

Abstract
One persistent curiosity in visuomotor adaptation tasks is the fact that participants often reach a learning asymptote well below full compensation. This incomplete asymptote has been explained as a consequence of obligatory computations in the implicit adaptation system, such as an equilibrium between learning and forgetting. A body of recent work has shown that in standard adaptation tasks, cognitive strategies operate alongside implicit learning. We reasoned that incomplete learning in adaptation tasks may primarily reflect a speed-accuracy tradeoff on time-consuming motor planning. Across three experiments, we find evidence supporting this hypothesis, and demonstrate that the incomplete asymptote of adaptation appears to be primarily a consequence of hastened motor planning. When an obligatory waiting period was administered before participants executed their movements, they were able to fully counteract imposed perturbations (experiment 1). Inserting the same delay between trials - rather than during movement planning - did not induce full compensation, suggesting that motor planning time predicts the learning asymptote (experiment 2). In the last experiment, instead of directly manipulating the planning time, we asked participants to continuously report their movement aim. We show that emphasizing explicit re-aiming strategies also leads to full asymptotic learning, supporting the idea that prolonged motor planning may involve a parametric rotation of aiming direction whose premature termination yields incomplete asymptotic learning (experiment 3). Findings from all experiments support the hypothesis that incomplete adaptation is, in part, the result of an intrinsic speed-accuracy tradeoff, perhaps related to cognitive strategies that require parametric attentional reorienting from the visual target to the goal.
Introduction
When the relation between motor commands and their consequences is changed by physical or visual perturbations, the sensorimotor system adapts to restore accurate motor performance (Cunningham, 1989; Lackner & Dizio, 1994; Shadmehr & Mussa-Ivaldi, 1994). One common observation in this context is an incomplete learning asymptote. That is, if participants are required to make reaching movements and counteract, say, a 30° visuomotor rotation, their adaptation curve tends to asymptote below full compensation, for instance around ∼25° (Holland, Codol, & Galea, 2018; Huberdeau, Haith, & Krakauer, 2015; van der Kooij, Brenner, van Beers, & Smeets, 2015; van der Kooij, Overvliet, & Smeets, 2016). Indeed, previous studies have pointed out that this residual asymptotic error is typically significantly different from zero (Hinder, Riek, Tresilian, Rugy, & Carson, 2010; Shmuelof et al., 2012; Spang, Wischhusen, & Fahle, 2017; van der Kooij et al., 2015; van der Kooij et al., 2016; Vaswani et al., 2015).
One explanation for this phenomenon is derived from state-space models of adaptation, which are incremental Markovian learning algorithms that balance both learning and forgetting during adaptation (Cheng & Sabes, 2006; Smith, Ghazizadeh, & Shadmehr, 2006; Thoroughman & Shadmehr, 2000). When fit to human learning data, many different values of learning and forgetting parameters can produce a steady-state equilibrium at an arbitrary asymptotic level. State-space models provide a natural explanation of the commonly observed undershoot via an assumption that some amount of forgetting (i.e., reversion to baseline) is inevitable on each trial of the task. This interpretation suggests that incomplete compensation during motor adaptation is simply a built-in feature of the implicit adaptation mechanism.
A recent study has pointed out that human subjects in principle possess the capacity to overcome the incomplete asymptote (Vaswani et al., 2015): The researchers found under-compensation in normal adaptation circumstances where visual feedback contained naturalistic motor noise, an effect that was easily captured by the state-space model. However, when visual feedback was “clamped” after learning (i.e., it moved in a fixed trajectory toward the target or in a nearby direction), participants appeared to adopt a new learning strategy that allowed them to break free of their residual errors and fully compensate for the perturbation. Given this apparent capacity for full compensation, why does the central nervous system not use it under normal, non-error-clamped, circumstances? To explain this, the authors of the study suggested that one specific learning process obeys the dynamics of the state-space model and suppresses other processes. The suppressed processes then only make a relevant contribution when the former process is disengaged (Shmuelof et al., 2012; Vaswani et al., 2015; Vaswani & Shadmehr, 2013; Wong, Haith, & Krakauer, 2015). In the present study, we propose and evaluate an alternative account of why the motor system does not overcome incomplete asymptotic learning, namely that it primarily reflects an intrinsic speed-accuracy tradeoff based on time-consuming movement planning.
The inverse relation between the accuracy of a response and the time taken to produce it has been shown to be a pervasive principle of information processing across task domains (Heitz, 2014; Plamondon & Alimi, 1997). For instance, research in perceptual decision-making tasks has established that freely chosen reaction times reflect a tradeoff between waiting for more information and moving early in order to speed up the accrual of (uncertain) reward on future trials (Churchland, Kiani, & Shadlen, 2008; Cisek, Puskas, & El-Murr, 2009; Thura, Beauregard-Racine, Fradet, & Cisek, 2012; Thura & Cisek, 2017). While visuomotor adaptation tasks traditionally are not studied in the framework of decision-making, recent research has highlighted an important role for volitional decision-making strategies in adaptation tasks (i.e., the explicit re-aiming of movements to counteract perturbations during learning; (Bond & Taylor, 2015; Heuer & Hegele, 2015; McDougle, Bond, & Taylor, 2015; Schween & Hegele, 2017; Taylor, Krakauer, & Ivry, 2014)). Further evidence suggests that in the context of adaptation to a novel visuomotor rotation such strategies may take the form of mentally rotating the aiming direction of the reaching movement (McDougle & Taylor, 2019), which has been known to require long preparation times (Fernandez-Ruiz, Wong, Armstrong, & Flanagan, 2011; Haith, Huberdeau, & Krakauer, 2015; McDougle & Taylor, 2019). Thus, an incomplete learning asymptote could simply arise from hurried movement initiation leading to prematurely terminating the mental rotation of the aiming vector during movement planning.
We tested this hypothesis over three behavioral experiments where we artificially extended planning time and predicted that this would alleviate incomplete asymptotic behavior. In the first experiment (experiment 1), we introduced a mandatory waiting period between target presentation and movement onset. In experiment 2, we sought to exclude effects of the total experiment duration by emphasizing the role of within-trial movement planning time. Finally, in experiment 3, we used aiming reports (Taylor et al., 2014) to emphasize the application of explicit strategies before movement execution during training and elucidate its impact on learning asymptote.
Methods
Participants
Ninety neurologically healthy and right-handed students from the Justus Liebig University Giessen were recruited as participants (Experiment 1: N = 36, Experiment 2: N = 36, Experiment 3: N = 18) and received monetary compensation or course credit for their participation. Written, informed consent was obtained from all participants before testing. The experimental protocol was approved by the local ethics committee of the Department of Psychology and Sport Science. All participants were self-declared right-handers. Data of one participant (experiment 2) was excluded due to a large number of irregular trials (i.e. premature movement initiation, moving too fast or too slow).
Apparatus
Participants sat on a height-adjustable chair facing a 22’’ widescreen LCD monitor (Samsung 2233RZ; display size: 47,3 cm x 29,6 cm; resolution: 1680 × 1050 pixels; frame rate 120 Hz), which was placed on eye level 100 cm in front of them. Their right hand held a digitizing stylus, which they could move across a graphics tablet (Wacom Intuos 4XL). Their hand position recorded from the tip of the stylus was sampled at 130 Hz. Stimulus presentation and movement recording were controlled by a custom build MATLAB script (R2017b) using the Psychophysics toolbox (Brainard, 1997; Pelli, 1997). An occluder, which was placed 20 cm above the table platform, prevented direct vision of the hand (left panel Figure 1A).
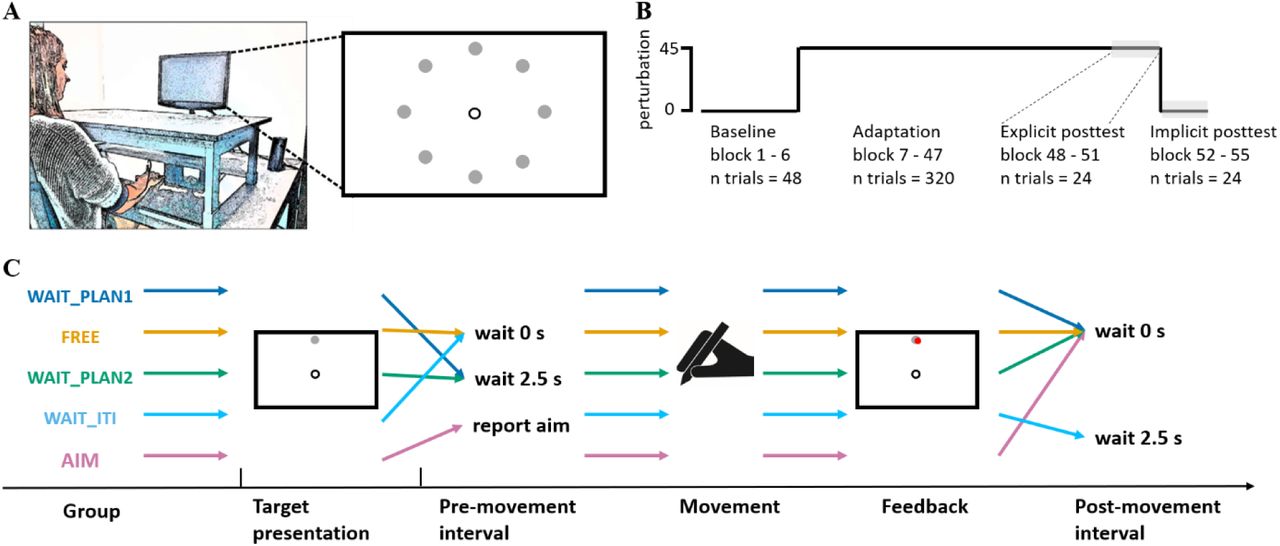
schematic display of the experimental setup (A), overall protocol (B) and sequence of one trial (C). Each participant performed center-out reaching movements with a stylus on the tablet. Visual stimuli and the cursor were presented on a monitor. The visual cursor was displaced according to the protocol (B). During baseline, cursor and stylus position were veridical, during adaptation, the cursor was rotated 45°clockwise relative to the stylus position. Within-trial timing differed between groups (C). Group dependent differences within one trial occurred either during the pre- or post-movement interval. Whereas the FREE and WAIT_ITI groups had no specific task during the pre-movement interval, WAIT_PLAN1 and WAIT_PLAN2 groups were required to wait 2.5 s and the AIM group reported their movement aim. During post-movement interval, only the participants in the WAIT_ITI group were required to wait 2.5 s, whereas all other group continued with the next trial immediately. Panel A adapted from (Schween, Taylor, & Hegele, 2018) under CC-BY-4.0 license.
Task
Participants performed center-out reaching movements from a common start location to targets in different directions. They were instructed to move the cursor as quickly as possible from the start location in the direction of a target location, and “shoot through it”. On the monitor, the start location was in the center of the screen, marked by the outline of a circle of 7 mm in diameter. On the table surface, the start location was 20 - 25 cm in front of the participant on the body midline. The target location, marked by a filled green circle of 4 mm in diameter, varied from trial to trial. Targets were placed on an invisible circle with a radius of 100 mm around the start location; target locations were 0, 45, 90, 135, 180, 225, 270, and 315° (0° is from the start location to the right, 90° is forward, 270° is backward; right panel Figure 1A). On baseline and adaptation trials, visual feedback was given by a filled white circle (radius 2.5 mm).
Design and procedure
The experiment comprised three phases: baseline training, training with a 45° clockwise (CW) visuomotor rotation, and posttests (Figure 1B). Baseline training had veridical hand-cursor mapping and was organized into three blocks of eight trials each. In experiment 3, baseline training included three additional blocks in which participants had to report their aiming direction prior to movement onset. Each block consisted of a random permutation of the eight target directions without any direction being repeated in successive trials. Training of the visuomotor rotation of 45° CW consisted of 40 blocks of eight trials each.
The posttest phase consisted of two types of trials: an explicit test (see below) comprising three blocks of eight trials each, with each target location occurring once per block, and three blocks of eight test trials without visual feedback, and with the instruction that the cursor rotation was absent.
Each single-movement trial started with the presentation of a white circle in the center of the screen, serving as the starting position for the subsequent reaching movement. The cursor was displayed when it was within 3 mm of the start location, a tone (440Hz, 0.05 ms) was presented, followed by a green target (radius 4 mm) appearing in one of the eight target positions and the start circle disappeared. Depending on the assigned group, participants were either instructed to move freely after the target appeared (experiment 1: FREE; experiment 2: WAIT_ITI), to wait 2.5 s for a second tone serving as a go signal for the reaching movement (experiment 1: WAIT_PLAN1; experiment 2: WAIT_PLAN2) or to report their movement aim and then initiate the movement (experiment 3: AIM).
The white cursor was visible until it exceeded a movement amplitude of 3 mm, where it disappeared. When the participant’s hand crossed an invisible circle that contained the target, the cursor froze and turned red, providing terminal endpoint feedback for 1.25 s. Movements that fell outside the range of instructed movement time criteria (MT < 100 ms or > 300 ms) were followed by an error message on the screen and the trial was aborted. Those trials were neither repeated nor used for subsequent analyses. If participants moved too soon in one of the waiting groups (before the target appearance or the go cue, see below), they were reminded to wait, and the trial was repeated.
The return movement back to the start location was performed without vision of the cursor, except when the hand was < 3 mm from start location. In order to help guide participants’ movements back to the start, a white concentric circle appeared after feedback presentation, scaling its radius based on the cursor’s distance from the starting circle.
In explicit test trials (Hegele & Heuer, 2010; Heuer & Hegele, 2008), start and target locations were presented together with a white line, centered in the start location with its length corresponding to target distance. Initially, the line was presented at an angle of 180° CCW of the respective target’s direction. Participants instructed the experimenter to adjust the orientation of the line to match the direction of the movement they judged to be correct for the particular target presented.
Groups
The three experiments included five different groups: Two groups of participants took part in experiment 1. One group was instructed to move straight to the target after it appeared with no additional time constraints before moving (FREE). The other group (WAIT_PLAN1) was instructed to wait until they heard a high-pitched tone (1000 Hz, 0.05 ms) that served as a go-signal. Inspired by previous work indicating that participants are able to mentally rotate and move 90° off target within ∼1 s (McDougle & Taylor, 2019), we chose a 2.5 s wait interval to provide ample planning time for the task at hand. The high-pitched tone was presented after this wait interval.
Experiment 2 consisted of two groups: the WAIT_PLAN2 group was designed as a replication of the WAIT_PLAN1 group in experiment 1. Participants in the WAIT_ITI group could initiate movements as soon as the target had appeared on the screen replicating the FREE group from experiment 1, but they experienced an additional 2.5 s waiting period after the presentation of the endpoint feedback. Thus, the two groups, WAIT_PLAN2 and WAIT_ITI, had matched trial lengths. During the 2.5 s delay in the WAIT_ITI group, only the target was visible on the screen and participants were told to maintain their final hand position.
Experiment 3 included a single group of participants who were asked to report their aiming direction prior to movement initiation (AIM group; (Bond & Taylor, 2015; McDougle et al., 2015; Taylor et al., 2014). The participants of this group saw a numbered ring of landmarks. The numbers were arranged at 5.6-degree intervals and included the target at the “0” position. Clockwise, the numbers became larger, and counterclockwise the numbers became smaller (up to 32, −32, respectively), forming a circle 20 cm in diameter. Participants were instructed to verbally report the number they aimed at before moving (see (Taylor et al., 2014) for further information). Verbal reports were manually registered by the experimenter on each reporting trial.
Data Analysis
Position of the stylus on the tablet surface was sampled at 130 Hz and each trial was separately low-pass filtered (fourth-order Butterworth, 10 Hz) using Matlab’s filtfilt command, and numerically differentiated. Tangential velocity was calculated as the Euclidean of x- and y-velocity vectors. Movements were analyzed in terms of two parameters: reaction time and endpoint error. Endpoint error was calculated as the angular difference between the vector connecting the start circle and the target, and the vector connecting the start circle and the terminal hand position. Endpoint errors were calculated for both training trials and the aftereffect trials. The outcome variable of the perceptual judgement test was calculated as the angular difference between the participant-specified line orientation on the screen and the vector connecting the start and target positions.
Reaction time (RT) was calculated as the interval between target presentation and movement onset, which was defined when tangential velocity exceeded 30 mm/s for at least 38 ms.
For each block of training trials and for the posttest, medians were computed for each participant following a screening for outliers. Movements whose endpoint error fell outside three standard deviations of the participants’ individual mean endpoint error in that phase were considered outliers and removed (1.4% of all trials). To compare different levels of asymptote, the last five blocks of the training phase were median averaged and compared between groups using a two-sample Wilcoxon’s rank-sum test. Statistical analyses were done in Matlab (R2017b) and R (version 3.5.1, http://www.R-project.org/). All results are based on median averaged data, which did not qualitatively change outcomes compared to corresponding parametric tests (data not shown).
Results
Experiment 1
Experiment 1 tested the speed-accuracy hypothesis by artificially prolonging movement planning time. To do so, we compared two groups. The FREE group could freely initiate their movement, representing a “standard” adaptation experiment. The WAIT_PLAN1 group was required to withhold movement initiation until hearing a “go”-signal 2.5 s after target onset. As shown in Figure 2A, the FREE group displayed the typical incomplete asymptote, whereas the WAIT_PLAN1 group achieved a greater asymptote (meanWAIT_PLAN1 = 46.66, sdWAIT_Plan1 = 5.85, meanFREE = 41.15, sdFREE = 8.28; V = 244, p = 0.001). Hand directions late during practice were significantly less than 45° in the FREE group (V = 32.5, p = 0.018), while the WAIT_PLAN1 group did not differ significantly from 45° (V = 108, p = 0.62).

Median hand direction (panels A-C) and mean reaction times (panels D-F) during practice plotted separately by experiments and groups. Panel G-I show the median hand direction during explicit and implicit posttests, separately. Panel l additionally shows the verbally reported aim (yellow boxplot in Explicit) and the difference between actual hand position and reported aim (yellow boxplot in Implicit). The horizontal dashed lines in panels A-C and H-I indicate ideal compensation for the 45° cursor rotation. In panels D-F, they indicate the forced waiting times of 2.5 seconds in the WAIT_PLAN groups. Shaded error bands represent median absolute deviation (MADs).
In the explicit judgment test (Figure 2G), the FREE group estimated the rotation to be significantly smaller relative to the WAIT_PLAN1 group (meanFREE = 24.78°, sdFREE = 5.45°, meanWAIT_PLAN1 = 30.65°, sdWAIT_PLAN1 = 8.33°; V = 81.5, p = 0.036). Implicit aftereffects (Figure 2G) did not differ significantly between the groups (meanFREE = 9.99°, sdFREE = 3.81°, meanWAIT_PLAN1 = 9.35°, sdWAIT_PLAN1 = 3.67°; V = 179, p = 0.59).
Experiment 2
Experiment 1 showed that forcing participants to prolong their planning time before movement onset on each trial led to an increase in asymptotic learning. While this observation is consistent with our speed-accuracy tradeoff hypothesis, the WAIT_PLAN1 group also exhibited significantly larger amounts of explicit knowledge of the rotation, raising the possibility that this group shows complete asymptote simply because of larger amounts of accumulated explicit knowledge during training. To test this, in experiment 2 we manipulated when the additional waiting time occurred within a trial. If it was a matter of simply building a more elaborate representation of the perturbation by raising awareness and thus accumulating more explicit knowledge of the rotation, then additional processing time between movements should suffice to facilitate complete asymptotic learning. If, on the other hand, the pre-movement planning period was crucial, one would expect that adding time to the interval between the appearance of the target and the signal to initiate the movement would lead to better performance than adding time to the post-feedback interval, i.e. the time interval between the disappearance of terminal endpoint feedback and the onset of the next target. Experiment 2 tested this by contrasting asymptotic learning in a second group that had to wait for 2.5 s during movement planning (WAIT_PLAN2; replication of WAIT_PLAN1) with a group that had to wait for 2.5 s after feedback presentation before the next trial started (WAIT_ITI). In line with our speed-accuracy-hypothesis, inserting waiting time into the planning phase led to an asymptote not significantly different from 45° (V = 235, p = 0.28) whereas inserting the waiting time into the intertrial interval lead to an asymptote significantly less than 45° (V = 63, p = 0.019). Those two asymptotes were significantly different from each other (meanWAIT_PLAN2 = 46.33, sdWAIT_PLAN2 = 3.99; meanWAIT_ITI = 43.96, sdWAIT_ITI = 3.01; W = 311, p = 0.011) (Figure 2B).
Importantly, for explicit knowledge (Figure 2H), the temporal locus of the additional waiting time did not have a significant effect: Both groups appeared to accumulate equivalent amounts of explicit knowledge (meanWAIT_ITI = 30.53°, sdWAIT_ITI = 8.57°, meanWAIT_PLAN2 = 30.88°, sdWAIT_PLAN2 = 10.21°; W = 209, p = 0.79), but showed greater explicit estimations than the FREE group in experiment 1, whose trial structure did not contain any additional waiting interval (FREE ∼ WAIT_PLAN2: W = 85, p = 0.031; FREE ∼ WAIT_ITI: W = 93, p = 0.027). As for implicit aftereffects, both groups in experiment 2 achieved similar results (meanWAIT_ITI = 8.45°, sdWAIT_ITI = 4.77°, meanWAIT_PLAN2 = 7.63°, sdWAIT_PLAN2 = 3.87°; W = 214, p = 0.89).
Experiment 3
In the last experiment, we sought to account for the possibility that it is not time per se, but the increased participation of explicit processes that raises the level of asymptote. We thus instructed participants to verbally report their movement aim prior to movement execution trial-by-trial (Taylor et al., 2014), potentially priming the explicit component of adaptation. We reasoned that this procedure serves as an opportunity to replicate our findings in a procedure that requires active explicit engagement during the planning interval. Compensation for the rotation asymptoted around 46.63° (sd = 4.12°), which was significantly larger than 45° (V = 125, p = 0.045), suggesting that adaptation at asymptote was complete and, in fact, overcompensated for the rotation (Figure 2C).
Explicit judgements of required compensation (mean = 28.32, sd = 10.95) (Figure 2I) were significantly less than 45° (V = 0, p < 0.0002) but significantly greater than 0° (V = 170, p < 0.0002). Implicit aftereffects (mean = 9.38, sd = 3.4) were also significantly different from both 0°and 45° (V = 171, p < 0.0001, V = 0, p < 0.0001, respectively). If we assume that the explicit and implicit components are the two main elements in a fully additive model that generates adaptive behavior, the implicit component can be calculated by subtracting the hand position from the aim report (Figure 2L). Comparing those values to the posttest values, we do not find a significant difference, neither in explicit nor in the implicit component (W = 123, p = 0.22; W = 129, p = 0.31, respectively).
To test whether the reporting task influenced the outcome of the explicit judgement tests, we compared the posttest values between the AIM group and those of the other groups in experiments 1 and 2. There was a significant difference in the explicit judgements between the AIM group and the FREE group from experiment 1 (W = 197.5, p = 0.025) but none between the WAIT_PLAN and AIM (W = 160.5, p = 0.76). Across the AIM group and WAIT_PLAN2 and WAIT_ITI groups in experiment 2, there were no differences in the explicit judgement tests (W = 160, p = 0.57; W = 190.5, p = 0.85). Similar results were observed for the implicit aftereffects: Neither the FREE group, the WAIT_PLAN1 group from experiment 1, nor the WAIT_PLAN2 and WAIT_ITI groups had significantly different aftereffects relative to the AIM group (W = 140.5, p = 0.69; W = 167.5, p = 0.93; W = 227.5, p = 0.08; W = 265.5, p = 0.05, respectively). These results suggest that experimentally querying the explicit process of adaptation does not qualitatively alter the explicit/implicit learning balance but does act to improve the adaptation asymptote by slowing down planning.
Discussion
This study aimed to investigate whether previously reported findings of incomplete asymptotic learning in visuomotor adaptation tasks may be reframed as a consequence of a ubiquitous computational principle in human information processing: the tradeoff between the accuracy of a response and the speed with which it is generated. In line with this hypothesis, artificially prolonging the waiting period prior to movement onset facilitated asymptotic learning and appeared to eliminate residual errors. This benefit was specific to prolonging motor planning; that is, the time interval between the appearance of the visual target and the go-signal. Prolonging the interval between the disappearance of visual feedback and the start of the next trial did not provide the same benefit to learning. Our results provide support for a parsimonious explanation that time-consuming planning processes are primarily responsible for incomplete asymptotic adaptation.
Initially, the incomplete asymptote phenomenon was explained by state-space models of adaptation (Cheng & Sabes, 2006; Smith et al., 2006; Thoroughman & Shadmehr, 2000), according to which the adapted state reaches an equilibrium between learning from error and decaying towards baseline. As subsequent studies indicated that this model alone is insufficient for explaining incomplete asymptotic behavior, alternatives were proposed: For example, Vaswani and colleagues (Vaswani et al., 2015) showed that in a nonzero error clamp with zero feedback deviation, participants can be triggered to overcome the residual error. This led the authors to suggest that the contextual change elicited by the absence of motor variability triggered a change in the learning policy from error-based learning to exploration. They further suggested that a learning process driven by spatial error information suppresses exploration, in line with their previous reasoning that the presence of spatial error feedback suppressed reinforcement-based contributions to learning (Shmuelof et al., 2012). In our study, participants in all groups received spatial error feedback; thus, a potential suppression should have affected all groups equally. Our results therefore suggest that positional error feedback suppressing other learning mechanisms is not sufficient to explain the modulations in asymptote we observed.
Recent accounts have framed motor planning as a time-consuming optimization process from which a reduction in movement accuracy arises naturally when constraints are imposed (Al Borno, Vyas, V. Shenoy, & Delp, 2019). Our findings suggest that similar principles apply when one is intentionally choosing to perform a movement in another direction than the one implied by the target presented, and that learners naturally constrain their planning time even in seemingly unconstrained conditions.
Furthermore, Haith and colleagues (Haith, Pakpoor, & Krakauer, 2016) recently showed that movement preparation and initiation are independent i.e. that, instead of complete preparation triggering movement initiation, humans appear to determine a time for movement initiation based on when it expects planning to be completed. This view naturally implies the possibility to initiate a movement that has not been sufficiently prepared. The planning time chosen may therefore trade off the accuracy it expects planning to achieve within a given time and an urgency to move on (e.g. fueled by a desire to increase reward rate (Churchland et al., 2008; Cisek et al., 2009; Thura et al., 2012; Thura & Cisek, 2017)). In the wait conditions of our study, we delay movement initiation and enable planning to proceed further and arrive at a more accurate solution.
But why does incomplete planning result in consistent undershooting rather than overshooting, or merely in greater movement variability? We propose that parametric mental computations in visuomotor rotation tasks could explain the undershooting phenomenon: In visuomotor rotation tasks, participants’ reaction times increase linearly with the magnitude of the imposed rotation (Georgopoulos & Massey, 1987; McDougle & Taylor, 2019), reflecting a putative mental rotation process. Thus, in our hypothesis, under-compensation is the consequence of participants not fully completing a mental rotation of their planned reach trajectory. This view is further supported by the results of our third experiment, in which emphasizing the application of explicit aiming strategies prior to movement initiation led to qualitatively similar asymptotic learning as in the groups with prolonged planning intervals. Interestingly, delaying movement initiation not only caused full compensation, but typically induced overcompensation. We suggest that implicit processes superimposed onto an accurate explicit strategy caused drift, gradually moving the hand further in the direction of compensation (Mazzoni & Krakauer, 2006)
A new approach to the state-space model is that residual errors in adaptation paradigms are caused by implicit processes that tune the sensitivity to errors until it reaches the equilibrium with constant forgetting (Albert et al., 2019). The authors in this recent study manipulated the variability of the perturbation and found that residual errors increase with the perturbations’ variance. We note that, whereas our hypothesis could potentially be adapted to account for these variations in asymptote (e.g. experiencing perturbation variability could affect the benefit that learners expect from planning, and thus the time they spend on it), we did not consider this possibility a priori in hypothesis generation. However, we note that in one experiment, this study also showed a speed-accuracy tradeoff by obtaining larger residual errors when the reaction time is artificially shortened compared to free reaction times, regardless of the variance of perturbation. Thus, we argue, that additional planning time is an essential element in eliminating residual errors to achieve full compensation, though it need not be the only thing determining the exact asymptotic value.
Many of the canonical explanations for incomplete asymptote outlined above imply that it is a fundamental property of learning. Psychology and kinesiology traditionally distinguish learning effects from performance effects, where underlying knowledge can be identical in different cases, but retrieval processes in specific test conditions can lead to different performance profiles (Magill & Anderson, 2017; Schmidt & Lee, 2011). Whereas our experiments were not specifically designed to distinguish learning from performance effects, our findings suggest that both may contribute to incomplete asymptote in adaptation. Specifically, explicit knowledge as a measure of underlying learning was increased in the WAIT_PLAN1 group (experiment 1), suggesting that some of the benefit of longer planning times may come about by learners honing their explicit knowledge. However, the observation that explicit knowledge was similarly increased in both groups of experiment 2 indicates that this learning effect may be a non-specific consequence of longer ITIs. Future research can address these issues more specifically.
Lastly, we do not claim that other mechanisms affecting learning do not contribute to asymptotic behavior (Albert et al., 2019), or that a state-space model with gradual decay towards zero is generally invalid. For example, Brennan and Smith (Brennan & Smith, 2015) report results that support gradual decay when learning is followed by an error clamp; the mechanism we propose does not explain their results. What we suggest is that the eventual key for why the sensorimotor system does not overcome these asymptotic errors under “standard conditions” is the speed accuracy tradeoff. A key realization here is that the brain sets its motor planning time short of maximal task performance even when it is not pressed to react quickly. This combines common findings in perceptual and value-based decision-making, highlighting an important parallel between these two fields. We speculate that simple interventions, like explicitly prolonging reaction times, could improve performance in motor skill learning tasks in general.
Conclusion
In conclusion, we found that prolonging reaction times raised the level of asymptote in visuomotor adaptation tasks. Moreover, we propose that the under-compensation often observed in adaptation tasks may result from a hastened mental rotation process during the re-aiming of movements away from visual targets. Further research may investigate how planning time influences both explicit and implicit learning processes.





{kind=link}
{kind=link}