice rate (i.e. the option chosen by subjects in more than 50% of the trials; this measure is relevant only in the symmetric conditions, where there is no intrinsic correct response). Bars indicate the mean and error bars indicate the SEM. Data are taken from both experiments (N=85).
Computational models
We fitted the behavioral data with two reinforcement-learning models18. The “reference” model was represented by a standard Rescorla-Wagner model 19, thereafter referred to as RW model. The RW model learns option values by minimizing reward prediction errors. It uses a single learning rate (alpha: α) to learn from positive and negative prediction errors. The “target” model was represented by a modified version of the RW model, thereafter referred to as RW± model. In the RW± model, learning from positive and negative prediction errors is governed by different learning rates (alpha plus: α+ and alpha minus: α- respectively). For α+ > α- the RW± model instantiates optimistic reinforcement learning (i.e. the good news/bad news effect); for α+ = α-, the RW± instantiates unbiased reinforcement learning, just as in the RW model (the RW model is thus nested in the RW± model); finally, for α+ < α- the RW± instantiates pessimistic reinforcement learning. In both models the choices are taken by feeding the option values into a softmax decision rule, whose exploration/exploitation trade-off is governed by a “temperature” parameter (β).
Model comparison and model parameters analysis
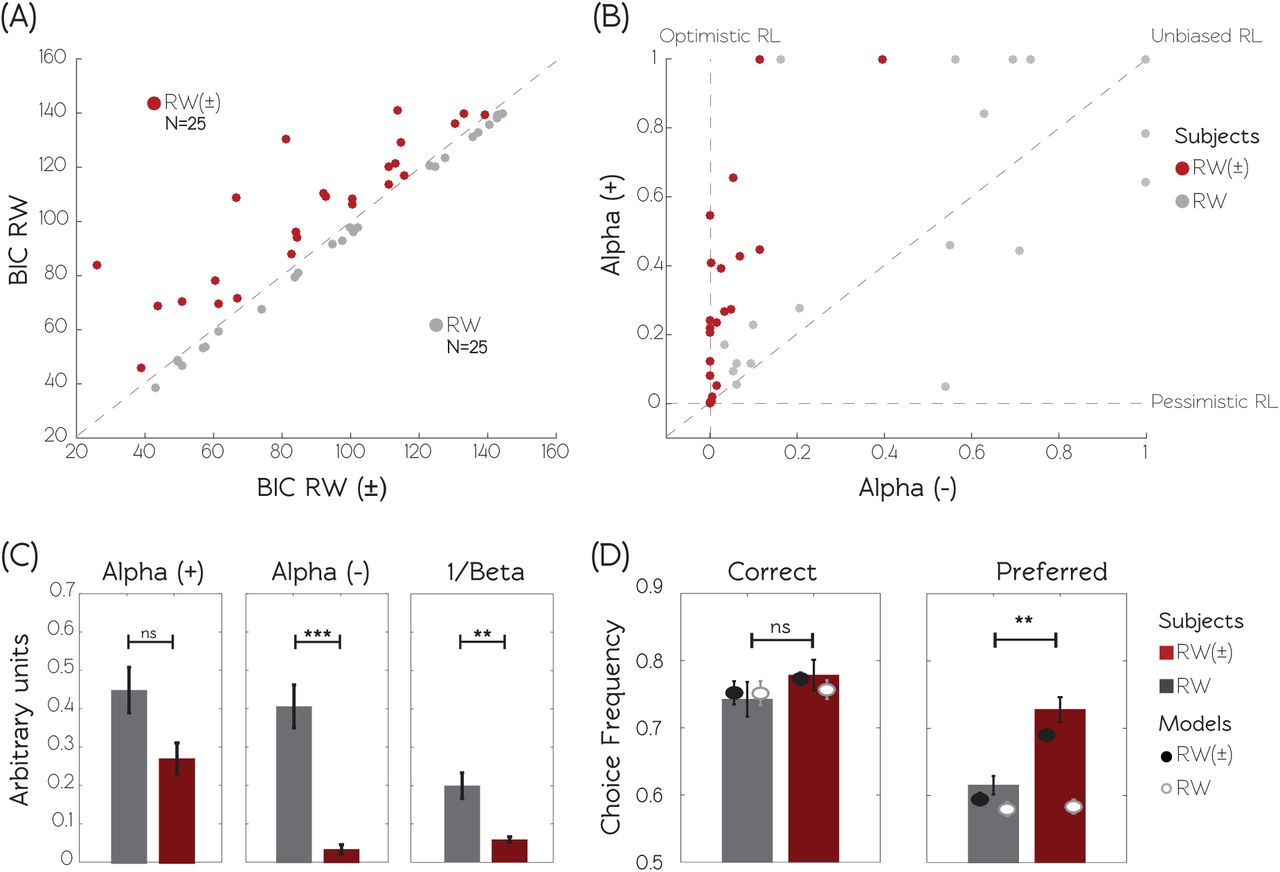
We implemented Bayesian model comparison to establish which model better accounted for the behavioral data. For each model we estimated the optimal free parameters by maximizing the likelihood of the participants’ choices, given the models and sets of parameters. For each model and each subject, we calculated the Bayesian Information Criterion (BIC) by penalizing the maximum likelihood with the number of free parameters in the model. Random-effects BIC analysis indicated that the RW± model better explains the behavioral data compared to the RW model (BICRW=99.4±4.4, BICRW±=93.6±4.7; t(49)= 2.9, p=0.006, paired t-test), even accounting for its additional degree of freedom. A similar result was obtained when calculating the model exceedance probability using the BIC as an approximation of the model evidence20 (Table 1). RW± being the best fitting model we compared the learning rates fitted for positive (good news: α+ and negative (bad news: α- prediction errors. We found α+ significantly higher compared to α- (α+=0.36±0.05, α-=0.22±0.05, t(49)= 3.8, p<0.001 paired t-test). To summarize, model comparison indicated that, in our simple instrumental learning task, the best fitting model is the model with different learning rates for learning from positive and negative predictions errors (RW±). Crucially, learning rates comparison indicated that instrumental values are preferentially updated following positive prediction errors, which is consistent with an optimistic bias operating when learning from immediate feedback (optimistic reinforcement learning).
The table summarizes for each model its fitting performances and its average parameters: LLmax: maximal Log Likelihood; BIC: Bayesian Information Criterion (computed from LLmax); XP: exceedance probability; MF: model Frequency; α: learning rate for both positive and negative prediction errors (RW model); α+: learning rate for positive prediction errors; α-: average learning rate for negative prediction errors (RW± model); 1/β: average inverse of model temperature. Data are expressed as mean ± s.e.m. *P<0.01 comparing between the two models. #P<0.001 comparing between the two learning rates.
Computational phenotyping
To categorize subjects, we computed for each individual the between-model BIC difference (∆BIC=BICRW - BICRW±) (see Methods). The ∆BIC quantifies at the individual level the goodness of fit improvement moving from the RW to the RW± model, or in other terms the fit improvement assuming different learning rates for positive and negative prediction errors. Subjects with a negative ∆BIC (N=25, in the first experiment) are subjects whose behavior is better explained by the RW model and therefore learn in an unbiased manner (thereafter refereed as RW subjects) (Fig. 2A). Subjects with a positive ∆BIC (N=25, in the first experiment) are subjects whose behavior is better explained by asymmetric learning (thereafter refereed as RW± subjects).

(A) Model comparison. The graphic displays the scatter plot of the BIC calculated for the RW model as a function of the BIC calculated for the RW± model. Smaller BIC values indicate better fits. Subjects are clustered in two populations according to the BIC difference (∆BIC = BICRW - BICRW±) between the two models. RW± subjects (displayed in red) are characterized by a positive ∆BIC, indicating that the RW± model better explains their behavior. RW subjects (displayed in grey) are characterized by a negative ∆BIC, indicating that the RW model better explains their behavior. (B) Model parameters. The graphic displays the scatter plot of the learning rate following positive prediction errors (α+) as a function of the learning rate following negative prediction errors (α-), obtained from the RW± model. “Standard” reinforcement learners are characterized by similar learning rates for both types of prediction errors. “Optimistic” learners are characterized by a bigger learning rate for positive compared to negative prediction errors. “Pessimistic” learners are characterized by the opposite pattern. C The histograms show the RW± model free parameters (the learning rates + and - and the inverse temperature 1/β) as function of the subjects’ populations. D Actual and simulated choice rates. Histograms represent the observed and dots represent the model simulations of choices for both populations and both models, respectively for correct option (extracted from asymmetric condition), and from preferred option (extracted from the symmetrical condition 25/25%, see Fig. 1A). Model simulations are obtained using the individual best fitting free parameters. *p<0.05, ** p<0.01, ***p<0.001, two-sample two-sided t-test. Data are taken from the first experiment (N=50).
To test this hypothesis, learning rates fitted with the RW± model were entered in a two-way ANOVA with group (RW and RW±) and learning rates type (α+ and α- as respectively between- and within-subjects factors. The ANOVA showed a main effect of learning rate type (F(1,48)=16.5, P<0.001) with α+ higher than α-. We also found a main effect of group (F(1,48)=10.48, P=0.002) and a significant group x learning type interaction (F(1,48)= 7.8, p=0.007). Post-hoc tests revealed that average learning rates for positive prediction errors were not different among the two groups, α+RW=0.45 ± 0.08 and α+RW±= 0.27 ± 0.06 (t(48) = 1.7, p=0.086, two-sample t-test). On the contrary, average learning rates for negative prediction errors were significantly different between groups, α-RW= 0.41 ± 0.08 and α- RW±= 0.04 ± 0.02 (t(48)= 4.6, p<0.001, two-sample t-test). In addition, an asymmetry in learning rates was detected within the RW± group, where α+ was higher than α- (t(24)=5.1, p<0.001, paired t-test) but not within RW group (t(24)=0.9, p=0.399, paired t-test). Thus, RW± subjects specifically drove the learning rates asymmetry found in the whole population. On the other side the RW subjects display “unbiased” (as opposed to “optimistic”) instrumental learning (Fig. 2B and 2C).
Interestingly, the exploration rate (captured by the 1/β, “temperature” parameter) was also found to be significantly different between the two groups of subject, 1/βRW=0.20 ± 0.05 and 1/βRW±=0.06 ± 0.01. (t(48)= 2.9, p=0.006, two-sample t-test). Importantly, the maximum likelihood of reference model (RW) was not different between the two groups of subjects, indicating similar baseline quality of fit (94.94±5.00 and 103.91±3.72 for RW and RW± subjects respectively, t(48)= -1.0, p=0.314, two-sample t-test). Accordingly the difference in the exploration rate parameter cannot be explained by difference in the quality of fit (i.e. noisiness of the data). This suggests that optimistic reinforcement learning, observed in RW± subjects, is also associated with exploitative, as opposite to explorative, behavior (Fig. 2C). Importantly, model simulations-based assessment of parameters recovery indicated that the two effects (learning rate asymmetry and lower exploration/exploitation trade-off) can be independently and correctly retrieved, ruling out the possibility that this twofold result is an artifact of the parameter optimization procedure (see Supplementary Materials and Fig. S7). To summarize, RW± subjects tend to weight more positive feedback and, as a consequence, to exploit more consistently the previously rewarded options (optimism).
Behavioral signature distinguishing optimistic from unbiased subjects
In order to analyze the behavioral consequences of optimistic, as opposed to unbiased, learning and to confirm our model-based results with model-free behavioral observations, we compared the task’s dependent variables between our two groups of subjects (Fig. 2D, Table 2). Correct response rate did not differ between groups (t(48)=-0.7323, p=0.467, two-sample t-tests). However, the preferred response rate in the 25/25% condition was significantly higher for RW± group in comparison to RW group (t(48)= -3.4, p=0.001, two-sample t-test). Note that the same analysis performed on the 75/75% condition provided similar results (t(48)= -2.66, p=0.01, two-sample t-test).
The table summarizes for each experiment and each group of subjects, behavioral and simulated dependent variables: both real and simulated Correct Response in asymmetric conditions and both real and simulated Preferred Response in 25/25% condition. Data are expressed as mean ± s.e.m (in percentage). *P<0.01 two sample t-test.
In order to validate the ability of RW± model to capture this difference, we performed simulations using both models and submitted them to the same statistical analysis as actual choices (Fig. 2D). The RW± model simulated preferred response rate was significantly higher for RW± group compared to the RW group (25/25%: t(48)= -5.4496, p<0.001; 75/75%: t(48)=-2.2670, p= 0.028; two-sample t-tests), which replicated human behavior. However, the simulated preferred response rates from the RW model were similar in the two groups (t(48)=0.566, p=0.566; 75/75%: t(48)=0.7448, p=0.4600; two-sample t-test), which departed from our observations in real subjects. This effect was particularly interesting in poorly rewarding environment (25/25%), where optimistic subjects tend to overestimate the value of one of the two options (Fig. S1). Finally, the preferred response rate in the symmetric conditions significantly correlated with both the computational features distinguishing RW and RW± subjects (normalized learning rates asymmetry (α+ - α-) / (α+ + α-): R=-0.475, P<0.001; choice randomness 1/β: R=-0.630, P<0.001). The preferred response rate thus provides a model-free signature of optimistic reinforcement learning that is congruent with our model simulation analysis: the preferred response rate was higher in RW± group in comparison to RW group and only simulations realized with RW± model were able to replicate this pattern of responses.
fMRI signatures distinguishing optimistic from unbiased subjects
To investigate the neural correlates of the computational differences between RW± and RW subjects, we analyzed the brain activity both at the decision and outcome moments, using functional Magnetic Resonance Imagining (fMRI) and a model-based fMRI approach21. We devised a general linear model in which we modeled as separated events the choice and the outcome onset, each modulated by different parametric modulators. In a given trial, the choice onset was modulated by the chosen option Q-value (QChosen(t)), and the outcome onset was modulated by the reward prediction error (δ(t)). Concerning the choice onset, we found a neural network including the dmPFC and anterior Insulae negatively encoding QChosen(t), (PFWE<0.05 with a minimum of 60 continuous voxels) (Fig. 3A and 3B) (Table 3). We then tested for between-group differences within these two regions and found no significant difference (dmPFC: t(48)=0.0985, P=0.9220; Insulae t(48)=-0.0190, P=0.9849; two-sample t-tests) (Fig. 3C). Concerning the outcome onset we found a neural network including the striatum and vmPFC positively encoding δ(t), (PFWE<0.05 with a minimum of 60 continuous voxels) (Fig. 3A and 3B) (Table3). We then tested for between-group differences within these two regions and found significant differences (Striatum: t(48)=-3.2769, P=0.0020; vmPFC t(48)=-2.2590, P=0.0285; two-sample t-tests) (Fig. 3C). It therefore seems that the behavioral difference we observed between RW and RW± subjects finds its counterpart in a differential outcome-related signal in the ventral striatum. Within the regions displaying a between-group difference, we looked for correlation with the two computational features distinguishing optimistic from unbiased subjects. Interestingly, we found a positive and significant correlation between the striatal and vmPFC δ(t)-related activity and the normalized difference between learning rates (Striatum: R=0.4324, p=0.0017; vmPFC: R=0.3238,p=0.0218), but no significant difference between the same activity and 1/β (Striatum: R=-0.130, p=0.366; vmPFC: R=-0.272,p=0.3665), which suggests a specific link between this neural signature and the optimistic update.

(A) and (B) Choice correlation. Statistical parametric maps of BOLD signal negatively correlating with the QChosen(t) at the choice onset. Areas colored in gray-to-black gradient on the axial glass brain and red-to-white gradient on the coronal slice show a significant effect (p<0.001 corrected). (C) Inter-individual differences. Histogram shows QChosen(t)-related signal change in DMPFC at the time of choice onset for both populations. Bars indicate the mean and error bars indicate the SEM. *p<0.05, unpaired t-tests. Data are taken from the first experiment (N=50). [x, y, z] coordinates are given in the MNI space (D) and (F) Outcome correlation. Statistical parametric maps of BOLD signal positively correlating with δ(t) at the outcome onset. Areas colored in gray-to-black gradient on the axial glass brain and red-to-white gradient on the coronal slice show a significant effect (p<0.001 corrected). (F) Inter-individual differences. Histogram shows δ(t)-related signal change in the striatum at the time of reward onset for both populations. Bars indicate the mean and error bars indicate the SEM. *p<0.05, **p<0.01 unpaired t-tests. Data are taken from the first experiment (N=50). [x, y, z] coordinates are given in the MNI space
FWE<0.05 whole brain corrected and 60 minimum voxels.
Optimistic reinforcement learning is robust across different outcome valences
In the first experiment, getting nothing (0.0€) was the worst possible outcome. It could be argued that optimistic reinforcement learning (i.e. greater learning rate for positive than negative prediction errors: α+>α-) is dependent on the low negative motivational salience attributed to a neutral outcome and would not resist if negative prediction errors are accompanied by actual monetary losses. In order to confirm the independence of our results from outcome valence, in the second experiment the worst possible outcome was represented by a monetary loss (-0.5€), instead of reward omission (0.0€) as in the first experiment.
First, the second experiment replicated the model comparison result of the first experiment. Group-level BIC analysis indicated that the RW± model again better explains the behavioral data compared to the RW model (BICRW=97.6±5.9, BICRW±=89.8±6.0), even accounting for its additional degree of freedom (t(34)= 2.6414, p=0.0124, paired t-test (Table 1 and Fig. S2).
To confirm that the asymmetry of learning rates is not a particularity of our first experiment, in which the worst possible outcome (“bad news”) was represented by a reward omission, we performed a two-way ANOVA with Experiment (1 and 2) as between subject factor and learning rate type (α+ and α-) as within-subject factor. The analysis showed no significant effect of experiment (F(1,83)=0.077, P=0.782) and no significant valence x experiment interaction (F(1,83)=3.01, P=0.0864) indicating that the two experiments were comparable, and, if anything, the effect size was bigger in presence of punishments. We found indeed a significant main effect of valence (F(1,83)=29.03, P<0.001) on learning rates. Accordingly, post-hoc test revealed that α- was significantly smaller than α+ also in the second experiment (t(34)=3.8639, p<0.001 paired t-test) (Fig. S3A). These results confirm that optimistic reinforcement learning is not particular to situations involving only rewards but it is still maintained in situations involving both rewards and punishments.
Discussion
We found that, in a simple instrumental learning task involving neutral visual stimuli associated to actual monetary rewards, participants preferentially updated option values following better-than-expected, compared to worse-than-expected, outcomes. This learning asymmetry was replicated in two experiments and proved to be robust across different conditions.
Our results support the hypothesis that the good news/bad news stands as a core psychological process generating and maintaining unrealistic optimism8. In addition, our study has the originality of showing that this effect is not specific to probabilistic belief updating, and that the good news/bad news effect can parsimoniously be considered as an amplification of a primary instrumental learning asymmetry. In other terms, following nomenclature recently proposed by Sharot and Garrett, we found that asymmetric update applies to “prediction errors” and not only to “estimation errors”, as reported in previous studies9. Recently, an animated debate emerged concerning whether or not the good news/bad news effect is an artifact due to the fact that in the original task the prospects were very rare life events22,23. Our results, by showing that the learning asymmetry persists for abstract cues (as opposite to rare events) associated with not extremely low (nor extremely high) reward probabilities, significantly adds to this debate.
The asymmetric model (RW±) included two different learning rates following positive and negative prediction errors and we found the “positive” learning rate higher compared to the “negative” one24,25. A point, which is worth noting, is that optimism seems not to come from overemphasizing gains, but underestimating losses. Note the fact that the learning asymmetry was replicated when the negative prediction errors (i.e. “bad news) were associated with both reward omissions (Experiment 1) and monetary punishments (Experiment 2) indicating that our results cannot be interpreted as a consequence of different processing of outcome values26. In other terms the learning asymmetry is not outcome sign-based, but prediction error sign-based.
In principle RW± subjects could have displayed both an optimistic and a pessimistic update, meaning that the ∆BIC is not – a priori – a measure of optimism. However, in the light of our results, this metric was a posteriori associated with the good news/bad news effect at the individual level. Categorizing subjects based on the ∆BIC, instead of the learning rate difference, has the advantage that the learning rate difference can take positive and negative values in RW subjects, but this difference merely only captures noise, because it is not justified by model comparison. Our subject categorization was further supported by unsupervised Gaussian-mixtures analysis, which indicated that 1) two clusters better explained the data compared to one cluster and that 2) the two cluster corresponded to positive and negative ∆BIC respectively. The combination of individual model comparison with clustering techniques may represent a useful practice for computational phenotyping and for investigating inter-individual cognitive differences27.
A higher learning rate for positive compared to negative prediction errors was not the only computational metric distinguishing optimistic from unbiased subjects. In fact, we also found that optimistic subjects had a greater tendency to exploit previously rewarded option, as opposed to unbiased subjects who were more prone to explore both options. Importantly the higher stochasticity of unbiased subjects was associated neither with lower performance in the asymmetrical conditions, nor with a lower baseline quality of fit, as measured by the maximum likelihood. This overexploitation tendency was particularly striking in the symmetrical 25/25% condition, in which both options are poorly rewarding compared to the average task reward rate.
Whereas some previous studies suggest that optimists are more likely to explore and take risks (i.e. entrepreneurs)28, we found an association between optimistic learning and higher propensity to exploit. Indeed, the tendency to ignore negative feedback about chosen options was linked to considering a previously rewarded option better than it is, and hence to stick to this preference. A possible link between optimism and such “conservatism” is not new; it can be dated back to Voltaire’s work “Candide ou l’Optimisme”, where the belief of “living in the best of the possible worlds” was consistently associated with a strong rejection and condemnation of progress and explorative behavior. In the words of the 18th century philosopher:
"Optimism," said Cacambo, "What is that?" "Alas!' replied Candide, "It is the obstinacy of maintaining that everything is best when it is worst"†
Accordingly, optimism bias has been recently recognized as an important psychological factor helping maintain inaction regarding pressing social problems, such as climate changes29.
Recent studies investigated the neural implementation of the good news/bad news effect when analyzed in the context of probabilistic belief updating. At the functional level, decreased belief updating after worse-than-expected information has been associated with a reduced neural activity in the right inferior prefrontal gyrus (IFG)7. Subsequent studies from the same group also showed that boosting dopaminergic function increases the good news/bad news effect and that this bias is correlated with striatal white matter connectivity, suggesting a possible role for the brain reward system13,30. Accordingly a more recent study showed differences in the reward system, including the striatum and the ventromedial prefrontal cortex31. Consistent with these results, we found that reward prediction error encoded in the brain reward network, including the striatum (mostly its ventral parts) and the vmPFC, was higher in optimistic, compared to unbiased, subjects. Replicating previous findings, we also found a neural network, encompassing the dmPFC and the anterior Insula negatively representing chosen option value32,33. When comparing between the two groups we found no difference between optimists and pessimists in this decision-related area 34,35. Our results suggest that at the neural level outcome-related activity discriminates between optimistic and unbiased subjects. Remarkably, by identifying functional differences between the two groups, our imaging data corroborates our model comparison-based classification of subject (computational phenotyping).
An important question is unanswered by our study and remains to be addressed. Whereas our results clearly show an asymmetry in the learning process, we cannot decide whether the learning process itself involves the representational space of values or that of probabilities. This question is related to the broader debate whether the reinforcement or the Bayesian learning framework better captures learning and decision-making: two views that have been hard to disentangle, because of largely overlapping predictions, both at the behavioral and neural levels36–38. Our results cannot decide whether this optimistic bias is a valuation or a confirmation bias. In other terms, do subjects preferentially learn from positive outcome because of its valence or because a positive outcome “confirms” the choice subjects just made? Future studies, decoupling valence from choice, are required to disentangle these two hypotheses.
It is worth noting that whereas some previous studies reported similar findings39,40, another one reported the opposite pattern41. The difference between the aforementioned study and ours might rely on the fact that the former involved Pavlovian conditioning. It may therefore be argued that optimistic reinforcement learning is specific to instrumental (as opposite to classical) conditioning.
A legitimate question is why such learning bias survived in the course of evolution? An obvious answer to this question is that being (unrealistically) optimistic is and/or has been, at least in certain conditions, adaptive, meaning that it confers an advantage. Consistent with this idea, in everyday life dispositional optimism42 has been linked for instance to better global emotional well-being, interpersonal relationship or physical health. Optimists are less likely to develop coronary heart disease43, have broader social network44 and are less subject to distress when facing adversity42. Over-confidence in one own performance has been shown to be associated with higher performances in competitive games45. Such advantages of dispositional optimism could explain, at least in part, the pervasiveness of an optimistic bias in human. Concerning the specific context of optimistic reinforcement learning a recent paper46 by Cazé and al. showed that in certain conditions (low rewarding environments), an agent learning asymmetrically in an optimistic manner (i.e. with a higher learning rate for positive than for negative feedback) objectively outperforms another “unbiased” agent in a simple probabilistic learning task. Thus, before any social, well-being or health consideration, it is normatively advantageous (in certain contingencies) to take more into account positive than negative feedback. Thus a possible explanation for an asymmetric learning system is that the conditions identified by Cazé et al. closely resemble to the statistics of the natural environment that shaped the evolution of our learning system.
Finally, when reasoning about the adaptive value of optimism, a crucial point to take into account is the significant inter-individual variability of unrealistic optimism7,11–13. As social animals, humans face both private and collective decision-making problems47. An intriguing possibility is that multiple “sub-optimal” reinforcement learning strategies are maintained in the natural population to ensure an “optimal” learning repertoire, flexible enough to solve at the group-level the value learning and exploration-exploitation tradeoff48. This hypothesis needs to be formally addressed using evolutionary simulations.
To conclude, our findings shed new light on the nature of the good news/bad news effect and therefore on the mechanistic origins of unrealistic optimism. We suggest that the optimistic learning is not specific to “high-level” belief updating but a particular consequence of a more general “low-level” instrumental learning asymmetry, which is associated to enhanced prediction error encoding in the brain reward system.
Materials and Methods
Subjects
The first dataset (N=50) served as a cohort of healthy control subjects in a previous clinical neuroimaging study15. The second dataset involved the recruitment of new subjects (N=35). The local ethics committees approved both experiments. All subjects gave written informed consent before inclusion in the study and the study was carried out in accordance with the declaration of Helsinki (1964, revised 2013). In both studies the inclusion criteria were being older than 18 years and having no history of neurologic or psychiatric disorders. In experiments 1 and 2, men / women ratios were 27/23 and 20/15 respectively and the age means 27.1 ± 1.3 and 23.5 ± 0.7 respectively (expressed as mean ± S.E.M). In the first experiment subjects believed that they would be playing for real money, the final payoff was rounded up to a fixed amount of 80€ for every participant. In the second experiment subjects were paid the exact amount of money earned in the learning task, plus a fixed amount (average payoff 15.7±7.6€).
Behavioral task and analyses
Subjects performed a probabilistic instrumental learning task described previously16 (Fig. 1A). Briefly, the task involved choosing between two cues that were associated with stationary reward probability (25% or 75%). There were 4 pairs of cues, randomly constituted and assigned to the 4 possible combinations of probabilities (25/25%, 25/75%, 75/25%, and 75/75%). Each pair of cues was presented 24 times, each trial lasted in average 7000ms. Subjects were encouraged to accumulate as much money as possible and were informed that some cues would result in a win more often than others (the instructions have been published in appendix of the original study16). Subjects were given no explicit information regarding reward probabilities, which they had to learn through trial and error. The positive outcome reward was winning money (+0.50€); the negative outcome was getting nothing (0.0€) in the first experiment and losing money (-0.50€) in the second experiment. Subjects made their choice by pressing left or right response buttons with a left or right hand finger. Two given cues were always presented together, thus forming a fixed pair (choice context).
Regarding payoff, learning mattered only for pairs with unequal probabilities (75/25% and 25/75%). As dependent variable we extracted the correct response rate in asymmetric conditions (i.e. the left response rate for the 75/25% pair and the right response rate in the 25/75% pair) (Fig. 1B). In symmetrical reward probability conditions, we calculated the so-called “preferred response rate”. The preferred response was defined as the most chosen option, i.e. chosen by the subject more than 50% of the trials. This quantity is therefore, by definition greater than 50%. The analyses focused on the preferred choice rate in the low reward condition (25/25%), where standard models predict greater frequency of negative prediction errors. Behavioral variables were compared within-subjects using paired two-tailed t-test and between-subjects using two-sample two-tailed t-test. Interactions were assessed using ANOVA.
Computational models
We fitted the data with reinforcement learning models. The model space included a standard Rescorla-Wagner model (or Q-learning)18,19 (thereafter referred to as RW) and a modified version of the latter accounting differentially for learning from positive and negative prediction errors (thereafter referred to as RW±)25,40. For each pair of cues, the model estimates the expected values of left and right options, QL and QR, on the basis of individual sequences of choices and outcomes. These Q-values essentially represent the expected reward obtained by taking a particular option in a given context. In the first experiment, that involved only reward and reward omission, Q-values were set at 0.25€ before learning, corresponding to the a priori expectation of 50% chance of winning 0.5€ plus a 50% chance of getting nothing. In the second experiment, which involved reward and punishment, Q-values were set at 0.0€ before learning, corresponding to the a priori expectation of 50% chance of winning 0.5€ plus 50% chance of losing 0.5€. These priors on the initial Q-values are based on the fact that first subjects were explicitly told in the instruction that no symbol was deterministically associated to either of the two possible outcomes and on the fact that subjects were implicitly exposed to the average task outcome during the training session. Further control analyses using post training (“empirical”) initial Q-values, have been performed and are presented in the Supplementary Materials and Fig. S6. After every trial t, the value of the chosen option (e.g., L) was updated according to the following rule:

In the equation, δ(t) was the prediction error, calculated as:
 and R(t) was the reward obtained as an outcome of choosing L at trial t. In other words, the prediction error δ(t) is the difference between the expected reward QL(t) and the actual reward R(t). The reward magnitude R was +0.5 for winning 0.5€, 0 for getting nothing and -0.5 for losing 0.5€. The learning rate, α, is a scaling parameter that adjusts the amplitude of value changes from one trial to the next. Following this rule, option values are increased if the outcome is better than expected and decreased in the opposite case and the amplitude of the update is similar following positive and negative prediction errors.
and R(t) was the reward obtained as an outcome of choosing L at trial t. In other words, the prediction error δ(t) is the difference between the expected reward QL(t) and the actual reward R(t). The reward magnitude R was +0.5 for winning 0.5€, 0 for getting nothing and -0.5 for losing 0.5€. The learning rate, α, is a scaling parameter that adjusts the amplitude of value changes from one trial to the next. Following this rule, option values are increased if the outcome is better than expected and decreased in the opposite case and the amplitude of the update is similar following positive and negative prediction errors.
The modified version of Q-Learning algorithm (RW±) differs from the original one (RW) by its Q values updating rule, as follows:

The learning rate α+ adjusts the amplitude of value changes from one trial to the next when prediction error is positive (when the actual reward R(t) is better than the expected reward QL(t)) and the second learning rate α- does the same when prediction error is negative. Thus the RW± model allows for the amplitude of the update being different, following positive (“good news”) and negative (“bad news”) prediction errors and permits to account for individual differences in the way subjects learn from positive and negative experience. If both learning rates are equivalent, α+ = α-, RW± model equals the RW model. If α+ > α-, subjects learn more from positive than negative events. We refer to this case here as optimistic reinforcement learning. If α+ < α-, subjects learn more from negative than positive events. We refer to this case here as pessimistic reinforcement learning (Fig. 2B).
Finally, given the Q-values, the associated probability (or likelihood) of selecting each option was estimated by implementing the soft-max rule for choosing L, which is as follows:

This is a standard stochastic decision rule that calculates the probability of selecting one of a set of options according to their associated values. The temperature, β, is another scaling parameter that adjusts the stochasticity of decision-making and by doing so controls the exploration/exploitation trade-off.
Model comparison
We optimized model parameters by minimizing the negative log-likelihood of the data given different parameters settings using Matlab’s fmincon function, as previously described49. Additional parameter recovery analyses based on model simulations show that our parameter optimization procedure correctly retrieves parameters’ values (Supplementary Materials and Fig. S7). Negative log-likelihoods (LLmax) were used to compute at the individual level (random effects) for each model the Bayesian information criterion as follows:

We computed then the inter-individual average BIC in order to compare the quality of the fit of the two models, while accounting for their difference in complexity. The intra-individual difference in BIC (∆BIC=BICRW - BICRW±) was also computed in order to categorize subjects in two groups and to quantitatively describe at the individual level the divergence from an unbiased model (Fig. 2A): RW± subjects, whose ∆BIC is positive, are better explained by RW± model. RW subjects, whose ∆BIC is negative, are better explained by RW model. We note that lower BIC indicated better fit. We also calculated the model exceedance probability and the model expected frequency based on the BIC as an approximation of the model evidence. (Table 1). Individual BIC were fed into the mbb-vb-toolbox, a procedure that estimates the expected frequencies and the exceedance probability for each model within a set of models, given the data gathered from all participants. Exceedance probability (denoted XP) is the probability that a given model fits the data better than all other models in the set.
The model parameters, (α+, α- and 1/β) were also compared between the two groups of subjects. Learning rates were compared using a mixed ANOVA with group (RW vs RW±) as a between-subject factor and learning rate type (+ or -) as a within-subject factor. The temperature was compared using a two-sample two-tailed t-test. The normalized learning rates asymmetry (α+ - α-) / (α+ + α-) was also computed as a measure of the good news/bad news effect and used to assess correlation with behavioral and neural data.
Subject classification
Subjects were classified based on the ∆BIC, which is the intra-individual difference in BIC between the RW and RW± model. While controlling for model parsimony, positive value indicates that the RW± better fits the data; negative value indicates the RW model better fit. The cut-off of ∆BIC=0 is a priori meaningful because it indicates the limit beyond which there is enough (Bayesian) evidence to consider that a given subject’s behavior corresponds to a more complex model involving two learning rates. We also validated the ∆BIC=0 cut-off a posteriori with unsupervised clustering. We fitted Gaussian mixed distributions to individual ∆BICs (N=85, corresponding to the two experiments) using MatLab function gmdistribution.m. The analysis indicated that two clusters significantly better explain the variance compared to one cluster (k=1, BIC = 716.4; k=2 BIC = 635.6). The two clusters largely corresponded to subjects with negative (N=40, min= -6.4; mean= -3.6, max= -0.9) and positive ∆BIC (N=45, min=-0.5, mean=15.7, max=60.6). The two cluster differed in both the normalized difference in learning rates (0.14 vs. 0.73; t(83)=7.2, P<0.001) and exploration rate (0.32 vs 0.09; t(83)=7.2, P=0.006).
Model simulations
We also analyzed the models’ generative performance by the mean of model simulations. For each participant we devised a virtual subject, represented by a set of individual best fitting parameters. Each virtual subject dataset was obtained averaging 100 simulations, to avoid any local effect of the individual history of choice and outcome. The model simulations included all task conditions. The evaluation of generative performances involved the assessment of the “winning model’s” ability to reproduce the key statistical effects of the data, as opposite to the “losing model”. Unlike Bayesian model comparison, model simulation comparison is bounded to a particular behavioral effect of interest (in our case the preferred response rate). The model simulation analysis, which is focused on the evidence “against” a given model, is complementary to the Bayesian model comparison analysis, which is focused on the evidence in favor of a model50,51.
Imaging data Acquisition & Analysis
Subject of the first experiment (N=50) performed the task magnetic resonance imaging (MRI) scanning. T1-weighted structural images and T2*-weighted echo planar images (EPIs) were acquired during the first experiment and analyzed with the Statistical Parametric Mapping software (SPM8; Wellcome Department of Imaging Neuroscience, London, England). Acquisition and preprocessing parameters were previously and extensively described15,16. We refer to these publications for details about image acquisition and preprocessing.
Functional magnetic resonance imaging analysis
The fMRI analysis was based on a single general linear model. Each trial was modeled as having two time points, stimuli and outcome onsets. Each time point was regressed with a parameter modulator. Stimuli onset was modulated by the chosen option value (QChosen(t)); outcome onset was modulated by the reward prediction error δ(t)). Given that different subjects did not implement the same model, the choice of the model used to generate the parametric regressors is not obvious. Since the RW± and the RW models are nested and the RW± model was the group-level best fitting model, we opted for using its parameters to generate the regressors. However, note that confirmatory analyses using for each group its best fitting model’s parameters lead to similar results. The parametric modulators were z-scored to ensure between subject scaling of regression coefficients52. Linear contrasts of regression coefficients were computed at the subject level and compared against zero (one-sample t-test). Statistical parametric maps were threshold at p<0.05 with a voxel-level family-wise error (FWE) correction and a minimum of 60 contiguous voxels. Whole brain analysis was performed including both group of subjects and leads to the identification of functionally characterized neural networks used to define unbiased ROIs. The dmPFC and the Insular ROIs were defined as the intersection of the voxels significantly correlating with QChosen(t) and aal (i.e. automatic anatomical labeling) masks of the medial frontal cortex (including the superior frontal gyrus, the SMA and the anterior medial cingulate) and the bilateral insula, respectively. The vmPFC and the striatal ROIs were defined as the intersection of the voxels significantly correlating with δ(t) and aal (i.e. automatic anatomical labeling) masks of the ventral prefrontal cortex (including the anterior cingulate, the gyrus rectus and the superior frontal gyrus, orbital part and medial orbital part) and the bilateral caudate and putamen, respectively. Within ROIs the regression coefficients were compared between-group using two-sample two-tailed t-test.

Histograms show the learning rates following positive prediction errors (α+) and negative prediction errors (α-), in Experiment 1 (N=50) and Experiment 2 (N=35). Experiment 1’s worst outcome was getting nothing (0€). Experiment 2’s worst outcome was losing money (-0.50€).
Acknowledgments
The authors acknowledge Yulia Worbe and Mathias Pessiglione for granting access to the first dataset. We thank Valentin Wyart, Bahador Bahrami, Bojana Kuzmanovic and the anonymous reviewers for their helpful comments. We thank Tali Sharot and Neil Garrett for kindly providing activation masks. SP was supported by a Marie Sklodowska-Curie Individual European Fellowship (PIEF-GA-2012 Grant 328822) and is currently supported by an ATIP-Avenir grant. GL was supported by a PHD fellowship of the Ministère de lx'enseignement supérieur et de la recherche. ML was supported by an EU Marie Sklodowska-Curie Individual Fellowship (IF-2015 Grant 657904) and acknowledges the support of the Bettencourt-Schueller Foundation. The second experiment was supported by the ANR-ORA, Nesshi 2010-2015 research project to SBG.
Footnotes
↵* Bacon, F. (1939). Novum organum. In Burtt, E. A. (Ed.), The English philosophers from Bacon to Mill (pp. 24-123). New York: Random House. (Original work published in 1620)
↵† Original French citation: "Qu’est-ce qu’optimisme? disait Cacambo. – Hélas! dit Candide, c’est la rage de soutenir que tout est bien quand on est mal." Voltaire (2014), Candide ou l'optimisme, Arvensa editions, p56, Ch. XIX. (Original work published in 1759)





{kind=link}
{kind=link}
{kind=link}
{kind=link}