

Abstract
Wikipedia is one of the main sources of free knowledge on the Web. During the first few months of the pandemic, over 4,500 new Wikipedia pages on COVID-19 have been created and have accumulated close to 250M pageviews by early April 2020.1 At the same time, an unprecedented amount of scientific articles on COVID-19 and the ongoing pandemic have been published online. Wikipedia’s contents are based on reliable sources, primarily scientific literature. Given its public function, it is crucial for Wikipedia to rely on representative and reliable scientific results, especially so in a time of crisis. We assess the coverage of COVID-19-related research in Wikipedia via citations. We find that Wikipedia editors are integrating new research at an unprecedented fast pace. While doing so, they are able to provide a largely representative coverage of COVID-19-related research. We show that all the main topics discussed in this literature are proportionally represented from Wikipedia, after accounting for article-level effects. We further use regression analyses to model citations from Wikipedia and show that, despite the pressure to keep up with novel results, Wikipedia editors rely on literature which is highly cited, widely shared on social media, and has been peer-reviewed.
1 Introduction
Alongside the primary health crisis, the COVID-19 pandemic has been recognized as an information crisis, or an “infodemic” [62, 11, 21]. Widespread misinformation [53] and low levels of health literacy [40] are two of the main issues. In an effort to deal with them, the World Health Organization maintains a list of relevant research updated daily [64], as well as a portal to provide information to the public [2]; similarly does the European Commission [3], and many other countries and organizations. The need to convey accurate, reliable and understandable medical information online has never been so pressing.
Wikipedia plays a fundamental role as a public source of information on the Web, striving to provide “neutral” and unbiased contents [34]. Wikipedia is particularly important as go-point to access trusted medical information [53, 51]. Fortunately, Wikipedia biomedical articles have been repeatedly found to be highly visible and of high quality [5, 31]. Wikipedia’s verifiability policy mandates that readers can check the sources of information contained in Wikipedia, and that reliable sources should be secondary and published.2 These guidelines are particularly strict with respect to biomedical contents, where the preferred sources are, in order: systematic reviews, reviews, books and other scientific literature.3
The COVID-19 pandemic has put Wikipedia under stress with a large amount of new, often non-peer-reviewed research being published in parallel to a surge in interest for information related to the pandemic [16]. The response of Wikipedia’s editor community has been fast: since March 17 2020, all COVID-19-related Wikipedia pages have been put under indefinite sanctions entailing restricted edit access, to allow for a better vetting of their contents.4 In parallel, a WikiProject COVID-19 has been established and a content creation campaign is ongoing [16, 22].5 While this effort is commendable, it also raises questions on the capacity of editors to find, select and integrate scientific information on COVID-19 at such a rapid pace, while keeping quality high. In Figure 1 we show the time in number of months from publication to a first citation from Wikipedia for a large set of COVID-19-related articles (see Section 3). In 2020, this time has become negative on average: articles on COVID-19 are frequently cited in Wikipedia even before their official publication date, based on early access versions of articles.
In this work, we pose the following general question: Is Wikipedia relying on a representative and reliable sample of COVID-19-related research? We break this question down into the following two research questions:
RQ1: Is the literature cited from Wikipedia representative of the broader topics discussed in COVID-19-related research?
RQ2: Is Wikipedia citing COVID-19-related research during the pandemic following the same inclusion criteria adopted before and in general?

Number of months elapsed from publication to the first Wikipedia citation (scatterplot binned by year) of COVID-19-related research. In 2020, the average number of months from (official) publication to the first citation from Wikipedia has become negative, due to the effect of early releases by some journals. Also see Figure7.
We approach the first question by clustering COVID-19-related publications using text and citation data, and comparing Wikipedia’s coverage of different clusters before and during the pandemic. The second question is instead approached using regression analysis. In particular, we model whether an article is cited from Wikipedia or not, and how many citations it receives from Wikipedia. We then again compare results for articles cited before and during the pandemic, and with previous art.
Our main finding is that Wikipedia contents rely on representative and high-impact COVID-19-related research. (RQ1) During the past few months, Wikipedia editors have successfully integrated COVID-19 and coronavirus research, keeping apace with the rapid growth of related literature by including (a representative sample of) it. (RQ2) The inclusion criteria used by Wikipedia editors to integrate COVID-19-related research during the pandemic are consistent with those from before, and appear reasonable in terms of source reliability. Specifically, editors prefer articles from specialized journals over mega journals or pre-prints, and focus on highly cited and/or highly socially visible literature. Some altmetrics such as Twitter shares, mentions in news and blogs, Mendeley readers are complementing citation counts from the scientific literature as an indicator of impact positively correlated with citations from Wikipedia. After controlling for these article-level impact indicators, and for publication venue, time and size-effects, there is no indication that the topic of research matters with respect to receiving citations from Wikipedia, signaling that Wikipedia is currently not over nor under-relying on any specific COVID-19-related scientific topic.
2 Related work
Wikipedia articles are created, improved and maintained by the efforts of the community of volunteer editors [44, 10], and they are used in a variety of ways by a wide user base [50, 29, 42]. The information Wikipedia contains is generally considered to be of high-quality and up-to-date [44, 23, 17, 27, 43, 5, 51], notwithstanding margins for improvement and the need for constant knowledge maintenance [10, 30, 15].
Following Wikipedia’s editorial guidelines, the community of editors cre-ates contents often relying on scientific and scholarly literature [38, 18, 6], and therefore Wikipedia can be considered a mainstream gateway to scientific information [28, 19, 30, 48, 32, 42]. Unfortunately, few studies have considered the representativeness and reliability of Wikipedia’s scientific sources. The evidence on what scientific and scholarly literature is cited in Wikipedia is slim. Early studies point to a relative low overall coverage, indicating that between 1% and 5% of all published journal articles are cited in Wikipedia [45, 49, 63]. Previous studies have shown that the subset of scientific literature cited from Wikipedia is more likely on average to be published on popular, high-impact-factor journals, and to be available in open access [37, 55, 6].
Wikipedia is particularly relevant as a means to access medical information online [28, 19, 51, 53]. Wikipedia medical contents are of very high quality on average [5] and are primarily written by a core group of medical professionals part of the nonprofit Wikipedia Medicine [48]. Articles part of the WikiProject Medicine “are longer, possess a greater density of external links, and are visited more often than other articles on Wikipedia” [31]. Perhaps not surprisingly, the fields of research that receive most citations from Wikipedia are “Medicine (32.58%)” and “Biochemistry, Genetics and Molecular Biology (31.5%)” [6]; Wikipedia medical pages also contain more citations to scientific literature than the average Wikipedia page [32]. Margins for improvement remain, as for example the readability of medical content in Wikipedia remains difficult for the non-expert [9]. Given Wikipedia’s medical contents high quality and high visibility, our work is concerned with understanding whether the Wikipedia editor community has been able to maintain the same standards for COVID-19-related research.
3 Data and Methods
3.1 COVID-19-related research
COVID-19-related research is not trivial to delimit [13]. Our approach is to consider several public and regularly-updated lists of publications:
The COVID-19 Open Research Dataset (CORD-19): a collection of COVID-19 and coronavirus related research, including publications from PubMed Central, bioRxiv and medRxiv [61].
The World Health Organization Database [4].
The Dimensions COVID-19 Publications list [1].

COVID-19-related literature over time.
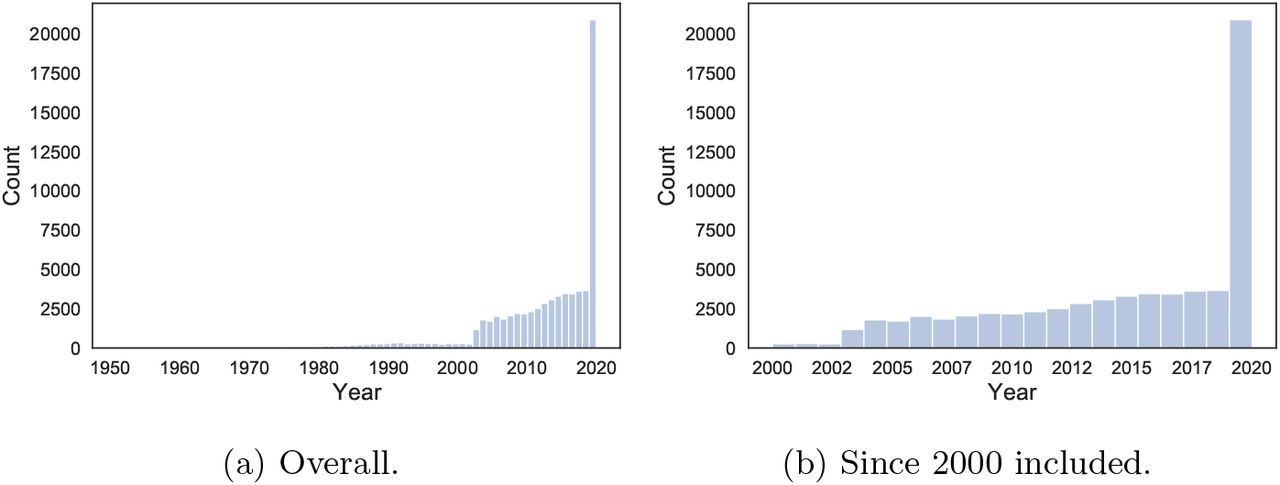
Publications from these three lists are merged, and duplicates removed using publications identifiers, including DOI, PMID, PMCID, Dimensions ID. Publications without at least one identifier among these are discarded. As of April 24 2020, the resulting list of publications contains 69,969 entries with a valid identifier, of which 20,841 have been released in 2020, as it can be seen from Figure 2. The research on corovaniruses, and therefore the accumulation of this corpus over time, has been clearly influenced by the SARS (2003+), MERS (2012+) and COVID-19 outbreaks. We use this list of publications to represent COVID-19 and coronavirus research in what follows. More details are given in the online repositories.

Timing of new citations from Wikipedia, and publication years of the articles they refer to. See Figure 8 for the full timeline.
3.2 Auxiliary data sources
In order to study Wikipedia’s coverage of this list of COVID-19-related publications, we use data from Altmetric [47, 39]. Altmetric provides Wikipedia citation data relying on known identifiers.6 Despite this limitation, Altmetric data have been previously used to map Wikipedia’s use of scientific articles [63, 58, 6], especially since citations from Wikipedia are considered a possible measure of impact [52, 25]. Publications from the full list above are queried using the Alt-metric API by DOI or PMID. In this way, 43,561 publications could be retrieved. After merging for duplicates by summing Altmetric indicators, we have a final set of 40,866 distinct COVID-19-related publications with an Altmetric entry.
Furthermore, we use data from Dimensions [20, 33] in order to get citation counts for COVID-19-related publications. The Dimensions API is also queried by DOI and PMID, resulting in 64,040 matches. All auxiliary data sources have been queried on April 24 2020 too.
3.3 Methods
We detail here the experimental choices made for a clustering analysis using publication text and citation data. Details on regression analyses are, instead, given in the corresponding section.
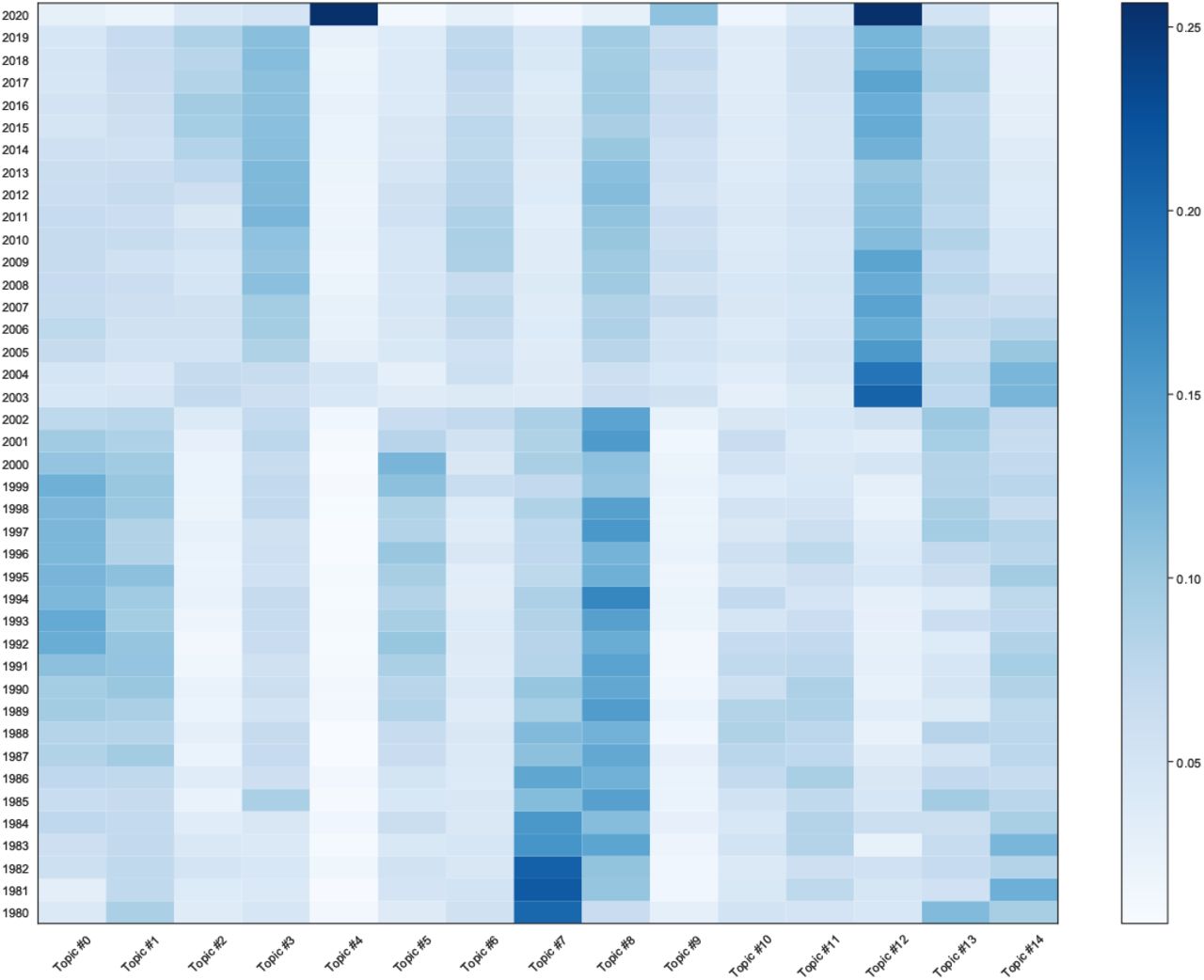
Text-based clustering of publications was performed in two ways: topic modelling and k-means relying on SPECTER embeddings. Both methods made use of the titles and abstracts of available publications, by concatenating them into a single string. We detected 66,915 articles in English, out of 69,969 total articles (−3054 over total). Of these, 13,852 have no abstract, thus we only used their title. Before performing topic modelling, we applied a pre-processing pipeline using scispaCy’s en_core_sci_md model [36] to convert each document into a bag-of-words representation, which includes the following steps: entity detection and inclusion in the bag-of-words for entities strictly longer than one token; lem-matisation; removal of (isolated) punctuation, stopwords and tokens composed of a single character; inclusion of frequent bigrams. SPECTER embeddings were instead retrieved from the API without any pre-processing.7 We then trained and compared topic models using Latent Dirichlet Allocation (LDA) [8], Correlated Topic Models (CTM) [7], Hierarchical Dirichlet Process (HDP) [54] and a range of topics between 5 and 50. We found similar results in terms of topic contents and in terms of their Wikipedia coverage (see Section 4) across models and over multiple runs, and a reasonable value of the number of topics to be between 15 and 25 from a topic coherence analysis [35]. Therefore, in what follows we discuss an LDA model with 15 topics.8 The top words for each topic of this model are given in the SI, while topic intensities over time are plotted as a heat map in Figure 9.
SPECTER is a novel method to generate document-level embeddings of scientific documents based on a transformer language model and the network of citations [12]. SPECTER does not require citation information at inference time, and performs well without any further training on a variety of tasks. We embed every paper and cluster them using k-means with k = 20. The number of clusters was established using the elbow and the silhouette methods; different values of k could well be chosen, we again decided to pick the smallest reasonable value of k.
We then turned our attention to citation network clustering. We constructed a bibliographic coupling citation network [24] based all publications provided by Dimensions and with references; these amount to 54,293. Edges were weighted using fractional counting [41], hence dividing the number of references in common between any two publications by the length of the union of their reference lists (thus, the max possible weight is 1.0). We only used the giant weakly connected component, which amounts to 53,131 nodes (−1162 over total) and 21,078,192 edges with a median weight of 0.0156. We clustered the citation net-work using the Leiden algorithm [60] with a resolution parameter of 0.05 and the Constant Potts Model (CPM) quality function [59]. With this configuration, we found that the largest 13 clusters account for half the nodes in the network, and the largest cluster is composed of circa 7,000 nodes.
4 Results
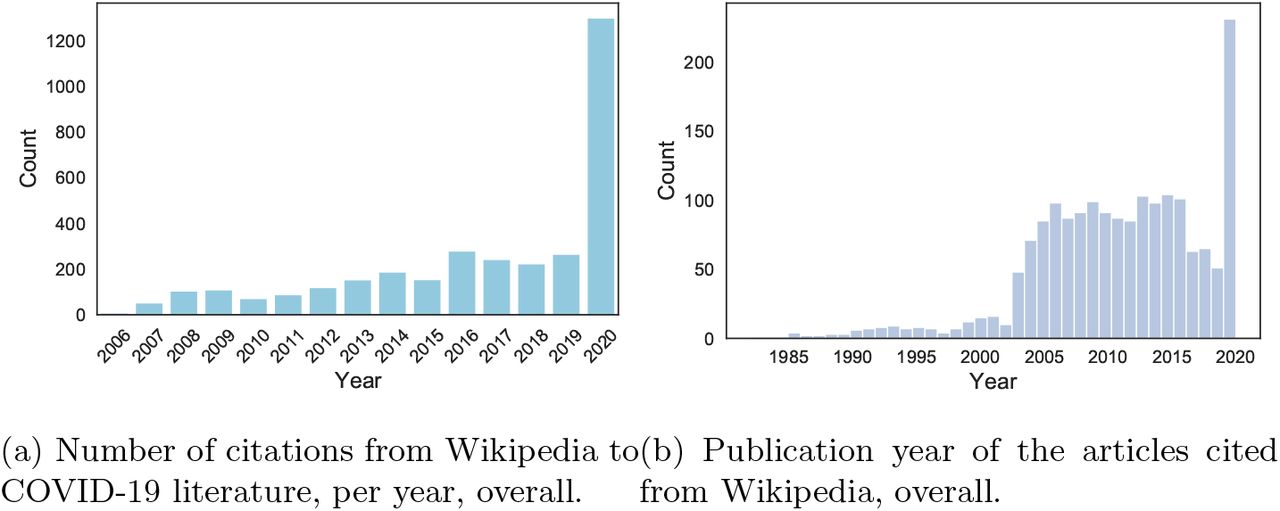
An intense editorial work was carried out over the early weeks of 2020 in order to include scientific information on COVID-19 and coronaviruses into Wikipedia [22]. From Figure 3a, we can appreciate the surge in new citations added from Wikipedia to COVID-19 research. Importantly, these citations were not only added to cope with the growing amount of new literature, but also to fill gaps by including literature published before 2020, as shown in Figure 8b. The total fraction of COVID-19-related articles that are cited at least once from Wikipedia over the total is 3.1%. Yet, this number is uneven over languages and over time. Articles in English have a 3.2% chance of being cited from Wikipedia, while articles in other languages only a 0.036% chance. To be sure, the whole corpus is English dominated, as we discussed above. This might be an artefact of the coverage of the data sources, as well as the way the corpus was assembled. The coverage of articles over time is instead given in Figure 4, starting from 2003 when the first surge of publications happens due to SARS. We can appreciate that the coverage seems to be uneven, and less pronounced for the past few years (2017-2020), yet this needs to be considered in view of the high growth of publications in 2020. Hence, while 2020 is a relatively low-coverage year (2.2%), it is already the year with the most publications cited from Wikipedia in absolute number (Figure 8b).

Fraction of COVID-19-related articles cited from Wikipedia per year, from 2003 included.
Citation distributions are skewed in Wikipedia as they are in science more generally. Some articles receive a high number of citations from Wikipedia and some Wikipedia articles make a high number of citations to COVID-19-related literature. Table 1 lists the top 20 Wikipedia articles by number of citations to COVID-19-related research. These articles, largely in English, primarily focus on the recent pandemic and coronaviruses/viruses from a virology perspective, as already highlighted in a study by the Wikimedia Foundation [22]. Table 2 reports instead the top 20 journal articles cited from Wikipedia. These also follow a similar pattern: articles published before 2020 focus on virology and are made of a high proportion of review articles. The top cited article, for example, deals with virus taxonomy. Articles published in 2020, instead, have a focus on the ongoing pandemic, its origins, as well as its epidemiological and public health aspects. As we see next, this strongly aligns with the general trends of COVID-19-related research over time.
Top-20 citing Wikipedia articles.
Top-20 cited journal articles. The first column gives the number of distinct citing Wikipedia articles, while the last one gives the number of citations to these articles from the scientific literature (data from Dimensions).
In order to discuss research trends in our CORD-19-related corpus at a higher level of granularity, we grouped the 15 topics from the LDA topic model into seven macrotopics and labelled them as follows:
Coronaviruses: topics 2, 4; this macrotopic includes research explicitly on coronaviruses (COVID-19, SARS, MERS) from a variety of perspectives (virology, epidemiology, intensive care, historical unfolding of outbreaks).
Public health and epidemics: topics 9, 12; research on global health issues, healthcare, epidemiology, including modelling the transmission and spread of pathogens.
Transmission: topics 1, 7, 14; research on the origin and transmission of viruses from animals to humans and among humans.
Molecular biology: topics 0, 5, 8; research on the genetics and biology of viruses.
Respiratory diseases: topic 6; research on respiratory diseases (pneumonia, influenza), their detection and treatment.
Immunology: topics 3, 10; research on vaccines, drugs, therapies.
Clinical medicine: topics 11, 13; research on intensive care, hospitalization and clinical trials.
The grouping is informed by agglomerative clustering based on the Jensen-Shannon distance between topic-word distributions (Figure 12). To be sure, the labelling is a simplification of the actual publication contents. It is also worth considering that topics overlap substantially. The COVID-19 research corpus is dominated by literature on coronaviruses, public health and epidemics, largely due to 2020 publications. COVID-19-related research did not accumulate uniformly over time. We plot the relative (yearly mean, Figure 10a) and absolute (yearly sum, Figure 10b) macrotopic intensity. From these plots, we confirm the periodisation of COVID-19-related research as connected to known outbreaks. Outbreaks generate a shift in the attention of the research community, which is apparent when we consider the relative macrotopic intensity over time in Figure 10a. The 2003 SARS outbreak generated a shift associated with a raise of publications on coronaviruses and on the management of epidemic outbreaks (public health, epidemiology). Stable macrotopics instead include molecular biology, viral transmission, immunology and clinical medicine. A similar shift is again happening, at a much larger scale, during the current COVID-19 pandemic. When we consider the absolute macrotopic intensity, which can be interpreted as the number of articles on a given topic (Figure 10b), we can appreciate how scientists are mostly focusing on topics related to public health, epidemics and coronaviruses (COVID-19) during these first months of the current pandemic.
4.1 RQ1: Wikipedia coverage of COVID-19-related research
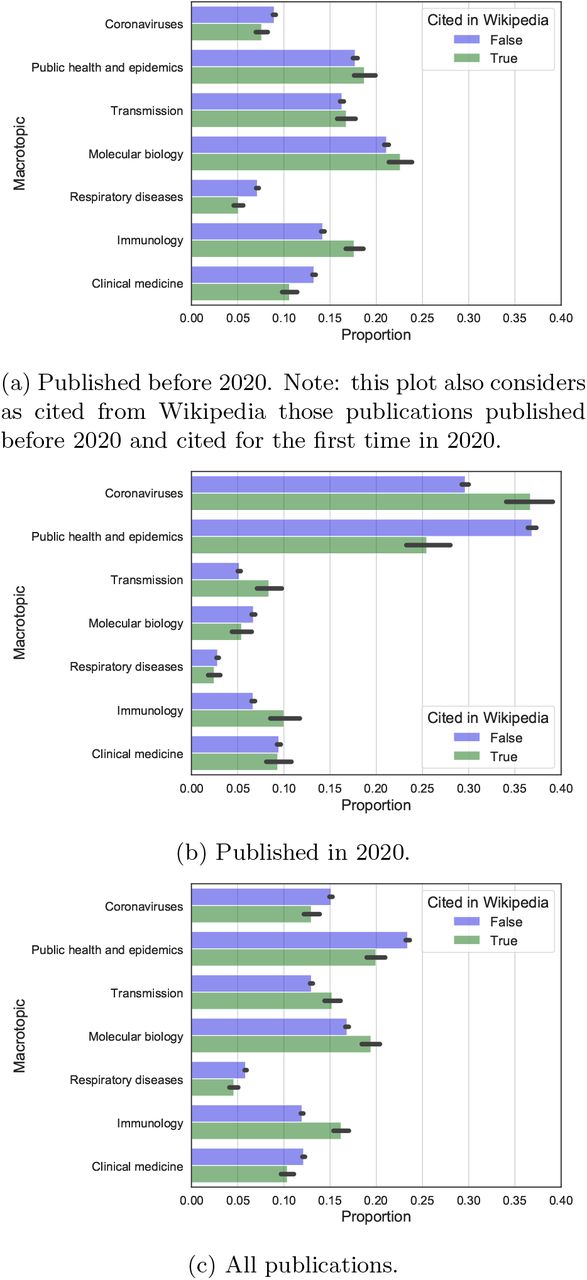
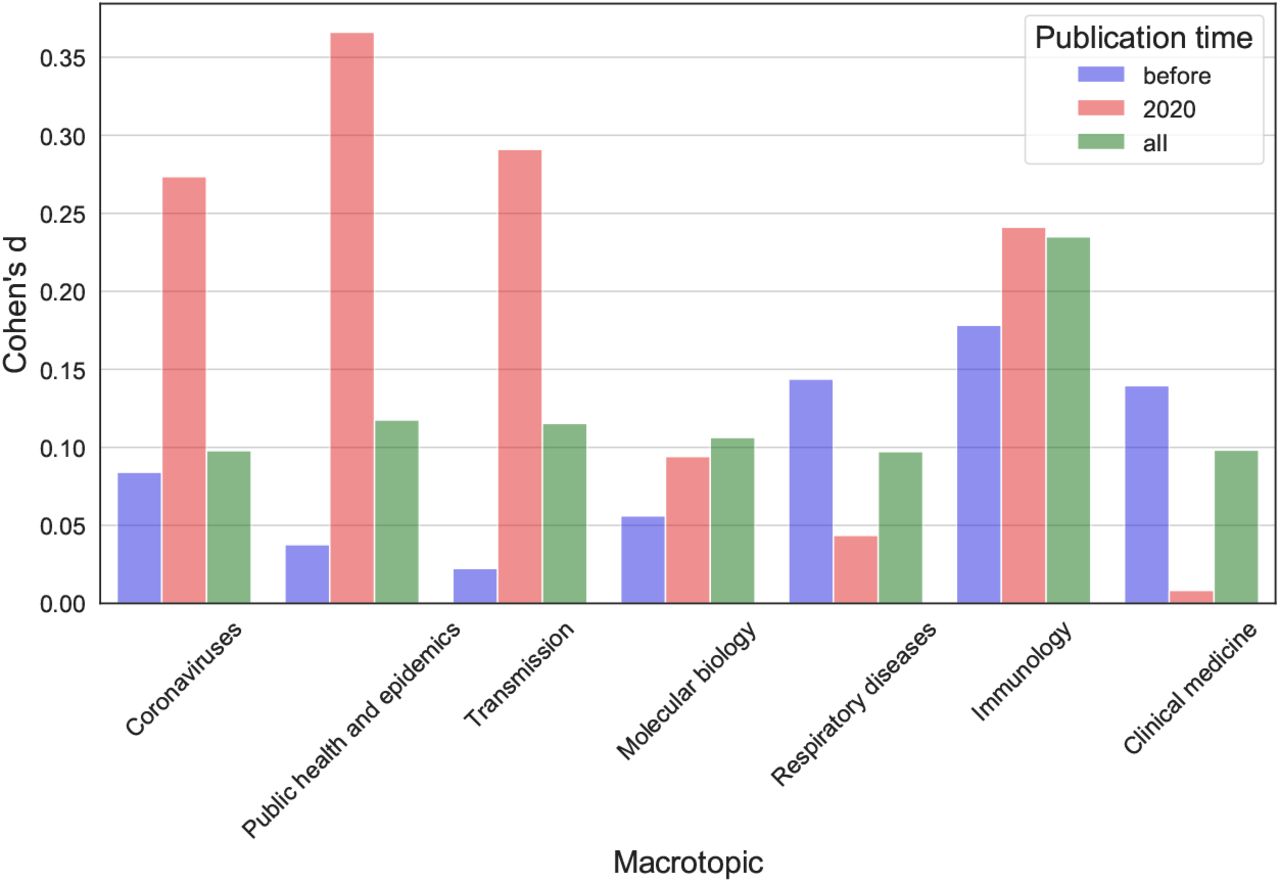
We address here our first research question: Is the literature cited from Wikipedia representative of the broader topics discussed in COVID-19-related research? We start by comparing the macrotopic coverage of articles cited from Wikipedia with those which are not. In Figure 5, three plots are provided: the macrotopic intensity of articles published before 2020 (Figure 5a), in 2020 (Figure 5b) and overall (Figure 5c). The macrotopic intensity is averaged and 95% confidence intervals are provided. From Figure 5c we can see that Wikipedia seems to cover COVID-19-related research well. The macrotopics on immunology, molecular biology and transmission seem slightly over represented, where clinical medicine, coronaviruses, public health and epidemics are slightly under represented. A comparison between publications from 2020 and from before highlights further trends. In particular, in 2020 Wikipedia editors have focused more on recent literature on coronaviruses, thus directly related to COVID-19 and the current pandemic, and proportionally less on literature on public health and epidemics, which is also dominating 2020 publications. The traditional slight over representation of immunology and viral transmission literature persists. Detailed Kruskal-Wallis H test statistics and Cohen’s d effect sizes are provided in the SI (Figure 13 and Tables 3, 4, 5). While distributions are significantly different for most macrotopics and periodisations, the effect sizes are always small or very small. The coverage of COVID-19-related literature from Wikipedia appears therefore to be reasonably balanced from this first analysis, and to remain so in 2020. The topical differences we found, especially around coronaviruses and the current COVID-19 outbreak, might in part be explained by the criterion of notability which led to the creation or expansion of Wikipedia articles on the ongoing pandemic.9

Test statistics for macrotopic intensities of articles cited in Wikipedia or not, limited to articles published before 2020. In W: cited in Wikipedia; Not in W: not cited in Wikipedia; KWH: Kruskal-Wallis H test.
Test statistics for macrotopic intensities of articles cited in Wikipedia or not, limited to articles published in 2020. In W: cited in Wikipedia; Not in W: not cited in Wikipedia; KWH: Kruskal-Wallis H test.
Test statistics for macrotopic intensities of articles cited in Wikipedia or not; all publications. In W: cited in Wikipedia; Not in W: not cited in Wikipedia; KWH: Kruskal-Wallis H test.
A complementary way to address the same research question is to investigate Wikipedia’s coverage of publication clusters. We consider here both SPECTER k-means clusters and bibliographic network clusters. While we use all 20 SPECTER clusters, we limit ourselves to the top-n network clusters which are necessary in order to cover at least 50% of the nodes in the network. In this way, we consider 13 clusters for the citation network, all of size above 800. In Figure 6 we plot the % of articles cited from Wikipedia per cluster, and the clusters size in number of publications they contain. There is a general size effect, more pronounced for the SPECTRE clustering (Figure 6a), by which larger clusters are more represented than smaller clusters. When considering the citation network clustering solution, this applies to the two largest clusters, but not to the rest (Figure 6b).

Proportion of articles cited from Wikipedia (y axis) per cluster size (x axis).

Number of months elapsed from publication to the first Wikipedia citation. Alternative views on Figure 1.
Timing of new citations from Wikipedia, and publication years of the articles they refer to.

Heatmap of topic intensities over time.

Macrotopic intensities over time.
When we characterise clusters using macrotopic intensities, some clear patterns emerge. Starting with SPECTER k-means clusters, the most cited clusters are number 6 (main macrotopics: molecular biology), 8 (main macrotopics: coronaviruses and public health, especially focusing on COVID-19 characteristics, detection and treatment) and 1 (main macrotopics: transmission, with an emphasis on genetics). The least cited clusters include number 18 (containing pre-prints from Research Square) and 5 (focused on the social sciences, and especially economics, e.g., from SSRN journals). Considering citation network clusters, the largest and most cited are number 0 (containing research on all coronaviruses from a variety of perspectives with a good balance among macrotopics) and 1 (with publications exclusively from 2020 on the current pandemic). The other clusters are smaller and hence more specialized. For example, at the two extremes we have cluster 11 (highly cited, mainly containing literature on viral infectious diseases) and cluster 10 (lowly cited, focused on animal to human transmission and immunology). The reader can explore all clusters using the accompanying repository.
We have seen so far that Wikipedia relies on a reasonably representative sample of COVID-19-related literature, when assessed using topic models. During 2020, the main effort of editors has focused on catching-up with abundant new research (and some backlog) on the ongoing pandemic and, to a lower extent, on public health and epidemiology literature. When assessing coverage using different clustering methods, we find a size effect by which larger clusters are proportionally more cited from Wikipedia. Yet, we also find that, in particular with citation network clusters, smaller clusters can be either highly or lowly cited from Wikipedia on average. Lastly, we find an under representation of pre-print and social science research using text-based clustering, which we cannot find using citation network clustering. Despite this overall positive result, differences in coverage persist. In the next section, we further assess whether these differences can be explained away by considering article-level measures of impact.
4.2 RQ2: Predictors of citations from Wikipedia
In this section, we address our second research question: Is Wikipedia citing COVID-19-related research during the pandemic following the same quality criteria adopted before and in general? We use regression analysis in two forms: a logistic regression to model if a paper is cited from Wikipedia or not, and a linear regression to model the number of citations a paper receives from Wikipedia. While the former model captures the suitability of an article to provide encyclopedic evidence, the latter captures its relevance to multiple Wikipedia articles.
Dependent variables
Wikipedia citation counts for each article are taken from Altmetric. If this count is of 1 or more, an article is considered as cited from Wikipedia. We consider citation counts from Altmetric at the time of the data collection for this study. We focus on the articles with a match from Dimensions, and consider an article to have zero citations from Wikipedia if it is not found in the Altmetric database. Of 64,040 articles, 2175 (3.4%) are cited from Wikipedia.
Independent variables
We focus our study on three groups of independent variables at the article level capturing impact, topic and timing respectively. Previous studies have shown how literature cited from Wikipedia tends to be published in prestigious journals and available in open access [37, 55, 6]. We are interested to assess some of these known patterns for COVID-19-related research, to complement them by considering citation counts and the topics discussed in the literature, and eventually to understand whether there has been any change in 2020.
Article-level variables include citation counts from Dimensions and a variety of altmetric indicators [47] which have been found to correlate with later citation impact of COVID-19 research [26]. Altmetrics include the number of: Mendeley readers, Twitter interactions (unique users), Facebook shares, mentions in news and blog posts (summed due to their high correlation), mentions in policy documents; the expert ratio in user engagement10. We also include the top-20 publication venues by number of articles in the corpus using dummy coding, taking as reference level a generic category ‘other’ which includes articles from all other venues. It is worth clarifying that article-level variables were also calculated at the time of the data collection for this study. This might seem counter-intuitive, especially for the classification task, as one might prefer to calculate variables at the time when an article was first cited from Wikipedia. We argue that this is not necessary, since Wikipedia can always be edited and citations removed as easily as added. As a consequence, a citation from Wikipedia (or its absence) is a continued rather than a discrete action, justifying calculating all counts at the same time for all articles in the corpus.
Topic-level variables capture the topics discussed in the articles, as well as their relative importance in terms of size (size-effects). They include the macrotopic intensities for each article, the size of the SPECTER cluster an article belongs to, and the size of its bibliographic coupling network cluster (for the 13 largest clusters with more than 800 articles each, setting it to zero for articles belonging to other clusters. In this way, the variable accounts for both size and thresholding effects). Cluster identities for both SPECTRE and citation network clusters were also tested but did not add contribute significantly to the models. Several other measures were considered, such as the semantic centrality of an article to its cluster centroid (SPECTER k-means) and network centralities, but since these all strongly correlate to size indicators they were discarded.
Lastly, we include the year of publication using dummy coding and 2020 as reference level. Several other variables were tested. The proposed selection removes highly correlated variables while preserving the information required by the research question. The Pearson’s correlations for the selected variables are shown in Figure 11. More details, along with a full profiling of variables, are provided in the accompanying repository.

Heatmap of regression variables correlations (Pearson’s).

Agglomerative clustering dendrogram over topics, based on Jensen-Shannon distances. Considering a cut at 1.1, the left-most cluster (topics 2,4,13) focuses on coronaviruses and related clinical medicine; next is a cluster with topics related to other respiratory diseases (pneumonia, influenza), their transmission and treatment (topics 6,7,11); next is a cluster on molecular biology studies on viruses and their transmission, in particular from animals to humans (topics 0,1,5,8,14); lastly, on the right, is a cluster on public health, epidemics and immunology (topics 3,9,10,12).

Cohen’s d effect statistic for macrotopic intensity differences between articles cited in Wikipedia and not. Publications published before 2020, in 2020, and overall are considered. See Table 3, 4 and 5. Effect sizes are considered very small when below 0.2, small when below 0.5 and medium when below 0.8.

Some variables used for regression analyses. The plots distinguish variable values for articles cited from Wikipedia (green) or not (blue).
Model
We consider two models: a Logistic model on being cited from Wikipedia (1) or not (0) and an Ordinary Least Squares (OLS) model on citation counts from Wikipedia. Both models use the same set of independent variables and the following transformations:

All count variables are transformed by adding one and taking the natural logarithm, while the remaining variables are either indicators or range between 0 and 1 (such as macrotopic intensities, beginning with a tm_ appendix; tm.phe is ‘public health and epidemics’). OLS models including log transform and the addition of 1 for count variables such as citation counts, have been found to perform well in practice when compared to more involved alternatives [57, 56]. Furthermore, all missing values were set to zero, except for the publication year, venue (journal) and macrotopic intensities; removing those rows with missing values instead, yielded similar results.
Discussion
We discuss results for three models: two Logistic regression models one on articles published and first cited up to and including in 2020, and one on articles published and first cited up to an including 2019. The 2019 model only considers articles published in 2019 or earlier and cited for the first time from Wikipedia in 2019 or earlier, or articles never cited from Wikipedia, discarding articles published in 2020 or cited from Wikipedia in 2020 irrespective of their publication time. We also discuss an OLS model predicting (the log of) citation counts including all data up to and including 2020. We do not discuss a 2019 OLS model since it would require Wikipedia citation counts calculated at the end of 2019, which were not available to us. Regression tables for these three models are provided in the SI, Section 5, while Figure 14 shows the distribution of some variables distinguishing between articles cited from Wikipedia or not. Logistic regression tables provide marginal effects, while the OLS table provides the usual coefficients. The actual number of datapoints used to fit each model, after removing those which contained any null value, is given in the regression tables.
Considering the Logistic models first, we can show some significant effects.11 First of all, the year of publication is always negatively correlated with being cited from Wikipedia, compared with the reference category 2020. This seems largely due to publication size-effects, since the fraction of 2020 articles cited from Wikipedia is quite low (see Figure 4. The 2019 model indeed shows positive correlations for all years when compared to the reference category 2019, and indeed 2019 is the year with lowest coverage since 2000. Secondly, some of the most popular venues are negatively correlated with citations from Wikipedia, when compared to an ‘other’ category (which includes all venues except the top 20). In the 2020 model, these less-cited-from-Wikipedia venues include pre-print servers (medRxiv in particular), mega-journals (PLoS One) and social sciences (SSRN). Positive correlations occur for few other specialized venues, such as Antiviral Research, The Lancet and Virology. When we consider indicators of impact, we see a significant positive effect for citation counts, Mendeley readers, Twitter, news and blogs mentions; we see instead no effect for policy document mentions and Facebook engagements. This is consistent in the 2019 model, except for smaller effects on citation counts and higher effects of Mendeley readers. This result, on the one hand, highlights the importance of academic indicators of impact such as citations, and on the other hand suggests the possible complementarity of altmetrics in this respect. Since certain altmetrics can accumulate more rapidly than citations [14], they could complement them effectively when needed [26]. Furthermore, the expert ratio in altmetrics engagement is negatively correlated with being cited from Wikipedia in 2020. This might be due to the high altmetrics engagement with COVID-19 research in 2020, but it could also hint at the possibility that social media impact need not be driven by experts in order to be correlated with scientific impact. We can further see how cluster size-effects are positively correlated with being cited from Wikipedia in 2020, and especially so for SPECTER clusters, but not in 2019. Lastly, we can see that macrotopic intensities are never correlated with being cited from Wikipedia in either model, underlining that Wikipedia appears to be proportionally representing all COVID-19-related research and that residual topical differences in coverage are due to article-level effects.
The OLS 2020 model largely confirms these results, except that mentions in policy documents and Facebook engagements become here positively correlated with the number of citations from Wikipedia. It is important to underline that, for all these results, there is no attempt to establish causality. For example, the positive correlation between the number of Wikipedia articles citing a scientific article and the number of policy documents mentioning it, might be due to policy document editors using Wikipedia, Wikipedia editors using policy documents, both or neither. The fact is, more simply, that some articles are picked up by both.
5 Conclusion
The results of this study, while preliminary and given as the pandemic is still ongoing, provide some reassuring evidence. It appears that Wikipedia is well-able to keep track of COVID-19-related research. Of 64,040 articles in our corpus, 2175 (3.4%) are cited from Wikipedia: a similar share to what found in previous studies. Wikipedia editors are relying on scientific results representative of the several topics included in a large corpus of COVID-19-related research. They have been effectively able to cope with new, rapidly-growing literature. The minor discrepancies in coverage that persist, with slightly more Wikipedia-cited articles on topics such as molecular biology and immunology and slightly fewer on coronaviruses and public health, are fully explained away by article-level effects. Wikipedia editors rely on impactful and visible research, as evidenced by largely positive citation and altmetrics correlations. Importantly, Wikipedia editors also appear to be following the same inclusion standards in 2020 as before: in general, they rely on specialized and highly-cited results from reputed journals, avoiding e.g., pre-prints.
The main limitation of this study is that it is purely observational, and thus does not explain why some articles are cited from Wikipedia or not. While in order to assess the coverage of COVID-19-related research from Wikipedia this is of secondary importance, it remains relevant when attempting to predict and explain it. A second limitation is that this study is based on citations from Wikipedia to scientific publications, and no Wikipedia content analysis is performed. Citations to scientific literature, while informative, do not completely address the interrelated questions of Wikipedia’s knowledge representativeness and reliability. Therefore, some directions for future work include comparing Wikipedia coverage with expert COVID-19 review articles, as well as studying Wikipedia edit and discussion history in order to assess editor motivations. Another interesting direction for future work is the assessment of all Wikipedia citations to any source from COVID-19 Wikipedia pages, since here we only focused on the fraction directed at COVID-19-related scientific articles. Lastly, future work can address the engagement of Wikipedia users with cited COVID-19-related sources.
Wikipedia is a fundamental source of free and unbiased knowledge, open to all. The capacity of its editor community to quickly respond to a crisis and provide high-quality contents is, therefore, critical. Our results here are encouraging in this respect.
Data and code availability
All the analyses can be replicated using code and following the instructions given in the accompanying repository: https://github.com/Giovanni1085/covid-l9_wikipedia. The preparation of the data follows the steps detailed in this repository instead: https://github.com/CWTSLeiden/cwts_covid [13]. Analyses based on Altmetric and Dimensions data require access to these services.
SI
Topics
Refer to Figures 9 and 10 for topic and macrotopic intensities over time. See Figure 12 for the topic clustering which informs their grouping into macrotopics. The macrotopic is given next to the topic number, for reference.
Topic #0, Molecular biology: “protein”, “domain”, “membrane”, “structure”, “binding”, “receptor”, “site”, “fusion”, “bind”, “protease”, “activity”, “interaction”, “acid”, “glycoprotein”, “complex”, “ace2”, “residue”, “form”, “entry”, “cleavage”.
Topic #1, Transmission: “sequence”, “virus”, “strain”, “gene”, “calf”, “analysis”, “isolate”, “genome”, “specie”, “bat”, “human”, “genetic”, “region”, “identify”, “ibv”, “mutation”, “host”, “study”, “variant”, “different”.
Topic #2, Coronaviruses: “respiratory”, “infection”, “study”, “year”, “case”, “child”, “age”, “mers-cov”, “risk”, “associate”, “high”, “associated with”, “patient”, “Middle”, “rate”, “factor”, “illness”, “95_ci”.
Topic #3, Immunology: “drug”, “virus”, “antiviral”, “human”, “activity”, “target”, “potential”, “therapeutic”, “new”, “treatment”, “viral”, “compound”, “review”, “inhibitor”, “study”, “novel”, “development”, “host”, “include”, “infection”.
Topic #4, Coronaviruses: “covid-19”, “patient”, “COVID-19”, “case”, “coronavirus”, “sars-cov-2”, “2019”, “2020”, “China”, “clinical”, “novel”, “Wuhan”, “disease”, “severe”, “confirm”, “report”, “day”, “pneumonia”, “2019-ncov”, “symptom”.
Topic #5, Molecular biology: “rna”, “virus”, “viral”, “replication”, “protein”, “gene”, “mrna”, “expression”, “synthesis”, “cell”, “genome”, “transcription”, “host”, “translation”, “hepatitis”, “cellular”, “viral_rna”, “hcv”, “subgenomic”.
Topic #6, Respiratory diseases: “virus”, “influenza”, “detection”, “test”, “viral”, “sample”, “detect”, “assay”, “respiratory”, “method”, “influenza_virus”, “pcr”, “result”, “positive”, “infection”, “diagnostic”, “human”, “clinical”, “specimen”, “rsv”.
Topic #7, Transmission: “virus”, “diarrhea”, “animal”, “pig”, “rotavirus”, “cat”, “sample”, “serum”, “porcine”, “infection”, “day”, “detect”, “pedv”, “bovine”, “feline”, “dog”, “disease”, “intestinal”, “swine”, “antibody”.
Topic #8, Molecular biology: “cell”, “infection”, “mouse”, “response”, “expression”, “immune”, “virus”, “induce”, “role”, “type”, “viral”, “re-sult”, “increase”, “cytokine”, “level”, “receptor”, “study”, “human”, “activation”, “disease”.
Topic #9, Public health and epidemics: “model”, “datum”, “epidemic”, “number”, “case”, “spread”, “transmission”, “disease”, “time”, “outbreak”, “rate”, “measure”, “estimate”, “population”, “analysis”, “result”, “method”, “different”, “base”, “control”.
Topic #10, Immunology: “vaccine”, “antibody”, “response”, “antigen”, “immune”, “epitope”, “mouse”, “vaccination”, “virus”, “challenge”, “neutralize”, “monoclonal”, “human”, “development”, “monoclonal_antibody”, “mab”, “immunity”, “protection”, “induce”, “titer”.
Topic #11, Clinical medicine: “study”, “group”, “effect”, “result”, “high”, “level”, “method”, “treatment”, “increase”, “compare”, “significantly”, “control”, “low”, “conclusion”, “day”, “concentration”, “significant”, “evaluate”, “reduce”, “difference”.
Topic #12, Public health and epidemics: “health”, “disease”, “public”, “pandemic”, “public_health”, “outbreak”, “care”, “system”, “Health”, “risk”, “country”, “research”, “covid-19”, “global”, “need”, “response”, “infectious”, “provide”, “public health”, “information”.
Topic #13, Clinical medicine: “infection”, “patient”, “respiratory”, “disease”, “acute”, “clinical”, “cause”, “lung”, “associate”, “viral”, “pneumonia”, “severe”, “treatment”, “associated with”, “child”, “tract”, “bacterial”, “common”, “pulmonary”, “chronic”.
Topic #14, Transmission: “protein”, “coronavirus”, “cell”, “virus”, “respiratory”, “acute”, “syndrome”, “sars-cov”, “severe”, “SARS”, “res-piratory_syndrome”, “severe_acute”, “spike”, “human”, “mhv”, “coron-aviruse”, “recombinant”, “mouse”, “culture”, “express”.
Regression tables



Acknowledgements
Digital Science kindly provided access to Altmetric and Dimensions data.
Footnotes
↵* This is a working document which has not been peer reviewed yet. Please address any comment or remark to g.colavizza{at}uva.nl.
↵1 https://wikimediafoundation.org/covid19/data [accessed 2020-05-10].
↵2 https://en.wikipedia.org/wiki/Wikipedia:Reliable_sources [accessed 2020-05-10].
↵3 https://en.wikipedia.org/wiki/Wikipedia:Identifying_reliable_sources_(medicine) [accessed 2020-05-10].
↵4 https://en.wikipedia.org/wiki/Wikipedia:General_sanctions [accessed 2020-05-10].
↵5 https://en.wikipedia.org/wiki/Wikipedia:WikiProject_COVID-19 [accessed 2020-0510].
↵6 The identifiers considered by Altmetric in order to establish a citation from Wikipedia to an article currently include: DOI, URI from a domain white list, PMID, PMCID, arXiv ID. https://help.altmetric.com/support/solutions/articles/6000060980-how-does-altmetric-track-mentions-on-wikipedia [accessed 2020-04-27].
↵7 https://github.com/allenai/paper-embedding-public-apis [accessed 2020-04-25].
↵8 We used gensim’s implementation for LDA [46] and tomotopy for CTM and HTM, https://bab2min.github.io/tomotopy [version 0.7.0]. The reader can find more results and the code to replicate all experiments in the accompanying repository.
↵9 https://en.wikipedia.org/wiki/Wikipedia:Notability [accessed 2020-05-10].
↵10 Calculated using Altmetric data which distinguishes among the number of researchers (r), experts (e), practitioners (p) and members of the public (m) engaging with an article. The expert ratio is defined as
 .
.↵11 Marginal effect coefficients should be interpreted as follows. For binary discrete variables (0/1), they represent the discrete rate of change in the probability of the outcome, everything else kept fix; therefore, a change from 0 to 1 with a significant coefficient of 0.01 entails an increase in the probability of the outcome of 1%. For categorical variables with more than two outcomes, they represent the difference in the predicted probabilities of any one category relative to the reference category. For continuous variables, they represent the instantaneous rate of change. It might be the case that this can also be interpreted linearly (e.g., a significant change of 1 in the variable entails a change proportional to the marginal effect coefficient in the probability of the outcome). Yet, this rests on the assumption that the relationship between independent and dependent variables is linear irrespective of the orders of magnitude under consideration. This might not be the case in practice.

References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}