

Abstract
Clustering is a central approach for unsupervised learning. After clustering is applied, the most fundamental analysis is to quantitatively compare clusterings. Such comparisons are crucial for the evaluation of clustering methods as well as other tasks such as consensus clustering. It is often argued that, in order to establish a baseline, clustering similarity should be assessed in the context of a random ensemble of clusterings. The prevailing assumption for the random clustering ensemble is the permutation model in which the number and sizes of clusters are fixed. However, this assumption does not necessarily hold in practice; for example, multiple runs of K-means clustering returns clusterings with a fixed number of clusters, while the cluster size distribution varies greatly. Here, we derive corrected variants of two clustering similarity measures (the Rand index and Mutual Information) in the context of two random clustering ensembles in which the number and sizes of clusters vary. In addition, we study the impact of one-sided comparisons in the scenario with a reference clustering. The consequences of different random models are illustrated using synthetic examples, handwriting recognition, and gene expression data. We demonstrate that the choice of random model can have a drastic impact on the ranking of similar clustering pairs, and the evaluation of a clustering method with respect to a random baseline; thus, the choice of random clustering model should be carefully justified.
1. Introduction
Clustering is one of the most fundamental techniques of unsupervised learning and one of the most common ways to analyze data. Naturally, numerous methods have been developed and studied (Jain, 2010). To interpret clustering results, it is crucial to compare them to each other. For instance, the evaluation of a clustering method is usually carried out by comparing the method’s results with a planted reference clustering, assuming that the more similar the method’s solution is to the reference clustering, the better the method. This is particularly common in the field of complex networks in which clustering similarity measures are used to justify the performance of community detection methods (Danon et al., 2005; Lancichinetti and Fortunato, 2009). As quantitative comparison is a fundamental operation, it plays a key role in many other tasks. For instance, comparisons of clusterings can facilitate taxonomies for clustering solutions, can be used as a criteria for parameter estimation, and form the basis of consensus clustering methods (Meila, 2005; Vinh et al., 2009; Yeung et al., 2001).
Among the many clustering comparison methods (see, e.g. Meila, 2005; Pfitzner et al., 2009), two of the most prominent measures are the Rand index (Rand, 1971) and the Normalized Mutual Information (NMI, Danon et al., 2005). In both cases, the similarity score exists in the range [0, 1], where 1 corresponds to identical clusterings and 0 implies maximally dissimilar clusterings. However, in practice, both measures do not efficiently use the full range of values in between 0 and 1, with many comparisons concentrating near the extreme values (Vinh et al., 2009; Hubert and Arabie, 1985). This makes it difficult to directly interpret the results of a comparison.
Thus, it is often argued that clustering similarity should be assessed in the context of a random ensemble of clusterings (Vinh et al., 2009; Hubert and Arabie, 1985; DuBien and Warde, 1981; DuBien et al., 2004; Albatineh et al., 2006; Romano et al., 2014; Zhang, 2015; Romano et al., 2016) and rescaled (see Equation 1). Such a correction for chance establishes a baseline by using the expected similarity of all pair-wise comparisons between clusterings specified by a random model; the resulting similarity values have a new interpretation that facilitates comparisons within a set of clusterings. Specifically, once corrected for chance, a similarity value of 1 still corresponds to identical clusterings, but a value of 0 now corresponds to the expected value amongst random clusterings. Positive values of corrected similarity better reflect an intuitive comparison of clusterings (Hubert and Arabie, 1985; Steinley et al., 2016). The correction may also introduce negative values when two clusterings are less similar than expected by chance.
The correction procedure requires two choices: a model for random clusterings and how clusterings are drawn from the random model. However, even the existence of these choices is usually ignored or relegated to the status of technical trivialities. Here, we demonstrate that these choices may dramatically affect results, and therefore the choice of a particular model for random clusterings should be justified based on the understanding of the clustering scenario. A poor choice of the random model may “not be random enough” and encode crucial features of the clusterings in all of the random clusterings, providing a poor baseline. At the same time, a random model may be “too random” in which crucial features are lost in a sea of random clusterings that are not representative of the particular problem. Characterizing random models is an important topic of research across statistical physics, network science, and combinatorial mathematics (Sethna, 2006; Goldenberg et al., 2010; Mansour, 2012). Yet, despite the importance of random model selection, almost no study that uses clustering comparison provides a justification for their choice of random model.
By far, the most common approach to correct clustering similarity for chance assumes that both clusterings are uniformly and independently sampled from the permutation model (Mperm). In the permutation model, the number and size of clusters within a clustering are fixed, and all random clusterings are generated by shuffling the elements between the fixed clusters. However, the premises of the permutation model are frequently violated; in many clustering scenarios, either the number of clusters, the size distribution of those clusters, or both vary drastically (Hubert and Arabie, 1985; Wallace, 1983). For example, K-means clustering, probably the most common technique, fixes the number of clusters but not the sizes of those clusters (Jain, 2010). Later, we explore a real example in which K-means produces clusterings with large variations in the clusterings’ cluster size sequences. This suggests that comparing K-means clusterings based on Mperm is misleading.
Furthermore, even the assumption that both clusterings were randomly drawn from the same random model (a two-sided comparison) is often problematic. For example, when comparing against a given reference clustering, it is more reasonable to find the expected similarity of the reference clustering with all of the random clusterings from the random model. This one-sided comparison accounts for the fixed structure of the reference clustering which is always present in the comparisons, providing a more meaningful baseline.
Here, we present a general framework to adjust measures of clustering similarity for chance by considering a broader class of random clustering models and one-sided comparisons. Specifically, we consider two other random models for clusterings: a uniform distribution over the ensemble of all clusterings of N elements with the same number of clusters (Mnum), and a uniform distribution over the ensemble of all clusterings of N elements (Mall). The resulting expectations for the Rand index under all three random models are summarized in Table 1 and for Mutual Information in Table 2, with the full derivations given in Section 4 and Section 5 respectively. The adjusted similarity measures used throughout this work rescale the Rand and MI measures by these expectations according to Equation 1. We also introduce one-sided variants of the adjusted Rand index and adjusted Mutual Information when using the Mnum or Mall random models (for Mperm, the one-sided similarity is equivalent to the two-sided case).
The expected Rand index between two random clusterings 𝒜 and 𝓑 of N elements, or random clustering 𝒜 and reference clustering 𝒢 under different random models. Details and derivations are given in Section 4.
The expected Mutual Information between two random clusterings 𝒜 and 𝓑 of N elements, or random clustering 𝒜 and reference clustering 𝒢 under different random models. Details and derivations are given in Section 5.
The impact of our framework is illustrated in the case of two common tasks for adjusted clustering similarity measures: 1) ranking the similarity between pairs of clusterings (or finding the most similar clustering pair), and 2) evaluating the performance of a clustering method with respect to a random baseline. In Section 6, these tasks are demonstrated in the context of several examples: a synthetic clustering example, K-means clustering of a handwritten digits data set (MNIST), and an evaluation of hierarchical clustering applied to gene expression data. Our results demonstrate that both the choice of random model for clusterings and the choice of one-sided comparisons can affect results significantly. Therefore, we argue that clustering comparisons should be accompanied by a proper justification for the random model.
2. Clusterings
We first explicitly introduce a clustering of elements. Given a set of N distinct elements V = {v1, …, vN} (i.e. data points or vertices), a clustering is a partition of V into a set C = {C1, …, CKC} of KC non-empty disjoint subsets of V, the clusters, Ck, such that
∀Ci, Cj if i ≠j, then Ci ∩ Cj = Ø


Each clustering specifies a sequence of cluster sizes, namely, letting ci = |Ci| be the size of the i-th cluster, then the sequence of cluster sizes is [c1, c2,…, cKC].
Throughout this paper, we focus on the similarity of two clusterings over the same Set of N labeled elements, 𝒜 = {A1,…, AK𝒜} (with K𝒜 clusters of sizes ai) and B = {B1,…, BK𝓑} (with K𝓑 clusters of sizes bj).
3. Correction for Chance
Given a clustering similarity measure s and a random model for clusterings: model, the expected clustering similarity 𝔼model [s] of pair-wise comparisons within the random ensemble defined by the model corrects s for chance as follows (Hubert and Arabie, 1985)

The denominator rescales the adjusted similarity by the maximum similarity of pair-wise comparisons within the ensemble smax so identical clusterings always have a similarity of 1.0. For some clustering similarity measures, the value of smax is independent of the random model used; for example, the Rand index is always bounded above by 1.0. However, in the case of mutual information, the value of smax depends on the random model used.
4. Rand Index
The Rand index (Rand, 1971) compares the number of element pairs which are either coassigned to the same cluster, or assigned to different clusters in both clusterings, to the total number of element pairs. The most common formulation of the Rand index focuses on the following four sets of the  element pairs: N11 the number of element pairs which are grouped in the same cluster in both clusterings, N10 the number of element pairs which are grouped in the same cluster by 𝒜 but in different clusters by 𝓑, N01 the number of element pairs which are grouped in the same cluster by 𝓑 but in different clusters by 𝒜, and N00 the number of element pairs which are grouped in different clusters by both 𝒜 and 𝓑 Intuitively, N11 and N00 are indicators of the agreement between the two clusterings, while N10 and N01 reflect the disagreement between the clusterings.
element pairs: N11 the number of element pairs which are grouped in the same cluster in both clusterings, N10 the number of element pairs which are grouped in the same cluster by 𝒜 but in different clusters by 𝓑, N01 the number of element pairs which are grouped in the same cluster by 𝓑 but in different clusters by 𝒜, and N00 the number of element pairs which are grouped in different clusters by both 𝒜 and 𝓑 Intuitively, N11 and N00 are indicators of the agreement between the two clusterings, while N10 and N01 reflect the disagreement between the clusterings.
The aforementioned pair counts are identified from the contingency table 𝒯 between two clusterings, shown in Table 3, by the following set of equations

The contingency table 𝒯 for two clusterings 𝒜 = {A1,…, AK𝒜} and 𝓑 ={B1,…, BK𝓑} of N elements, where nij = |Ai ∩ Bj| are the number of elements that are in both cluster Ai ∈ A and cluster Bj ∈ B.
The Rand index between clusterings 𝒜 and 𝓑, RI(𝒜, 𝓑) is then given by the function

It lies between 0 and 1, where 1 indicates the clusterings are identical and 0 occurs for clusters which do not share a single pair of elements (this only happens when one clustering is the full set of elements and the other clustering groups each element into its own cluster). As the number of clustered elements increases, the measure becomes dominated by the number of pairs which were classified into different clusters (N00), resulting in decreased sensitivity to co-occurring element pairs (Fowlkes and Mallows, 1983).
Another formulation of the Rand index, used in our later derivations, focuses on a binary representation of the element pairs. Specifically, consider the vector  with binary entries uα ∈ {–1, 1} correspon to all possible element pairs. Using α to index over all element pairs by
with binary entries uα ∈ {–1, 1} correspon to all possible element pairs. Using α to index over all element pairs by  , for i < j ≤ N, then uα = 1 if lements vi and vj are in the same cluster in 𝒜 and uα = –1 if elements vi and vj are in different clusters in 𝒜. There are
, for i < j ≤ N, then uα = 1 if lements vi and vj are in the same cluster in 𝒜 and uα = –1 if elements vi and vj are in different clusters in 𝒜. There are  with
with

The Rand index is found from the vectors U𝒜 and U𝓑, for clusterings 𝒜 and 𝓑 respectively, as the number of 1s in their product vector, U𝒜 ⊙ U𝓑, using element-wise multiplication and normalized by the total size of the vectors,  .
.
4.1 Expected Rand Index, Permutation Model (Mperm)
The expectation of the Rand index with respect to the permutation model follows from drawing the entries in Table 3 from the generalized hypergeometric distribution. Utilizing the previous notation with  , the expectation 𝔼perm[RI(𝒜, 𝓑)] of the Rand index with respect to the permutation model for the cluster size sequences of clusterings 𝒜 and 𝓑 is given by
, the expectation 𝔼perm[RI(𝒜, 𝓑)] of the Rand index with respect to the permutation model for the cluster size sequences of clusterings 𝒜 and 𝓑 is given by

(see Fowlkes and Mallows, 1983, Hubert and Arabie, 1985, or Albatineh and Niewiadomska- Bugaj, 2011 for the full derivation).
The commonly used adjusted Rand index (ARI) of Hubert and Arabie (1985) uses Mperm to calculate the expectation of the Rand index, 𝔼perm[RI(𝒜, 𝓑)], as found in Equation 5. This expectation is then used in Equation 1, along with the fact that the maximum value of the Rand index is maxperm[RI] = 1.0, to give

4.2 Expected Rand Index, Fixed Number of Clusters
We follow DuBien and Warde (1981) to calculate the Rand index between two clusterings under the assumptions that both clusterings were independently and uniformly drawn from the ensemble of clusterings with a fixed number of clusters (Mnum). Recall that the Rand index between two clusterings 𝒜 and 𝓑 is given by the number of 1s in the element-wise product of the binary representations vectors UA and UB. The expected Rand index under any random model is then the expected number of 1s in this product vector, normalized by the total size of the vector

The product  equals 1 when either
equals 1 when either  and
and  or
or  and
and  . Since we assumed both clusterings were independent, this gives
. Since we assumed both clusterings were independent, this gives
 where
where  is the probability that the two elements vi and vj are in the same cluster in clustering 𝒜, where the element pair is indexed by
is the probability that the two elements vi and vj are in the same cluster in clustering 𝒜, where the element pair is indexed by  with i < j ≤ N. Likewise,
with i < j ≤ N. Likewise, is the probability that the two elements vi and vj are in different clusters.
is the probability that the two elements vi and vj are in different clusters.
Under the assumption of Mnum, there is a uniform probability of selecting a clustering from the S(N, K𝒜) clusterings of N elements into K𝒜 clusters; we define, Pnum as the proportion of these clusterings with elements vi and vj in the same cluster. To find this proportion, notice that we can ensure vi is in the same cluster as vj by first partitioning all elements besides vi into K𝒜 clusters; then, we can add vi to the same cluster as vj. ince there are S(N - 1, K𝒜) such clusterings without element vi, this gives
as the proportion of these clusterings with elements vi and vj in the same cluster. To find this proportion, notice that we can ensure vi is in the same cluster as vj by first partitioning all elements besides vi into K𝒜 clusters; then, we can add vi to the same cluster as vj. ince there are S(N - 1, K𝒜) such clusterings without element vi, this gives


Finally, the expected Rand index between two clusterings 𝒜 and 𝓑 with K𝒜 and K𝓑 clusters assuming Mnum is given by

When N is large, we can approximate the Stirling numbers of the second kind for a fixed K by  . This can be inserted into equation (11) to give the following approximation for the mean of the Rand index assuming Mnum
. This can be inserted into equation (11) to give the following approximation for the mean of the Rand index assuming Mnum

Interestingly, this suggests that the Rand index goes to 1 at a rate inversely related to the smaller number of clusters 𝒪
4.3 Expected Rand Index, All ClusteringsMall
The average of the Rand index between two clusterings under the assumption that the clusterings were drawn with uniform probability from the set of all clusterings directly follows from the random model with a fixed number of clusters previously discussed. Namely, because Bell numbers are related to Stirling numbers of the second kind by  a similar reasoning as followed for equation (9) gives
a similar reasoning as followed for equation (9) gives


Using this probability for the expectation in equation (7) gives the expected Rand index under the assumption that both clusterings were uniformly drawn from the set of all clusterings of N elements

When N is large, we can approximate the ratio of successive Bell numbers by  . Using this approximation in equation (15) gives the following approximation for the mean of the Rand index in Mall
. Using this approximation in equation (15) gives the following approximation for the mean of the Rand index in Mall

Interestingly, this suggests that the expected Rand index between two random clusterings goes to 1 at a rate 𝒪 , inversely proportional to the number of elements.
, inversely proportional to the number of elements.
4.4 One-Sided Rand
Consider a reference clustering 𝒢 that has the cluster size sequence [g1,…, gK𝒢]. The binary pair vector representation of 𝒢 has  , 1s and
, 1s and  –1s. The one-sided expectation of the Rand index under the assumption that clustering 𝒜 was randomly drawn from either the Mnum or Mall random models follows from treating the two clusterings independently as in equation (8). Since the cluster sequence for the reference clustering is fixed, the probability that a random entry in the binary pair vector is 1 is given by the fraction of 1s in the vector
–1s. The one-sided expectation of the Rand index under the assumption that clustering 𝒜 was randomly drawn from either the Mnum or Mall random models follows from treating the two clusterings independently as in equation (8). Since the cluster sequence for the reference clustering is fixed, the probability that a random entry in the binary pair vector is 1 is given by the fraction of 1s in the vector

The one-sided expectation of the Rand index under the assumption that clustering𝒜 was randomly drawn from the set of all clusterings with a fixed number of clusters  is
is

The one-sided expectation of the Rand index with the assumption that the random clustering 𝒜 is drawn from the ensemble of all partitions  is
is

5. Mutual Information
Another prominent family of clustering similarity measures is based on the Shannon information between probabilistic representations of each clustering. These probability distributions are also calculated from the contingency table 𝒯, Table 3. The partition entropy H of a clustering 𝒜 is given by

Using this entropy, the mutual information MI (𝒜, 𝓑) between two clusterings 𝒜 and 𝓑 is given by

The mutual information can be interpreted as an inverse measure of independence between the clusterings, or a measure of the amount of information each clustering has about the other. As it can vary in the range [0, min {H (𝒜), H(𝓑)}], to facilitate comparisons, it is desirable to normalize it to the range [0, 1]. There are at least six proposals in the literature for this upper bound, each with different advantages and drawbacks

The resulting measures are all known as normalized mutual information (NMI). This measure has been said to exhibit more desirable properties than the Rand index; for example, it is dependent on the relative proportions of the cluster sizes in each clustering rather than the number of elements. However, due to its dependence on the number of clusters in each clustering, it is known to favor comparisons between clusterings with more clusters regardless of any other shared clustering features (White and Liu, 1994; Vinh et al., 2010; Amelio and Pizzuti, 2015).
5.1 Expected Mutual Information, Permutation Model (Mperm)
The mutual information between two clusterings has also previously been studied under the assumption that both clusterings were randomly generated from the permutation model (Vinh et al., 2009; Romano et al., 2014; Vinh et al., 2010). Expanding the definition of the mutual information gives
 where the second line follows from the fact that all cluster sizes (and hence the entropy) are the same for every clustering in Mperm.
where the second line follows from the fact that all cluster sizes (and hence the entropy) are the same for every clustering in Mperm.
The expectation of the joint entropy with respect to Mperm for the cluster size distributions of clusterings 𝒜 and 𝓑 is the average over all possible contingency tables 𝒯 with entries n

Rearranging the summations, and recalling that the entries of the contingency tables are hyper-geometrically distributed such that the probability of each entry
 is only dependent on the row sum ak and column sum bm, gives
is only dependent on the row sum ak and column sum bm, gives

According to the hyper-geometric distribution, the summation over table entries nkm occurs between the lower bound: max {0, ak + bm – N} and the upper bound: min{ak, bm}. Combining this expression with the individual entropies H(𝒜) and H(𝓑) gives (Vinh et al., 2009)

As shown in Romano et al. (2014), the computational complexity of calculating the expected mutual information assuming the permutation model is of order 𝒪 (max{K𝒜N, K𝓑N}).
The adjusted mutual information (AMI) of Vinh et al. (2009) uses Mperm to correct the MI for chance according to equation (1) and selecting an upper bound max[MI] from equation (22) to give

5.2 Expected Mutual Information, Fixed Number of Clusters (Mnum)
Next, we consider the Mutual Information between two clusterings under the assumptions that both clusterings were independently and uniformly drawn from the ensemble of clusterings with a fixed number of clusters (Mnum). In this case, the expected mutual information is dependent on both the average partition entropy and the joint partition entropy

This expectation can be found by considering the average partition entropy and joint partition entropy separately. Recall that in the permutation model  since the cluster sizes remain unchanged; however, the same does not hold in Mnum. Denoting a random clustering with K𝒜 clusters as
since the cluster sizes remain unchanged; however, the same does not hold in Mnum. Denoting a random clustering with K𝒜 clusters as  , and using the notion
, and using the notion  to indicate the summation over all clusters in the clustering
to indicate the summation over all clusters in the clustering  , where the cardinality of the cluster is |σi| = a, the the expected partition entropy of a random clustering in Mnum is
, where the cardinality of the cluster is |σi| = a, the the expected partition entropy of a random clustering in Mnum is

Note that this expression only depends on the size a = |σi| for  of the clusters in the clustering. This means the expected entropy of a random clustering can be rewritten in terms of the expected contribution to the entropy from a random cluster of size a. A counting argument gives the number of clusters of size a which appear in all of the clusterings in the random ensemble. First, choose a of the N elements to form the cluster. Each clustering in Mnum must have K𝒜 clusters, so the remaining N – a elements have to be arranged into K𝒜 – 1 other clusters. There are S(N - a, KA – 1) ways to partition these remaining elements. This gives
of the clusters in the clustering. This means the expected entropy of a random clustering can be rewritten in terms of the expected contribution to the entropy from a random cluster of size a. A counting argument gives the number of clusters of size a which appear in all of the clusterings in the random ensemble. First, choose a of the N elements to form the cluster. Each clustering in Mnum must have K𝒜 clusters, so the remaining N – a elements have to be arranged into K𝒜 – 1 other clusters. There are S(N - a, KA – 1) ways to partition these remaining elements. This gives  S(N - a, KA – 1) clusters of size a (Chern et al., 2014).The expected number of clusters nnum(a) in a random clustering drawn from num is then
S(N - a, KA – 1) clusters of size a (Chern et al., 2014).The expected number of clusters nnum(a) in a random clustering drawn from num is then  . Therefore, the expected clustering entropy in Mnum is:
. Therefore, the expected clustering entropy in Mnum is:
 where the summation is over all possible cluster sizes [1, N – (K𝒜 – 1)] encountered when partitioning N elements into K𝒜 clusters.
where the summation is over all possible cluster sizes [1, N – (K𝒜 – 1)] encountered when partitioning N elements into K𝒜 clusters.
Similarly, the expected joint entropy of two random clusterings drawn independently from Mnum is given by the expected number of clusters of size a from a clustering with K𝒜 clusters, the expected number of clusters of size b from a clustering with K𝓑 clusters,and then considering the probability of overlap  from the resulting random contingency table
from the resulting random contingency table

Note that, when using equation (1) to adjust the mutual information for chance under the assumption of Mnum, the maximum value for the measure over the entire ensemble of random clusterings has to be used. When considering clusterings with a fixed number of clusters, we know that H(𝒜) ≤ log K𝒜. This means that the choices for maxnum[MI(𝒜, 𝓑)] are

As is apparent from the summations in equation (32), the computational complexity of exactly calculating the expected mutual information assuming Mnum is of order 𝒪 (N 3).
5.3 Expected Mutual Information, All Clusterings Mall
The expected Mutual Information between two clusterings under the assumption that both clusterings were independently and uniformly drawn from the set of all possible clusterings of N elements, Mall, has a similar derivation as the previous case of Mnum. Both the expectations for the entropy of a single clustering and the joint entropy of the two clusterings need to be considered separately and can be rewritten in terms of the contributions from individual clusters of a given size. In Mall, the number of clusters of size a is again found by choosing a of the N elements for the cluster and then partitioning the remaining N – a elements; there are now BN–a possible ways to cluster the remaining elements (Chern et al., 2014). This gives

The expected joint entropy for two clusterings is then

with the last simplification resulting from the symmetry of the hyper-geometric term with respect to a and b. As in the previous case, the maximum bound of the measure must be consider over the entire ensemble of clusterings. Again, we consider the bound H(𝒜) ≤ log N. This reduces to only one choice for maxall[MI(𝒜; 𝓑)] = logN.
5.4 One-Sided Mutual Information
As was the case for the one-sided expected Rand index, the one-sided expectation of mutual information follows from the fact that the cluster sequence for the reference clustering is fixed. This results in the following one-sided expected joint entropy when the random clustering 𝒜 is drawn from the Mnum model is

The corresponding one-sided expected MI assuming. is
is

The one-sided expected joint entropy when the random clustering 𝒜 is drawn from the  model is
model is

and the one-sided expectation of the MI when the random clustering 𝒜 is drawn from the model is
model is

Again, the maximum bound must be chosen with respect to the measure maximum over the clusterings present in the random model.
6. Results
The choice of random model for clusterings and the choice of one-sided comparisons can significantly affect results of clustering comparisons. We first illustrate that the ranking of similar clustering pairs (or, equivalently, finding the most similar clustering pair) depends on the choices of random models in a hypothetical example (Section 6.1) and K-means clustering of a handwritten digits data set (Section 6.2). One of the primary reasons such strong discrepancies occur is that the cluster size sequences are fixed within samples from Mperm. This means that adjusted comparisons using Mperm are unable to differentiate random clusterings with drastically different cluster size sequences, as we illustrate through our third example in Section 6.3. Second, we demonstrate that the interpretation of adjusted clustering similarity measures with respect to a random baseline also depends on the random model through an evaluation of hierarchical clustering applied to gene expression data in Section 6.4. Crucially, all of these examples illustrate that conclusions based on corrected similarity measures can change depending on the random model for clusterings.
6.1.Clustering Similarity Ranking
Our first example demonstrates how rankings assigned by the similarity score can change depending on the assumed random model. Consider the four hypothetical clusterings of 20 elements presented in Figure 1a. Clustering 𝒲 contains four equally sized clusters; clustering 𝒳 is generated by shifting the membership of one element from 𝒲; clustering 𝒴 groups the elements into 10 equally sized clusters; and clustering Ƶ groups the elements into 10 heterogeneous clusters. The similarity (from the most similar at the top to the least similar at the bottom) of all 6 clustering pairs is ranked using the Rand index and each of its three adjusted variants in Figure 1b. Note that the adjusted Rand index can be negative. The unadjusted Rand index ranking serves as a reference to illustrate how the random models change rankings.

The choice of random model for the Rand index has a significant studies assembled in de Soutoimpact on the rankings of clustering similarity. a, Four clusterings of N = 20 elements; 𝒲 and 𝒳 each contain four clusters and differ by the assignment of one element (6), 𝒴 and Ƶ each contain ten clusters. b, Rankings for the similarity of clustering pairs using the Rand index, the Adjusted Rand index assuming Mperm, the Adjusted Rand index assuming Mnum, and the Adjusted Rand index assuming Mall. Rankings which change as a function of random model are highlighted in dark red.
As one would expect, all four Rand measures identify clusterings 𝒲 and 𝒳 as the most similar (Figure 1b). However, the ranking of the other five comparisons varies widely as a result of the underlying random models. These changes can be understood by tracking comparisons to clustering Ƶ. The low Rand index for the three comparisons with clustering Ƶ (≈ 0:76)reflects the fact that clustering Ƶ has a drastically different number of clusters or cluster size sequence from the other three clusterings. The permutation model retains these differences in all random clusterings; the resulting adjusted index thus treats comparisons between clustering Ƶ and either 𝒲 or 𝒳 more favorably than those to clustering 𝒴. On the other hand, the cluster size sequence for clustering Ƶis relatively rare in both Mnum and Mall. Since clusterings 𝒴 and Ƶ have the same number of clusters, the differences in their adjusted scores using Mnum are a consequence of their cluster size sequences. Finally, all four clusterings are over 20 elements—the only factor that specifies the expected Rand in dex assuming Mall—so they are all adjusted by the same amount when Mall is used. Note that in our example, clustering Ƶ has a negative adjusted Rand score using the Mall when compared with all three other clusterings, thus it is less similar to the other three clusterings than one would have expected from comparing two completely random clusterings.
This example illustrates an important property of the Mall model. Namely, the ranking provided by the Rand index remains unchanged whenever the Mall model is used for adjustment because all clusterings have the same number of elements. However, the corrected baseline now provides a strong interpretation for negative scores: Two randomly selected clusterings are expected to be more similar. This is an important consideration for the evaluation of clustering methods; if the derived clustering is no more similar than would be expected when comparing completely random clusterings, the solution is likely not a meaningful representation of the data.
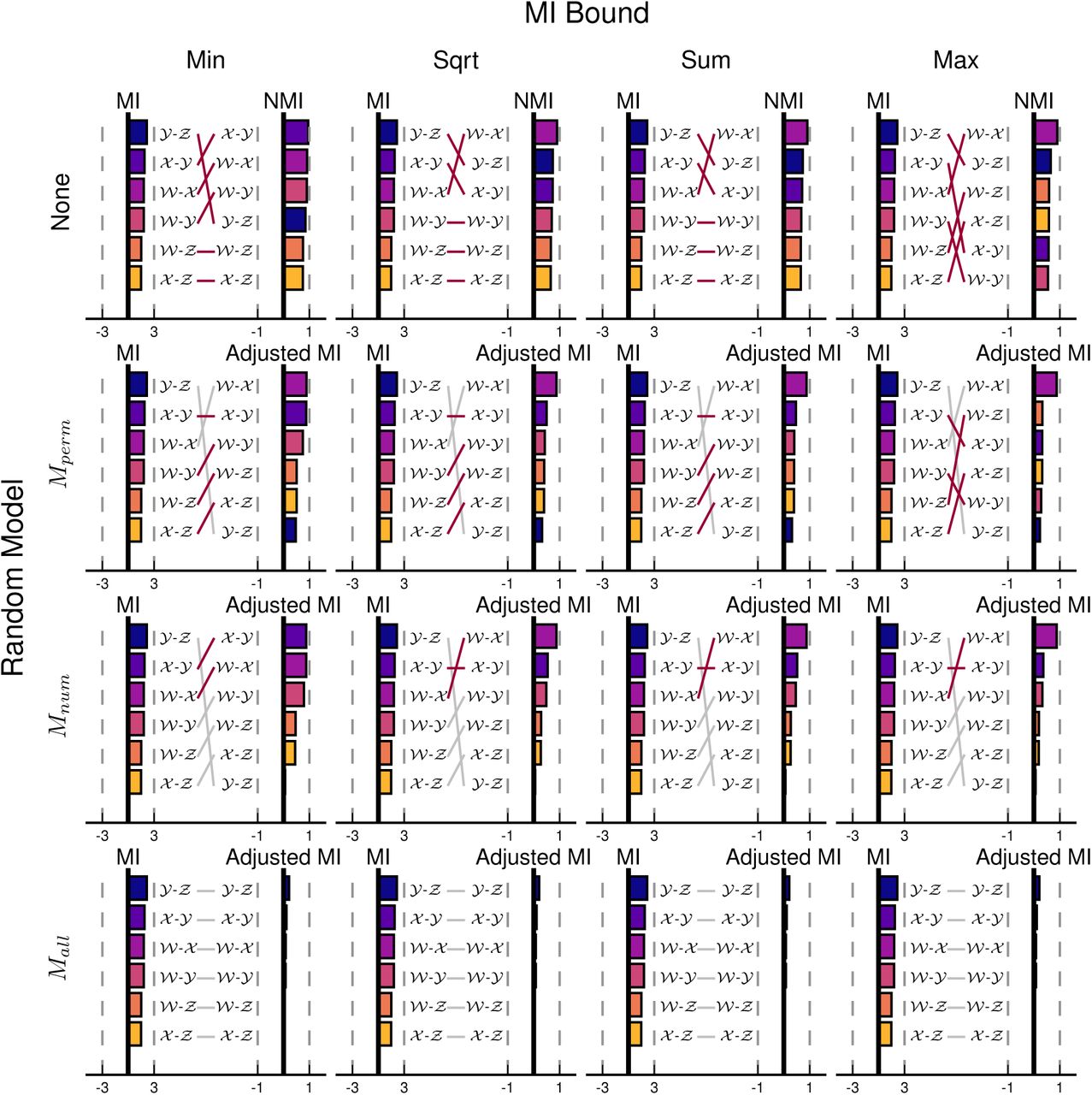
We then turn our attention to clustering similarity measured by mutual information (MI). Rankings using the adjusted MI depend on two dimensions of variation: the random model and the maximum bound for the measure. This variation is illustrated in Figure 2 using the same 6 comparisons between pairs of clusterings from Figure 1a. We consider four cases for the MI maximum bound: Min, Sqrt, Sum, and Max, corresponding to the minimum of the two model partition entropies, the geometric mean of the two model partition entropies, the average of the two model partition entropies, and the maximum of the two model partition entropies, respectively (see Appendix 5 for details). For the permutation model, the model partition entropies are calculated from the cluster size sequences, while the model partition entropies in Mnum are bounded by the logarithm of the number of clusters and the model partition entropies in Mall are bounded by the logarithm of the number of elements. As a point of reference, all rankings are illustrated in comparison to the raw mutual information score, unnormalized and without a random model adjustment (None). All adjustments of the mutual information without a random model (None, first row) are members of the commonly used family of Normalized Mutual Information (NMI) measures (Danon et al., 2005).

Both the random model and maximum bound have a significant impact on the rankings of clustering similarity using Mutual Information (MI). Rankings for the similarity of clustering pairs from Figure 1a using (vertically) the raw MI, the Adjusted MI assuming Mperm, the Adjusted MI assuming Mnum, and the Adjusted MI assuming Mall. MI similarity also depends on the choice of maximum bound (horizontal) as a function of the two clusterings’ model entropies; minimum (Min), square-root (Sqrt), average (Sum), and maximum (Max). The MI measures which are normalized but not adjusted by a random model are all members of the common family of normalized MI (NMI). For a given random model, similarity rankings which change as a function of maximum bound are highlighted in dark red.
The rankings in Figure 2 demonstrate that both the random model and the maximum bound affect the relative similarity between clusterings when adjusting MI. Firstly, the only random model whose adjustments are independent of MI’s maximum bound is Mall. This occurs because every choice of the maximum bound reduces to log N (the entropy of the clustering that places each element into its own cluster). In the other three random model scenarios, the maximum bound depends on the clusterings under comparison. Secondly, MI is highly dependent on the number of clusters in each of the clusterings: When either no normalization and random model adjustment are used, or the Mall model is used, MI ranks the similarity of clusterings 𝒴 and Ƶ above that of 𝒲 and 𝒳 because of the greater number of clusters in the former case. This bias is mitigated to varying extents by the NMI variations; while NMI using the Sqrt, Sum, and Max normalization terms all produce the intuitive ranking of 𝒲 and 𝒳 as the most similar pair, NMI using Min for normalization still succumbs to the larger number of clusters in 𝒴, and ranks 𝒳 and 𝒴 as the most similar clustering pair. The adjustments provided by both the Mperm and Mnum random models control for the number of clusters; this reduces the impact of the number of clusters when the cluster sizes are regular, but the bias re-occurs when there is a large imbalance between the cluster sizes.
6.2.Appropriate Random Model for Comparing K-means Clusterings
Clustering similarity measures are commonly used to evaluate the results of clustering methods in relation to a known reference clustering. Since the number of clusters can vary between instances, appropriately corrected similarity measures are necessary. However, as we have already seen, the choice of similarity measure and its chance corrected variants can affect the results of the comparisons and suggest drastically different interpretations for the effectiveness of the method.
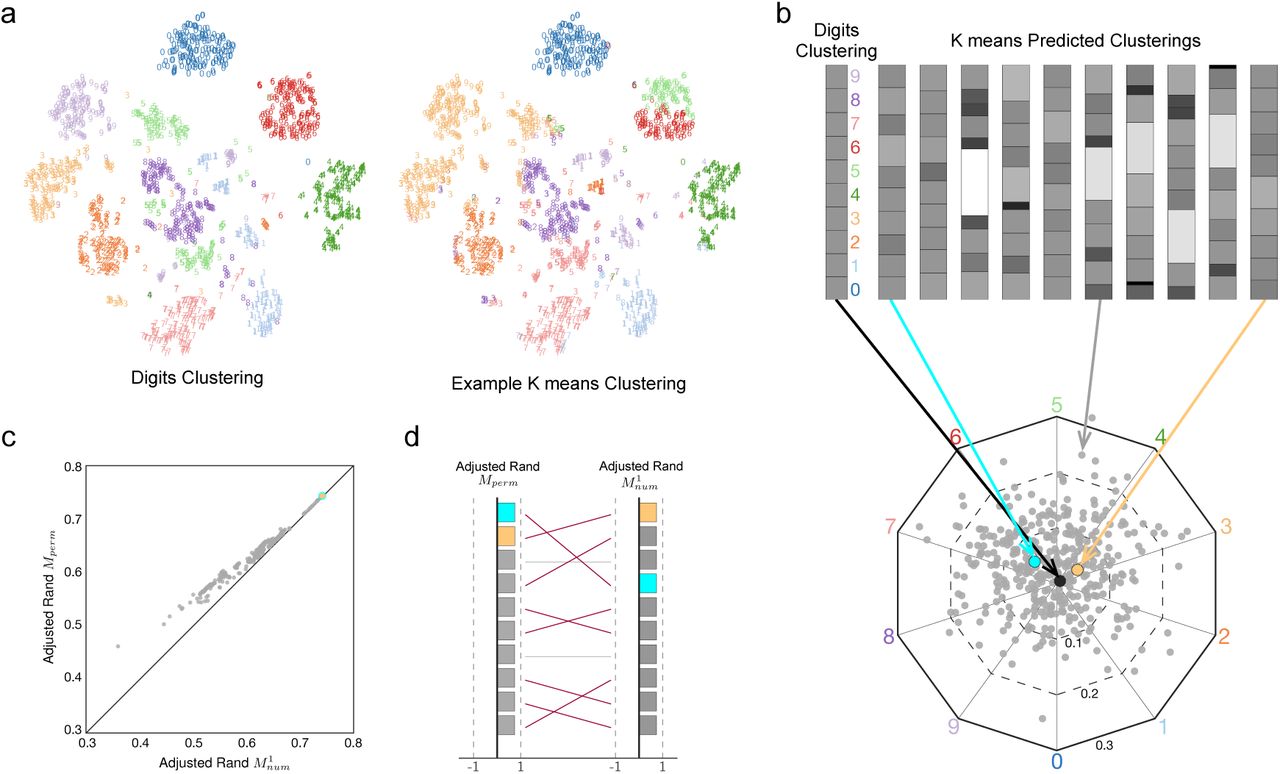
We demonstrate the importance of the random ensemble assumption through a comparison of the clusterings uncovered by 400 runs of K-means on a collection of hand-written digits (Alimoglu and Alpaydin, 1996, see Appendix B.1 for details). The K-means clustering method groups elements so as to minimize the average (Euclidean) distance from the cluster centroid. In most scenarios, it uncovers clusterings with a pre-specified number of clusters (K). For our example, the digits naturally fall into 10 disjoint clusters, shown in Figure 3a, with relative cluster sizes given on the left of Figure 3b. Interestingly, almost all 400 clusterings produced by K-means have a different cluster size sequence (Figure 3b, bottom) and the cluster sizes vary over a wide range (Figure 3b, top). This suggests that both the specific assignment of elements to clusters and the size sequence of the clusters are major factors differentiating the K-means clusterings. Both sources of variation need to be captured by the random model in order to have a meaningful baseline.

The impact of random model choice on the evaluation of K-means clustering. a, The digits data set contains 1, 797 points in 64 dimensions (projected to 2 dimensions using t-SNE dimensionality reduction for visualization, Van der Maaten and Hinton, 2008) with a ground truth clustering corresponding to the digit, and an example K-means clustering. b, The original cluster size sequence (top left) and 10 cluster size sequences uncovered by K-means clustering with random initialization (top right). Intensity represents cluster sizes that are smaller (darker) or larger (lighter) than the ground truth clusters. (bottom) The cluster size sequence for 400 clusterings uncovered by K-means clustering with random initialization using Barycentric coordinates. The actual clustering size sequence (black) and the most similar clustering determined by the Adjusted Rand index assuming Mperm (light blue) and  (light orange). c, The similarity between the actual digits clusterings and each of the 400 K-means clusterings as measured by the Adjusted Rand index assuming Mperm (y-axis) and
(light orange). c, The similarity between the actual digits clusterings and each of the 400 K-means clusterings as measured by the Adjusted Rand index assuming Mperm (y-axis) and  (x-axis). d, The ranking of the most similar 10 K-means clusterings as determined by the Adjusted Rand index assuming Mperm (left) and
(x-axis). d, The ranking of the most similar 10 K-means clusterings as determined by the Adjusted Rand index assuming Mperm (left) and (right).
(right).
Since the number of clusters does not change between runs, but the size sequence of those clusters changes considerably, it is more appropriate to assess similarity within the context of random clusterings with a fixed number of clusters rather than those given by the permutation model. Furthermore, since all of the comparisons are made against the same reference clustering, a one-sided similarity metric better captures the comparison scenario. In Figure 3c, the similarity of the reference clustering compared to each of the 400 uncovered clusterings is shown using the Adjusted Rand index assuming Mperm and the Adjusted Rand index assuming  . While the measures are strongly correlated (the black line indicates perfect agreement), the Adjusted Rand index assuming Mperm is consistently biased towards higher similarity. Most importantly, the bulk of the uncovered clusterings change their relative ranking when considered in the context of
. While the measures are strongly correlated (the black line indicates perfect agreement), the Adjusted Rand index assuming Mperm is consistently biased towards higher similarity. Most importantly, the bulk of the uncovered clusterings change their relative ranking when considered in the context of  compared to Mperm as demonstrated by the rankings of the top 10 most similar clusterings in Figure 3d.
compared to Mperm as demonstrated by the rankings of the top 10 most similar clusterings in Figure 3d.
6.3.Random Models and Inhomogeneous Cluster Sizes
For both the Rand index and MI, the permutation model is invariant to differences in the cluster size sequence. This invariance is explicitly demonstrated in our next example by the difference between the adjusted similarity measures assuming Mperm and Mnum. To generate an increasing disparity in cluster sizes, we use a preferential attachment model of element assignment. At each step of the algorithm, a random element is uniformly chosen for reassignment to a new cluster based on the current sizes of those clusters. A move is rejected if it results in an empty cluster.
In Figure 4, we compare a clustering of 1, 000 elements grouped into 50 equally sized clusters and a randomized variant of the same clustering throughout 106-steps of our preferential attachment algorithm using the Adjusted Rand index (Figure 4a) and Adjusted MI (Figure 4b). Cluster size inhomogeneity is measured by the entropy of the clustering size sequence; equally sized clusters have the maximum entropy (log2 50 ≈ 5.64), while greater inhomogeneity in cluster sizes decreases the entropy of the cluster size sequence. In both cases, the comparisons assuming Mperm are invariant to the inhomogeneity of the cluster size sequences. On the other hand, comparisons assuming Mnum reflect the changes in the cluster size sequence.

The invariance to inhomogeneous cluster size sequences when assuming Mperm. A clustering with 50 equal-sized clusters is compared to a second clustering B generated by a preferential attachment model. The cluster size sequence inhomogenity for clustering B is measured by the cluster size sequence entropy (low entropy is indicative of large cluster size inhomogenity). The similarity is calculated using the adjusted similarity assuming the permutation model Mperm and Mnum for a, the Adjusted Rand index, and b, the Adjusted Mutual Information. In both cases, the similarity assuming Mperm is relatively constant (near 0), while the similarity assuming Mnum increases with increasing entropy.
6.4.Performing at Random in Tumor Gene Expression Clustering
Finally, recall that adjusted clustering similarity measures have the added interpretation with respect to a random baseline. Such random baselines play an important role when evaluating methods in unsupervised learning and classification. In our case, the adjusted similarity measures answer the question: Is the result of our clustering method more similar to the desired clustering than if we selected a random clustering? The adjusted similarity measure quantifies an answer to this question: positive scores indicate performance above random, while negative scores indicate a random clustering is more similar.
The interpretation of the adjusted similarity as a random baseline is highly dependent on the assumption of the random model. Critically, if the random model does not reflect the actual ensemble in which the clustering method is searching, the baseline does not accurately reflect the scenario in question. Thus, methods are incorrectly assessed as performing better than randomly generating a clustering.
We illustrate the dependence of adjusted similarity baseline on the choice of random model using a gene expression data set. Specifically, we use a collection of 35 cancer gene expression studies assembled in de Souto et al. (2008). The studies in the collection aim to differentiate the gene expression in cancerous cell tissue samples from those in healthy controls. Each study contains anywhere from 22 to 248 data points (individual tissue samples) for which between 85 and 4, 553 features (individual gene expression) were measured after removing the uninformative and missing genes. For details on the individual studies and filtering methodologies, see de Souto et al. (2008) and references therein.
Clusterings are identified via agglomerative hierarchical clustering using correlation to compute the average linkage between data points, a common clustering methodology in biology. While many other methods could be used (and indeed, were compared in de Souto et al., 2008), we use hierarchical clustering as a representative example to illustrate the consequences of the random model. Since hierarchical clustering produces a clustering with the user specified number of clusters, its similarity should be adjusted using the one-sided Adjusted Rand index assuming , where the reference clustering is specified for each study individually.
, where the reference clustering is specified for each study individually.
Figure 5 shows the similarity between the derived clustering and the reference clustering for each of the 35 studies. The Adjusted Rand index assuming Mperm is shown on the x-axis; positive scores (blue and pink points) denote the method performed better than the random baseline, while negative scores (orange and green points) denote the method performed worse than the random baseline. When the Adjusted Rand index assuming  is used (y-axis), a different classification of method performance with respect to the random baseline is found. Of particular note are the seven studies for which the method performed better than chance according to Mperm, yet,
is used (y-axis), a different classification of method performance with respect to the random baseline is found. Of particular note are the seven studies for which the method performed better than chance according to Mperm, yet,  concludes the method actually performed worse than chance (pink points). In this case, a random lustering drawn from the model with a fixed number of clusters would actually perform better than agglomerative hierarchical clustering, yet the practitioner using the permutation model would incorrectly conclude the method was performing better than chance. This discrepancy occurs even when the values of the Adjusted Rand index assuming Mperm are relatively high (> 0.4). Similarly interesting are the three studies in which the method performed worse than chance according to Mperm, yet,
concludes the method actually performed worse than chance (pink points). In this case, a random lustering drawn from the model with a fixed number of clusters would actually perform better than agglomerative hierarchical clustering, yet the practitioner using the permutation model would incorrectly conclude the method was performing better than chance. This discrepancy occurs even when the values of the Adjusted Rand index assuming Mperm are relatively high (> 0.4). Similarly interesting are the three studies in which the method performed worse than chance according to Mperm, yet,  concludes the method actually performed better than chance (orange points).
concludes the method actually performed better than chance (orange points).

The impact of random model choice on the evaluation of gene expression clustering with respect to the random baseline. The results of agglomerative hierarchical clustering identified from the gene expression in tissue samples from cancerous and healthy cells in 35 studies. a, The uncovered clusterings are compared to the reference clustering using the Adjusted Rand index assuming the permutation model Mperm (x-axis), and the one-sided Adjusted Rand index assuming a fixed-number of clusters  (y-axis). The dashed grey line indicates numerical agreement between the similarity measures. There are four possibilities when using two measures to assess similarity with respect to the random baseline: both random models conclude better than chance (blue, quadrant I), both random models conclude worse than chance (green, quadrant III), Mperm concludes better than chance but
(y-axis). The dashed grey line indicates numerical agreement between the similarity measures. There are four possibilities when using two measures to assess similarity with respect to the random baseline: both random models conclude better than chance (blue, quadrant I), both random models conclude worse than chance (green, quadrant III), Mperm concludes better than chance but  concludes worse than chance (pink, quadrant IV),and visa-versa (orange, quadrant II). b, The assumed random model affects the classification of clustering comparisons with respect to the random baseline in all four random models considered here (
concludes worse than chance (pink, quadrant IV),and visa-versa (orange, quadrant II). b, The assumed random model affects the classification of clustering comparisons with respect to the random baseline in all four random models considered here ( , Mnum, Mall and
, Mnum, Mall and  ) vs. Mperm.
) vs. Mperm.
7. Discussion
Given the prevalence of clustering methods for analyzing data, clustering comparison is a fundamental problem that is pertinent to numerous areas of science. In particular, the correction of clustering similarity for chance serves to establish a baseline that facilitates comparisons between different clustering solutions. Expanding previous studies on the selection of an appropriate model for random clusterings (Meila, 2005; Vinh et al., 2009; Romano et al., 2016), our work provides an extensive summary of random models and clearly demonstrates the strong impact of the random model on the interpretation of clustering results.
Our results underpin the importance of selecting the appropriate random model for a given context. To that end, we offer the following guidelines:
Consider what is fixed by the clustering method: do all clusterings have a user specified number of clusters (use Mnum), or is the cluster size sequence fixed (use Mperm)?
Is the comparison against a reference clustering (use a one-sided comparison), or are you comparing two derived clusterings (then use a two-sided comparison)?
The specific comparisons studied here are not meant to establish the superiority of a particular clustering identification technique or a specific random clustering model, rather, they illustrate the importance of the choice of the random model. Crucially, conclusions based on corrected similarity measures can change depending on the random model for clusterings. Therefore, previous studies which did promote methods based on evidence from corrected similarity measures should be re-evaluated in the context of the appropriate random model for clusterings (Yeung et al., 2001; de Souto et al., 2008; Yeung and Ruzzo, 2001; Thalamuthu et al., 2006; McNicholas and Murphy, 2010).
Throughout this work, we assumed a uniform probability of selecting a partition given a constraint on the types of partitions in the ensemble. However, other probability distributions could be used which better model the clusterings encountered in practice. For example, instead of using a uniform distribution over the number of clusters, one could consider an inferred distribution for the number of clusters actually uncovered by a given method (e.g. affinity propagation). This is particularly relevant when considering Mall, an extreme case for random partitions. Additionally, given that many systems exhibit clusterings with a heavy-tailed cluster size sequence, clusterings with such skewed cluster size distributions could be favored. Changes to the prior probabilities would likely change the expectations of the clustering similarity measures.
The behavior of the Rand index and Mutual Information in the context of the random clustering models discussed here further reveals problems with both measures. Specifically, the expected similarity of random clusterings increases as the number of elements grows. Intuition would suggest the opposite; the similarity of two randomly selected clusterings should decrease as the number of elements increases because it is harder to match the element memberships to clusters between two random clusterings. Instead, both MI and Rand are dominated by the fact that the expected number of clusters and cluster size distribution are converging with increasing N (Mansour, 2012). Our analysis also illustrates the dependency on the normalization term for MI, which, combined with a previously established bias on the number of clusters, suggests more care should be taken when interpreting the results of MI clustering comparisons.
In conclusion, our framework for the correction of clustering similarity for chance allows for more conscious comparisons between clusterings. The practitioner should always provide justification for their choice of random clustering model and treatment of one-sided comparisons.
Appendix A. Stirling and Bell Numbers
The Stirling number of the second kind S(n, k) gives the number of ways to partition a set of n elements into k clusters, where

There are several recurrence relations which also give S(n, k), one of the most useful is the relation

As n → ∞, an asymptotic approximation to the Stirling numbers of the second kind for a fixed k is given by .
.
The Bell number Bn is the total number of clusterings over a set with n elements. It is related the Stirling numbers of the second kind by the summation over k for a fixed n,  . There is also a useful recurrence relation for Bell numbers: Bn+1 =
. There is also a useful recurrence relation for Bell numbers: Bn+1 =  . As n → ∞, an asymptotic approximation to the ratio of the n-th and (n + 1)-th Bell numbers is
. As n → ∞, an asymptotic approximation to the ratio of the n-th and (n + 1)-th Bell numbers is . See Mansour (2012) for an extended discussion of both the Stirling numbers of the second kind and the Bell numbers.
. See Mansour (2012) for an extended discussion of both the Stirling numbers of the second kind and the Bell numbers.
In practice, calculating the Bell numbers and Stirling numbers of the second kind from their recurrence relations can be computationally expensive. However, many efficient approximations and implementations are available (Temme, 1993; Mansour, 2012). Here, we make use of the mpmath arbitrary precision library for Python developed by Johansson et al. (2013). This library takes advantage of Dobiński’s Formula to approximate the Bell numbers (Dobin ń ski, 1877; Chen and Yeh, 1994).
Appendix B. Application Data Sets
B.1.Digits Data Set
The digits data set is bundled with the scikit learn source code and consists of 1, 797 images of 8 × 8 gray level pixels of handwritten digits. The reference clustering contains 10 clusters corresponding to the true digit. The data set was originally assembled in Alimoglu and Alpaydin (1996). To provide a visualization, the data was projected to 2-d using the t-Distributed Stochastic Neighbor Embedding (t-SNE) dimensionality reduction method (Van der Maaten and Hinton, 2008) initialized from the pca decomposition.
B.2 Gene Expression Data Set
The data was assembled in de Souto et al. (2008) and is freely available from http://bioinformatics.rutgers.edu/Publications/deSouto2008c/index.html. The studies represent two prominent methods for determining gene expression in cell tissue samples from cancer tumors or healthy controls, Affymetrix microarrays and cDNA microarrays, which, respectively, measure the number of RNA copies found in the cell and the ratio of the number of copies vs a control sample. Each study contains anywhere from 22 to 248 data points (individual tissue samples) for which between 85 and 4, 553 features (individual gene expression) were measured after removing the uninformative and missing genes. Please see de Souto et al. (2008) for details of this selection process.
References
Acknowledgments
We thank Ian Wood, Santosh Manicka, James Bagrow, Sune Lehmann, Aaron Clauset, Randall D. Beer, and Luis M. Rocha for helpful discussions. We also thank two anonymous reviewers for their wonderful insights and suggestions to improve the paper. A package to computer the adjusted similarity measures is available on the author’s github: https://github.com/ajgates42/clusim
Footnotes
AJGATES{at}INDIANA.EDU
YYAHN{at}INDIANA.EDU





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}