

Abstract
Current state-of-the-art object recognition models are largely based on convolutional neural network (CNN) architectures, which are loosely inspired by the primate visual system. However, these CNNs can be fooled by imperceptibly small, explicitly crafted perturbations, and struggle to recognize objects in corrupted images that are easily recognized by humans. Here, by making comparisons with primate neural data, we first observed that CNN models with a neural hidden layer that better matches primate primary visual cortex (V1) are also more robust to adversarial attacks. Inspired by this observation, we developed VOneNets, a new class of hybrid CNN vision models. Each VOneNet contains a fixed weight neural network front-end that simulates primate V1, called the VOneBlock, followed by a neural network back-end adapted from current CNN vision models. The VOneBlock is based on a classical neuroscientific model of V1: the linear-nonlinear-Poisson model, consisting of a biologically-constrained Gabor filter bank, simple and complex cell nonlinearities, and a V1 neuronal stochasticity generator. After training, VOneNets retain high ImageNet performance, but each is substantially more robust, outperforming the base CNNs and state-of-the-art methods by 18% and 3%, respectively, on a conglomerate benchmark of perturbations comprised of white box adversarial attacks and common image corruptions. Finally, we show that all components of the VOneBlock work in synergy to improve robustness. While current CNN architectures are arguably brain-inspired, the results presented here demonstrate that more precisely mimicking just one stage of the primate visual system leads to new gains in ImageNet-level computer vision applications.
1 Introduction
For the past eight years, convolutional neural networks (CNNs) of various kinds have dominated object recognition [1, 2, 3, 4], even surpassing human performance in some benchmarks [5]. However, scratching beneath the surface reveals a different picture. These CNNs are easily fooled by imperceptibly small perturbations explicitly crafted to induce mistakes, usually referred to as adversarial attacks [6, 7, 8, 9, 10]. Further, they exhibit a surprising failure to recognize objects in images corrupted with different noise patterns that humans have no trouble with [11, 12, 13]. This remarkable fragility to image perturbations has received much attention in the machine learning community, often from the perspective of safety in real-world deployment of computer vision systems [14, 15, 16, 17, 18, 19, 20, 21, 22]. As these perturbations generally have no perceptual alignment with the object class [23], the failures suggest that current CNNs obtained through task-optimization end up relying on visual features that are not all the same as those used by humans [24, 25]. Despite these limitations, some CNNs have achieved unparalleled success in partially explaining neural responses at multiple stages of the primate ventral stream, the set of cortical regions underlying primate visual object recognition [26, 27, 28, 29, 30, 31, 32].
How can we develop CNNs that robustly generalize like human vision?
Incorporating biological constraints into CNNs to make them behave more in line with primate vision is an active field of research [33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]. Still, no neurobiological prior has been shown to considerably improve CNN robustness to both adversarial attacks and image corruptions in challenging real-world tasks such as ImageNet [44]. Here, we build on this line of work, starting with the observation that the ability of each CNN to explain neural response patterns in primate primary visual cortex (V1) is strongly positively correlated with its robustness to imperceptibly small adversarial attacks. That is, the more biological a CNN’s “V1” is, the more adversarially robust it is.
Inspired by this, here we developed VOneNets, a new class of hybrid CNNs, containing a biologically-constrained neural network that simulates primate V1 as the front-end, followed by a standard CNN back-end trained using contemporary methods. The V1 front-end, VOneBlock, is based on the classical neuroscientific linear-nonlinear-Poisson (LNP) model, consisting of a fixed-weight Gabor filter bank (GFB), simple and complex cell nonlinearities, and neuronal stochasticity. The VOneBlock outperforms all standard ImageNet trained CNNs we tested at explaining V1 responses to naturalistic textures and noise samples. After training, VOneNets retain high ImageNet performance, but are substantially more robust than their corresponding base models, and compete with state-of-the-art defense methods on a conglomerate benchmark covering a variety of adversarial images and common image corruptions. Importantly, these benefits transfer across different architectures including ResNet50 [4], AlexNet [1], and CORnet-S [32]. Finally, we dissect the components of the VOneBlock, showing that they all work in synergy to improve robustness and that specific aspects of VOneBlock circuitry offer robustness to different perturbation types.
1.1 Related Work
V1 modeling
Since the functional characterization of simple and complex cell responses by Hubel and Wiesel [45], modeling V1 responses has been an area of intense research. Early approaches consisting of hand-designed Gabor filters were successful in predicting V1 simple cell [46] and complex cell [47] responses to relatively simple stimuli. These models were later improved with the addition of nonlinearities to account for extra-classical properties such as normalization [48, 49]. Generalized LNP models expanded the model class by allowing a set of fitted excitatory and suppressive spatial filters to be nonlinearly combined [50], and subunit models introduced two sequential linear-nonlinear (LN) stages for fitting V1 responses [51]. Recently, both task-optimized and data-fitted CNNs were shown to narrowly beat a GFB model in predicting V1 responses, further validating that multiple LN stages may be needed to capture the complexity of V1 computations [30].
Model robustness
Much work has been devoted to increasing model robustness to adversarial attacks [52, 17, 15, 53, 54, 40, 55], and to a lesser extent common image corruptions [13, 56, 57]. In the case of adversarial perturbations, the current state-of-the-art is adversarial training, where a network is explicitly trained to correctly classify adversarially perturbed images [17]. Adversarial training is computationally expensive [58, 59], known to impact clean performance [60], and overfits to the attack constraints it is trained on [61, 62]. Other defenses involve adding noise either during training [57], inference [63, 19], or both [15, 64, 65]. In the case of stochasticity during inference, Athalye et. al. demonstrated that fixing broken gradients or taking the expectation over randomness often dramatically reduces the effectiveness of the defense [66]. In a promising demonstration that biological constraints can increase CNN robustness, Li et. al. show that biasing a neural network’s representations towards those of the mouse V1 increases the robustness of grey-scale CIFAR [67] trained neural networks to both noise and white box adversarial attacks [40].
2 V1 Explained Variance and Adversarial Robustness
The susceptibility of CNNs to be fooled by imperceptibly small adversarial perturbations suggests that CNNs rely on some visual features not used by the primate visual system. Does a model’s ability to explain neural responses in the macaque V1 correlate with its robustness to adversarial attacks? We analyzed an array of publicly available neural networks with standard ImageNet training [68] including AlexNet [1], VGG [3], ResNet [4], ResNeXt [69], DenseNet [70], SqueezeNet [71], ShuffleNet [72], and MnasNet [73], as well as several ResNet50 models with specialized training routines, such as adversarial training with L∞ (‖δ‖∞ = 4/255 and ‖δ‖∞ = 8/255) and L2 (‖δ‖2 = 3) constraints [74], and adversarial noise combined with Stylized ImageNet training [57].
For each model, we evaluated how well it explained the responses of single V1 neurons evoked by given images using a standard neural predictivity methodology based on partial least square regression (PLS) [31, 32]. We used a neural dataset with 102 neurons and 450 different 4deg images, consisting of naturalistic textures and noise samples [75] (Section A). To evaluate the adversarial robustness of each model in the pool, we used untargeted projected gradient descent (PGD) [17], an iterative, gradient-based white box adversarial attack with L∞, L2, and L1 norm constraints of ‖δ‖∞ = 1/1020, ‖δ‖2 = 0.15, and ‖δ‖1 = 40, respectively. For each norm, the attack strength was calib∞rated to drive variance in performance amongst non-adversarially trained models, resulting in perturbations well below the level of perceptibility (Section B.1).
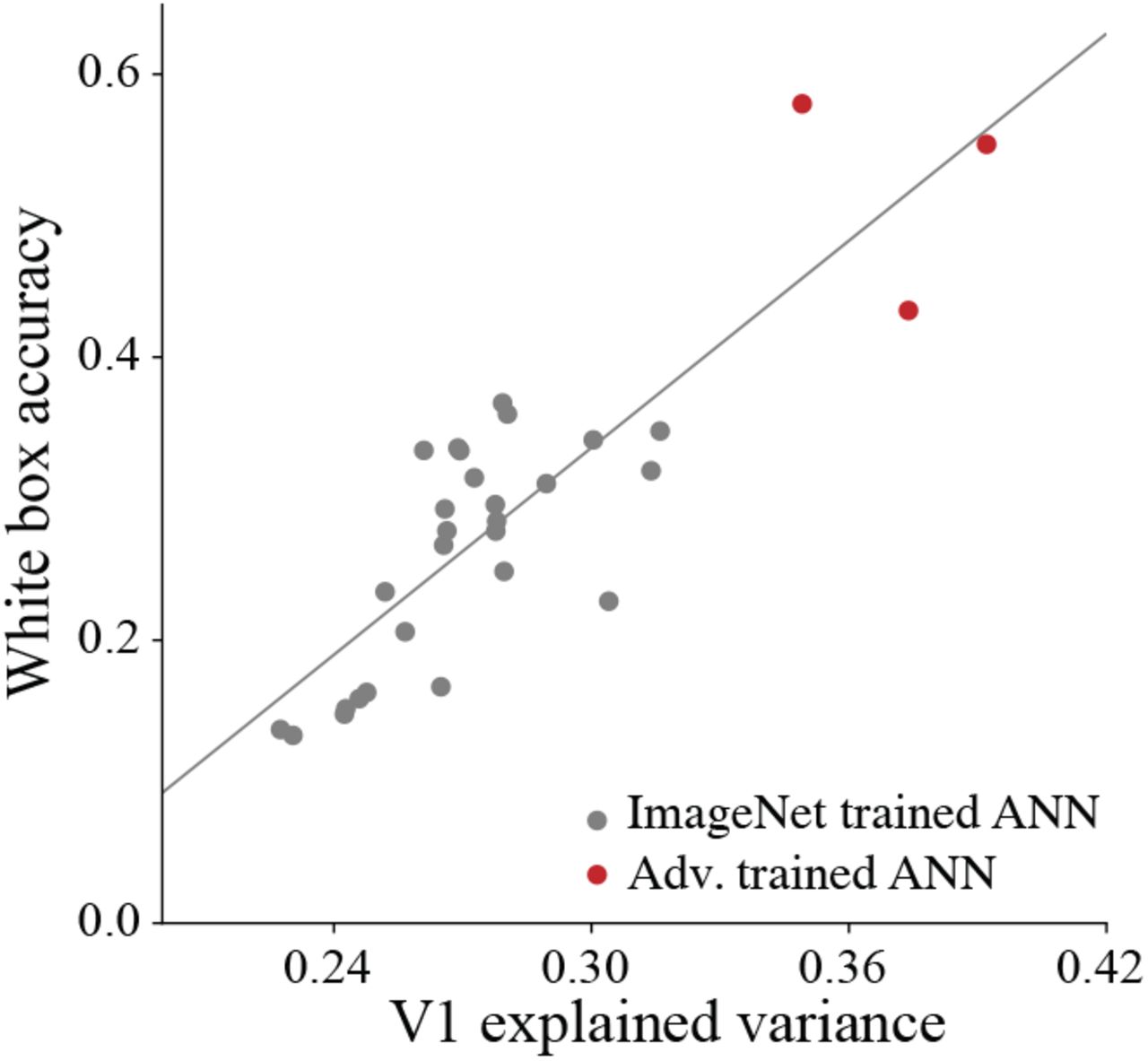
We found that accuracy under these white box adversarial attacks has a strong positive correlation with V1 explained variance (Fig. 1, r=0.85, p=2.1E-9, n=30). Notably, adversarially trained ResNet50 models [74], which were hardly affected by these attacks, explained more variance in V1 neural activations than any non-adversarially trained neural network. The correlation was not driven by the CNNs’ clean ImageNet performance since it was even more pronounced when the white box accuracy was normalized by the clean accuracy (r=0.94, p=7.4E-15, n=30). While increasing the perturbation strength rapidly decreases the accuracy of non-adversarially trained models, the described correlation was present for a wide range of attack strengths: when the perturbation was multiplied by a factor of four, greatly reducing the variance of non-adversarially trained models, white box accuracy was still significantly correlated with explained variance in V1 (r=0.82, p=1.17E-8, n=30).

Comparison of top-1 accuracy under white box attacks of low perturbation strengths (PGD with ‖δ‖∞ = 1/1020, ‖δ‖2 = 0.15, or ‖δ‖1 = 40 constraints) against V1 fraction of explained variance (with PLS regression) for a pool of CNN models. Gray circles, standard ImageNet trained CNNs; red circles, adversarially trained CNNs. Perturbation strength was chosen to drive variance across model performance. White box accuracy and V1 explained variance are significantly correlated (r=0.85, p=2.1E-9, n=30 CNNs, linear fit shown in gray line).
3 VOneNet: a Hybrid CNN with a V1 Neural Network Front-End
Inspired by the strong correlation between V1 explained variance and robustness to white box attacks, we developed the VOneNet architecture. The major characteristic that sets the VOneNet architecture apart is its V1 front-end, the VOneBlock. While most of its layers have parameters learned during ImageNet training, VOneNet’s first block is a fixed-weight, mathematically parameterized CNN model that approximates primate neural processing of images up to and including area V1. Importantly, the VOneBlock components are mapped to specific neuronal populations in V1, which can be independently manipulated or switched off completely to evaluate their functional role. Finally, the VOneBlock can be easily adapted to different CNN base architectures as described below. Here we build VOneNets from three base architectures: ResNet50 [4], CORnet-S [32], and AlexNet [1]. A VOneNet consists of the VOneBlock and a back-end network adapted from a base CNN (Fig. 2). When building a VOneNet from a particular CNN, we replace its first block (typically one stack of convolutional, normalization, nonlinear, and pooling layers, Table C.3) by the VOneBlock and a trained transition layer. The VOneBlock matches the replaced block’s spatial map dimensions but can have more channels (CV1 = 512, Fig. C.2). It is followed by the transition layer, a 1 × 1 convolution, that acts as a bottleneck to compress the higher channel number to the original block’s depth. The VOneBlock is inspired by the LNP model of V1 [50], consisting of three consecutive processing stages—convolution, nonlinearity, and stochasticity generator—with two distinct neuronal types—simple and complex cells—each with a certain number of units per spatial location (SCV1 = CCV1 = 256). The following paragraphs describe the main components of the VOneBlock (see Section C for a more detailed description).

A A VOneNet consists of a model of primate V1, the VOneBlock, followed by a standard CNN architecture. The VOneBlock contains a convolutional layer (a GFB with fixed weights constrained by empirical data), a nonlinear layer (simple or complex cell nonlinearities), and a stochastic layer (V1 stochasticity generator with variance equal to mean). B Top, comparison of accuracy (top-1) on low strength white box attacks (PGD with ‖δ‖∞ = 1/1020, ‖δ‖2 = 0.15, ‖δ‖1 = 40 constraints) between three base models (ResNet50, CORnet-S, and AlexNet) and their correspoding VOneNets. Gray bars show the performance of base models. Blue bars show the improvements from the VOneBlock. Dashed lines indicate the performance on clean images. Bottom, same but for white box attacks of higher strength (PGD with ‖δ‖∞ = 1/255, ‖δ‖2 = 0.6, ‖δ‖1 = 160 constraints). VOneNets show consistently higher white box accuracy even for perturbation strengths that reduce the performance of the base models to nearly chance. Error-bars represent SD (n=3 seeds).
Biologically-constrained Gabor filter bank
The first layer of the VOneBlock is a mathematically parameterized GFB with parameters tuned to approximate empirical primate V1 neural response data. It convolves the RGB input images with Gabor filters of multiple orientations, sizes, and spatial frequencies. To instantiate a VOneBlock, we randomly sample CV1 values for the GFB parameters according to empirically observed distributions [76, 77, 78]. This results in a set of spatial filters considerably more heterogeneous than those found in standard CNNs, that better approximates the diversity of primate V1 receptive field sizes and spatial frequencies (Fig. C.1).
Simple and complex cells
While simple cells were once thought to be an intermediate step for computing complex cell responses, it is now known that they form the majority of downstream projections to V2 [79]. For this reason, the VOneBlock nonlinear layer has two different nonlinearities that are applied to each channel depending on its cell type: a rectified linear transformation for simple cells, and the spectral power of a quadrature phase-pair for complex cells.
V1 stochasticity
A defining property of neuronal responses is their stochasticity—repeated measurements of a neuron in response to nominally identical visual inputs results in different spike trains. In awake monkeys, the mean spike count (averaged over many repetitions) depends on the presented image, and the spike train for each trial is approximately Poisson: the spike count variance is equal to the mean [80]. To approximate this property of neuronal responses, we add independent Gaussian noise to each unit of the VOneBlock, with variance equal to its activation. Before doing this, we apply an affine transformation to the units’ activations so that both the mean stimulus response and the mean baseline activity are the same as those of a population of primate V1 neurons measured in a 25ms time-window (Table C.2 and Fig. C.2). Like in the brain, the stochasticity of the VOneBlock is always on, during both training and inference.
The VOneBlock was not developed to compete with state-of-the-art data-fitting models of V1 [51, 30] which have a thousand times more parameters. Instead we used available empirical distributions to constrain a GFB model, generating a neuronal space that approximates that of primate V1. Despite its simplicity, the VOneBlock outperformed all tested ImageNet trained CNNs in explaining responses in the V1 dataset used, and with an explained variance of 0.387±0.007, came within the margin of error of the most V1-like adversarially trained CNN (Fig. 1, explained variance of 0.392±0.006).
4 Results
4.1 Simulating a V1 at the front of CNNs improves robustness to white box attacks
To evaluate the robustness to white box attacks of the VOneNet architecture, we used untargeted PGD with L∞, L2, and L1 norm constraints of ‖δ‖∞ ∈ [1/1020,1/255], ‖δ‖2 ∈ [0.15,0.6], and ‖δ‖1 ∈ [40,160] (Section B.1). Because VOneNets are stochastic, we took extra care when attacking them—we used the reparameterization trick to randomly sample while keeping gradients intact [81], Monte Carlo sampled at every PGD iteration to ensure useful loss gradients [66] (Table B.1), and performed key controls to ensure the attacks are effective [82] (Figs. B.1 and B.2).
We found that simulating a V1 front-end substantially increased the robustness to white box attacks for all three base architectures that we tested (ResNet50, CORnet-S, and AlexNet) while leaving clean ImageNet performance largely intact (Fig. 2 B top). This was particularly evident for the stronger perturbation attacks, which reduced the accuracy of the base models to nearly chance (Figs. 2 B bottom). This suggests that the VOneBlock works as a generic front-end, which can be transferred to a variety of different neural networks as an architectural defense to increase robustness to adversarial attacks.
4.2 VOneNets outperform state-of-the-art methods on a composite set of perturbations
We then focused on the ResNet50 architecture and compared VOneResNet50 with two state-of-the-art training-based defense methods: adversarial training with a ‖δ‖∞ = 4/255 constraint (ATL∞) [74], and adversarial noise with Stylized ImageNet training (ANT3×3+SIN) [57]. Because white box adversarial attacks are only part of the issue of model robustness, we considered a larger panel of image perturbations containing a variety of common corruptions. For evaluating model performance on corruptions we used the ImageNet-C dataset [13] which consists of 15 different corruption types, each at 5 levels of severity, divided into 4 categories: noise, blur, weather, and digital (Fig. B.4).
As expected, each of the defense methods had the highest accuracy under the specific perturbation type that it was designed for, but did not considerably improve over the base model on the other (Table 1). While the ATL∞ model suffered substantially on corruptions and clean performance, the ANT3×3+SIN model, the current state-of-the-art for common corruptions, had virtually no benefit on white box attacks. On the other hand, VOneResNet50 improved on both perturbation types, outperforming all the models on perturbation mean (average of white box and common corruptions) and overall mean (average of clean, white box, and common corruptions), with a difference to the second best model of 3.3% and 5.3%, respectively. Specifically, VOneResNet50 showed substantial improvements for all the white box attack constraints (Fig. B.1), and more moderate improvements for common image corruptions of the categories noise, blur, and digital (Table B.2 and Fig. B.5).
Accuracy (top-1) on overall mean, perturbation mean, white box attacks, common corruptions, and clean images for standard ResNet50 and three defense methods: adversarial training, adversarial noise combined with Stylized ImageNet training, and VOneResNet50. Perturbation mean is the average accuracy over white box attacks and common image corruptions. The overall mean is the average accuracy over the two perturbation types and clean ImageNet.
These results are particularly remarkable since VOneResNet50 was not optimized for robustness and does not benefit from any computationally expensive training procedure like the other two defense methods. When compared to the base ResNet50, which has an identical training procedure, VOneResNet50 improves 18% on perturbation mean and 10.7% on overall mean (Table 1).
4.3 All components of the VOneBlock contribute to improved model robustness
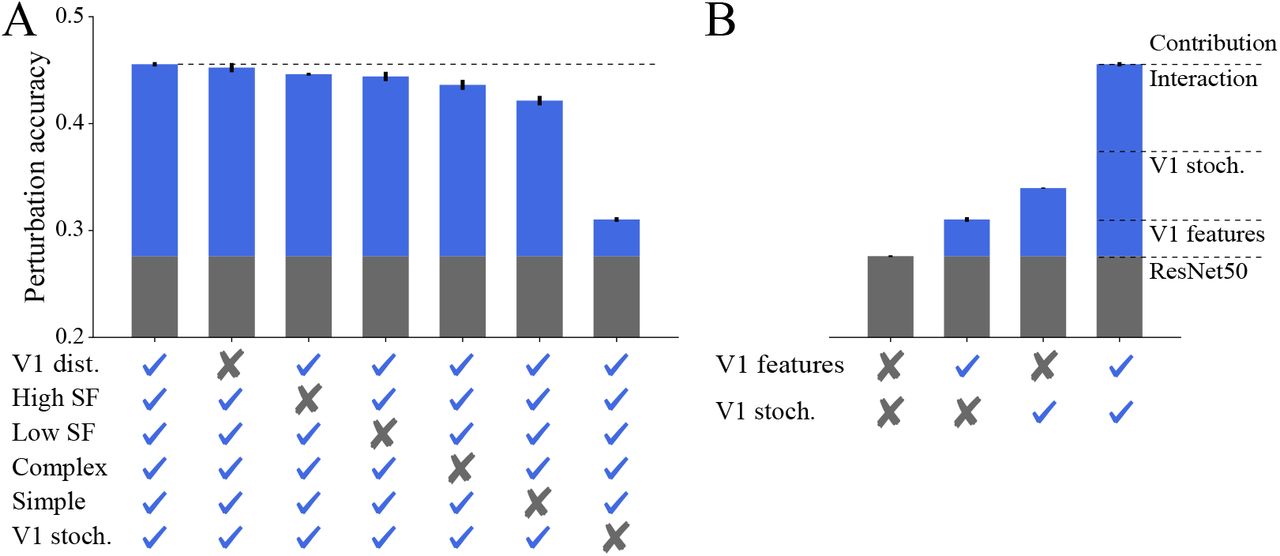
Since the VOneBlock was not explicitly designed to increase model robustness, but rather to approximate primate V1, we investigated which of its components are responsible for the increased robustness we observe. We performed a series of experiments wherein six new VOneNet variants were created by removing or modifying a part of the VOneBlock (referred to as VOneBlock variants). After ImageNet training, model robustness was evaluated as before on our panel of white box attacks and image corruptions. Three variants targeted the GFB: one sampling the Gabor parameters from uniform distributions instead of those found in primate V1, another without high spatial frequency (SF) filters (f < 2cpd), and another without low SF filters (f > 2cpd). Two additional variants targeted the nonlinearities: one without simple cells, and another without complex cells. Finally, the sixth variant had the V1 neuronal stochasticity generator removed. Even though all VOneBlock variants are poorer approximations of primate V1, all resulting VOneResNet50 variants still had improved perturbation accuracy when compared to the base ResNet50 model (Fig. 3 A). On the other hand, all variants except that with uniformly sampled Gabor parameters showed significant deficits in robustness compared to the unmodified VOneResNet50 (Fig. 3 A, drops in perturbation accuracy between 1% and 15%).
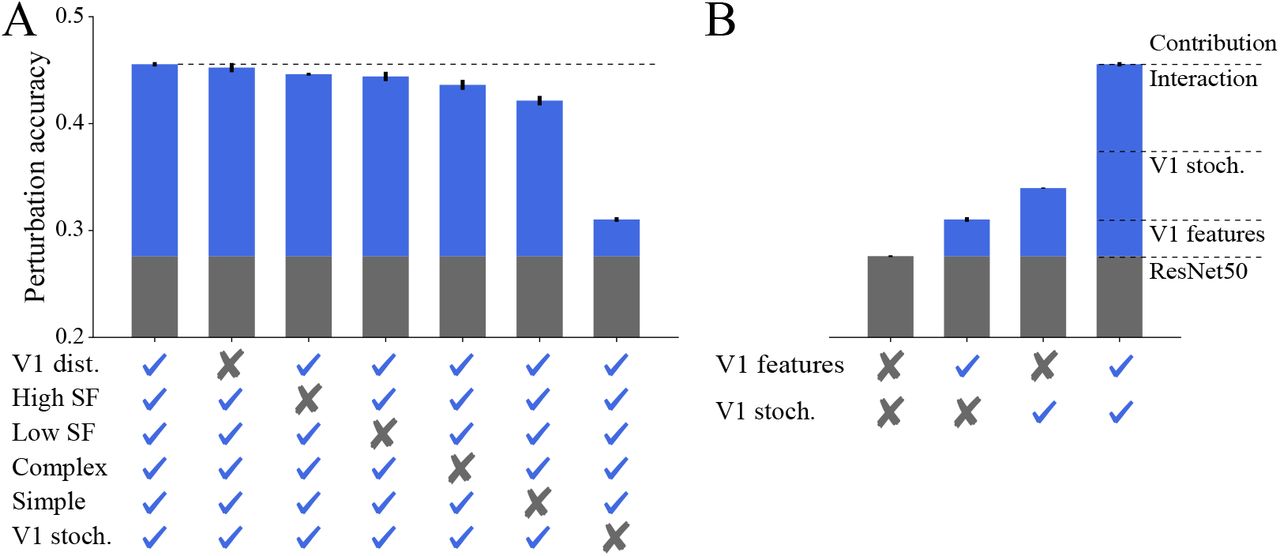
A Perturbation mean accuracy (top-1) for VOneResNet50 and several variations with a component of the VOneBlock removed or altered. From left to right: unmodified VOneResNet50, model with Gabor parameters sampled uniformly (within biological ranges), model without high SF Gabors, model without low SF Gabors, model without complex cells, model without simple cells, model without V1 stochasticity. Gray bars show the performance of ResNet50. Blue bars show the improvements due to the VOneBlock. Dashed line indicates the accuracy of the unmodified model. Error-bars represent SD (n=3 seeds). B Same as in A but comparing ResNet50, VOneResNet50 without V1 stochasticity, ResNet50 with V1 stochasticity added after the first block, and VOneRes-Net50. Adding V1 stochasticity to ResNet50 accounts for less than half of the total improvement of VOneResNet50, demonstrating a supralinear interaction between the V1 features and V1 stochasticity.
Interestingly, we observed that some of these changes had a highly specific effect on the type of perturbation robustness affected (Table 2). Removing high SF Gabors negatively affected both white box and clean accuracy while actually improving robustness to common image corruptions, particularly those of the noise and blur categories (Table C.4). Removing complex cells only impaired white box robustness, as opposed to removing simple cells, which was particularly detrimental to performance on image corruptions. Finally, removing V1 stochasticity considerably decreased white box accuracy while improving accuracy for both clean and corrupted images.
Difference in accuracy (top-1) relative to the unmodified VOneResNet50, for each of the variants with removed components on overall mean, white box attacks, common corruptions, and clean images.
The VOneBlock variant without V1 stochasticity suffered the most dramatic loss in robustness. This is not altogether surprising, as several approaches to adversarial robustness have focused on noise as a defense [15, 19, 64]. To investigate whether V1 stochasticity alone accounted for the majority of the robustness gains, we evaluated the perturbation accuracy of a ResNet50 model with V1 stochasticity added at the output of its first block. Like the VOneResNet50, this model had stochasticity during training and inference, and showed a considerable improvement in robustness compared to the standard ResNet50. However, this improvement accounted for only a fraction of the total gains of the VOneResNet50 model (Fig. 3 B), demonstrating that there is a substantial supralinear interaction between the V1 features and the neuronal stochasticity. Merely adding V1 stochasticity to the first block of a standard CNN model does not increase robustness to the same degree as the full VOneBlock—the presence of V1 features more than doubles the contribution to perturbation robustness brought by the addition of neuronal stochasticity.
Finally, we sought to determine whether stochasticity during inference is key to defending against attacks. Thus, we analyzed the white box adversarial performance of VOneResNet50 while quenching stochasticity during the adversarial attack (Fig. 4). Remarkably, the majority of improvements in adversarial robustness originate from the neuronal stochasticity during training, indicating that V1 stochasticity induces the down-stream layers to learn representations that are more robust to adversarial attacks. This is particularly interesting when contrasted with the ANT3×3+SIN defense, which has noise added to input images during training, but does not learn representations with notably higher robustness to white box adversarial attacks (Table 1 and Fig. B.1).

White box accuracy (top-1) for VOneResNet50 variant without V1 stochasticity, VOneResNet50 with quenched stochasticity during the white box attack, and VOneResNet50. V1 stochasticity improves model robustness in two ways: inducing more robust representations downstream of the VOneBlock, and rendering the attack itself less effective. More robust representations account for the majority of the gains. Gray bars show the performance of the standard ResNet50. Blue bars show the improvements due to the VOneBlock. Error-bars represent SD (n=3 seeds).
5 Discussion
In this work, we demonstrate that simulating the image processing of primate primary visual cortex at the front of standard CNN architectures significantly improves their robustness to image perturbations, even bringing them to outperform state-of-the-art defense methods on a large benchmark consisting of adversarial attacks and common image corruptions. Despite not being constructed to this end, removing or modifying any component of the model to be less like primate V1 results in less overall robustness, and different components improve robustness to different perturbation types. Remarkably, we find that simulated V1 stochasticity interacts synergistically with the V1 model features to drive the downstream layers to learn representations more robust to adversarial perturbations.
Our approach bears some similarity to the pioneering study by Li et. al. [40], in which a model’s representations were regularized to approximate mouse V1, increasing its robustness in the greyscale CIFAR dataset; however, here we go further in several key ways. First, while the mouse is gaining traction as a model for studying vision, a vast literature has established macaque vision as a quantitatively accurate model of human vision in general and human object recognition in particular [83, 84]. Visual acuity in mice is much lower than in macaques and humans [85, 77], suggesting that vision in the mouse may serve different behavioral functions than in primates. Further, the regularization approach employed by Li et. al. does not allow a clear disambiguation of which aspects of mouse V1 contribute to the improved robustness. Since the components of the VOneBlock proposed here are mappable to the brain, we can dissect the contributions of different neuronal populations in primate V1 to robustness against specific image perturbations. Finally, extending the robustness gains of biologically-constrained CNNs from gray-scale CIFAR to the full ImageNet dataset is a critical step towards real-world, human-level applications.
The gains achieved by VOneNets are substantial, particularly against white box attacks, and have tangible benefits over other defense methods. Though adversarial training still provides the strongest defense for the attack statistics it is trained on, it has significant downsides. Beyond its considerable additional computational cost during training, adversarially trained networks have significantly lower performance on clean images, corrupted images, and images perturbed with attack statistics not seen during training, implying that adversarial training in its current form may not be viable as a general defense method. In contrast, by deploying an architectural change, VOneNets improve robustness to all adversarial attacks tested and many common image corruptions, and they accomplish this with no additional training overhead. This also suggests that the architectural gains of the VOneNet could be stacked with other training based defense methods to achieve even greater overall robustness gains.
Relative to current methods, the success of this approach derives from engineering in a better approximation of the architecture of the most well studied primate visual area, combined with task optimization of the remaining free parameters of the downstream architecture [26]. This points to two potentially synergistic avenues for further gains: an even more neurobiologically precise model of V1 (i.e. a better VOneBlock), and an even more neurobiologically precise model of the downstream architecture. For example, one could extend the biological fidelity of the VOneBlock, in the hope that it confers even greater robustness, by including properties such as divisive normalization [48, 49] and contextual modulation [86], to name a few. In addition to V1, the retina and the Lateral Geniculate Nucleus (LGN) also play important roles in pre-processing visual information, only partially captured by the current V1 model, suggesting that extending the work done here to a retina/LGN front-end has potential to better align CNNs with human visual object recognition [87, 88]. In addition, though our initial experiments show that multiple model features of V1 work together to produce greater robustness, much theoretical work remains in better understanding why matching biology leads to more robust computer vision models.
While neuroscience has recently seen a huge influx of new neurally-mechanistic models and tools drawn from machine learning [89, 90], the most recent advances in machine learning and computer vision have been driven mostly by the widespread availability of computational resources and very large labeled datasets [91], rather than by an understanding of the relevant brain mechanisms. Under the belief that biological intelligence still has a lot of untapped potential to contribute, a number of researchers have been pushing for more neuroscience-inspired machine learning algorithms [37, 42, 32]. The work presented here shows that this aspiration can become reality—the models presented here, drawn directly from primate neurobiology, indeed require less training to achieve more humanlike behavior. This is one turn of a new virtuous circle, wherein neuroscience and artificial intelligence each feed into and reinforce the understanding and ability of the other.
Broader Impact
From a technological perspective, the ethical implications of our work are largely aligned with those of computer vision in general. While there is undoubtedly potential for malicious and abusive uses of computer vision, particularly in the form of discrimination or invasion of privacy, we believe that our work will aid in the production of more robust and intuitive behavior of computer vision algorithms. As CNNs are deployed in real-world situations, it is critical that they behave with the same level of stability as their human counterparts. In particular, they should at the very least not be confused by changes in input statistics that do not confuse humans. We believe that this work will help to bridge that gap. Furthermore, while algorithms are often thought to be impartial or unbiased, much research has shown that data driven models like current CNNs are often even more biased than humans, implicitly keying in on and amplifying stereotypes. For this reason, making new CNNs that behave more like humans may actually reduce, or at least make more intuitive, their implicit biases. Unfortunately, we note that even with our work, these issues are not resolved, yet. While we developed a more neurobiologically-constrained algorithm, it comes nowhere close to human-like behaviour in the wide range of circumstances experienced in the real world. Finally, from the perspective of neuroscience, we think that this work introduces a more accurate model of the primate visual system. Ultimately, better models contribute to a better mechanistic understanding of how the brain works, and how to intervene in the case of illness or disease states. We think that our model contributes a stronger foundation for understanding the brain and building novel medical technology such as neural implants for restoring vision in people with impairments.
Supplementary Material
A Neural Explained Variance
We evaluated how well responses to given images in candidate CNNs explain responses of single V1 neurons using a standard neural predictivity methodology based on partial least square (PLS) regression [31, 32]. We reported neural explained variance values normalized by the neuronal internal consistency. We used a neural dataset obtained by extracellular recordings from 102 single-units while presenting 450 different images for 100ms, 20 times each, spanning 4deg of the visual space. Results from this dataset were originally published in a study comparing V1 and V2 responses to naturalistic textures [75]. To avoid over-fitting, for each CNN, we first chose its best V1 layer on a subset of the dataset (n=135 images) and reported the final neural explained variance calculated for the chosen layer on the remaining images of the dataset (n=315 images). We calculated V1 neural explained variance for a large pool of CNNs (n=30 models).
Usually, when using CNNs in a computer vision task, such as object recognition in ImageNet, their field of view (in degrees) is not defined since the only relevant input property is the image resolution (in pixels). However, when using a CNN to model the ventral stream, the visual spatial extent of the model’s input is of key importance to ensure that it is correctly mapped to the data it is trying to explain. We assigned a spatial extent of 8deg to all models since this value has been previously used in studies benchmarking CNNs as models of the primate ventral stream [31, 92], and is consistent with the results in Cadena et. al. [30].
B Image Perturbations
B.1 White Box Adversarial Attacks
For performing white box adversarial attacks, we used untargeted projected gradient descent (PGD) [17] (also referred to as the Basic Iterative Method [93]) with L∞, L2, and L1 norm constraints. Given an image x, This method uses the gradient of the loss to iteratively construct an adversarial image xadv which maximizes the model loss within an Lp bound around x. Formally, in the case of an L∞ constraint, PGD iteratively computes xadv as
 where x is the original image, and the Proj operator ensures the final computed adversarial image xadv is constrained to the space
where x is the original image, and the Proj operator ensures the final computed adversarial image xadv is constrained to the space  , here the L∞ ball around x. In the case of L1 or L2 constraints, at each iteration ∇xtL(θ, xt, y) is scaled to have an L1 or L2 norm of α, and the Proj operator ensures the final xadv is within an L1 or L2 norm ball around x.
, here the L∞ ball around x. In the case of L1 or L2 constraints, at each iteration ∇xtL(θ, xt, y) is scaled to have an L1 or L2 norm of α, and the Proj operator ensures the final xadv is within an L1 or L2 norm ball around x.
For our white box benchmarks, we used ‖δ‖∞ ∈ [1/1020,1/255], ‖δ‖2 ∈ [0.15,0.6], and ‖δ‖1 ∈ [40, 160] constraints where δ = x − xadv, for a total of six different attack variants, with two strengths under each norm constraint. We arrived at these strengths by calibrating the lower strength attack for each norm to give a reasonable degree of variance in normally trained CNNs. Because normally trained CNNs are extrememly sensitive to adversarial perturbations, this resulted in perturbations well below the level of perceptibility, and in most cases, particularly with the L∞ constraint, perturbations would not even be rendered differently by a monitor for display. We set the high attack strength at 4 times the low value, which brought standard ImageNet trained CNNs to nearly chance performance. Still, even this higher perturbation strength remained practically imperceptible (Fig. B.3 left). Each perturbation was computed with 64 PGD iterations and a step size α = ‖δ‖p/32 for the same 5000 images from the ImageNet validation set, on a per model basis, and final top-1 accuracy was reported. The Adversarial Robustness Toolkit [94] was used for computing the attacks.
While adversarial formulations using Lagrangian relaxation like the C&W attack [7] and the EAD attack [8] are known to be more effective than PGD for finding minimal perturbations under L2 and L1 constraints, these formulations involve computationally expensive line searches, often requiring thousands of iterations to converge, making them computationally difficult to scale to 5000 ImageNet samples for a large number of models. Furthermore, because some of the models we tested operate with stochasticity during inference, we found that other state-of-the-art attacks formulated to efficiently find minimal perturbation distances [9, 10] were generally difficult to tune, as their success becomes stochastic as they near the decision boundary. Thus we proceeded with the PGD formulation as we found it to be the most reliable, computationally tractable, and conceptually simple to follow. We share our model and weights, and encourage anyone interested to attack our model to verify our results.
Although the stochastic models were implemented with the reparameterization trick for random sampling, which leaves the gradients intact [81], we performed several sanity checks to make sure that the white box attacks were effectively implemented. Following the advice of Athalye et. al. [66] and Carlini et. al. [82], we observed that in all of the white box attacks, increasing the attack strength decreased model performance, eventually bringing accuracy to zero (Fig. B.1), and additionally that for any given constraint and attack strength, increasing PGD iterations from one to many increased attack effectiveness (Fig. B.2). Furthermore, to be extra cautious, we followed the method Athalye et. al. [66] used to break Stochastic Activation Pruning [19] and replaced ∇xf(x) with  , effectively performing Monte Carlo (MC) sampling of the loss gradient at every PGD iteration. While with high perturbation strength even k =1 was sufficient to bring our model’s accuracy to zero, we find that k = 10 generally achieved higher attack success at intermediate and large perturbation strengths (Table B.1), and thus we used this approach for all attacks on stochastic models.
, effectively performing Monte Carlo (MC) sampling of the loss gradient at every PGD iteration. While with high perturbation strength even k =1 was sufficient to bring our model’s accuracy to zero, we find that k = 10 generally achieved higher attack success at intermediate and large perturbation strengths (Table B.1), and thus we used this approach for all attacks on stochastic models.

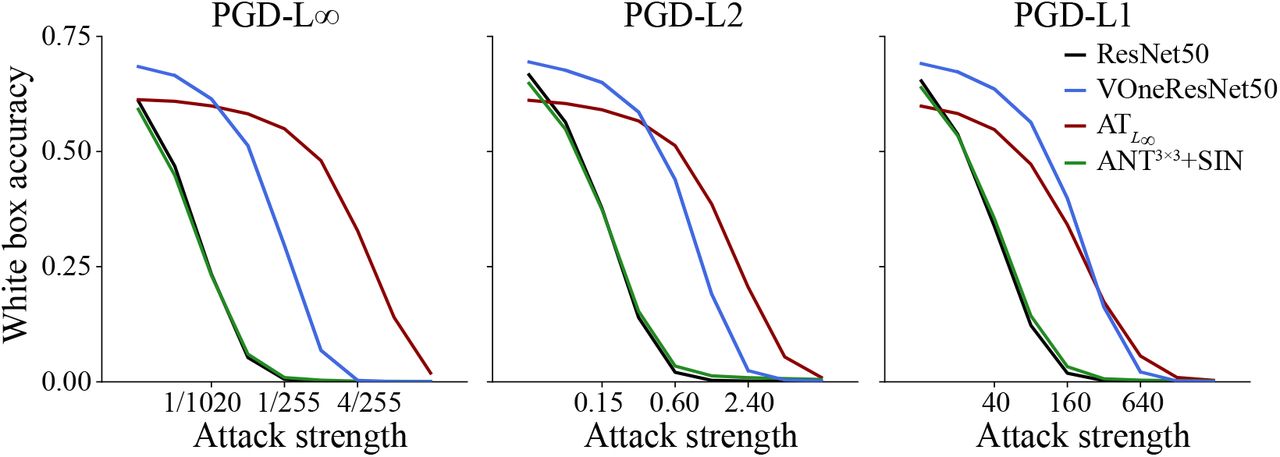
White box accuracy perturbation strength curves for PGD attacks with constraints L∞, L2 and L1 for ResNet50, VOneResNet50, ATL∞, and ANT3×3+SIN. Adding the VOneBlock to ResNet50 consistently improves robustness under all constraints and attack strength—VOneResNet50 can withstand perturbations roughly 4 times higher than the standard ResNet50 for the same performance level. Remarkably, VOneResNet50 outperformed the adversarially trained model (ATL∞) for a considerable range of perturbation strengths, particularly with the L1 constraint. Adversarial noise training combined with Stylized ImageNet (ANT3×3+SIN) has virtually no improvement in robustness to white box attacks. In all white box attacks and for all models, increasing the attack strength decreased performance, eventually bringing accuracy to zero.

White box accuracy iteration curves for PGD attacks with ‖δ‖∞ = 1/255, ‖δ‖2 = 0.6, ‖δ‖1 = 160 constraints. Increasing the number of PGD iteration steps makes the attack more effective, generally converging after 32 iterations.
White box attack accuracy (top-1) under different norm constraints and white box overall mean using standard PGD and PGD with Monte Carlo sampling of the loss gradients (PGD-MC, k = 10) on VOneResNet50 for 64 PGD iteration steps. For all stochastic models we used PGD with Monte Carlo sampling in the white box attacks throughout the paper. Values are mean and SD (n=3 seeds).
Although VOneResNet50 was not designed with to explicitly improve robustness to white box attacks, it offers substantial gains over the standard ResNet50 model (Table 1). A closer inspection of the white box accuracy perturbation strength curves (Fig. B.1) reveals that VOneResNet50 can withstand perturbations roughly 4 times higher than the standard ResNet50 for the same performance level (blue curve is shifted to the right of the black curve by a factor of 4). To help visualize how this difference translates into actual images, we show in Fig. B.3 examples of white box adversarial images for both ResNet50 and VOneResNe50 for the perturbation strengths that bring the respective models to nearly chance performance.
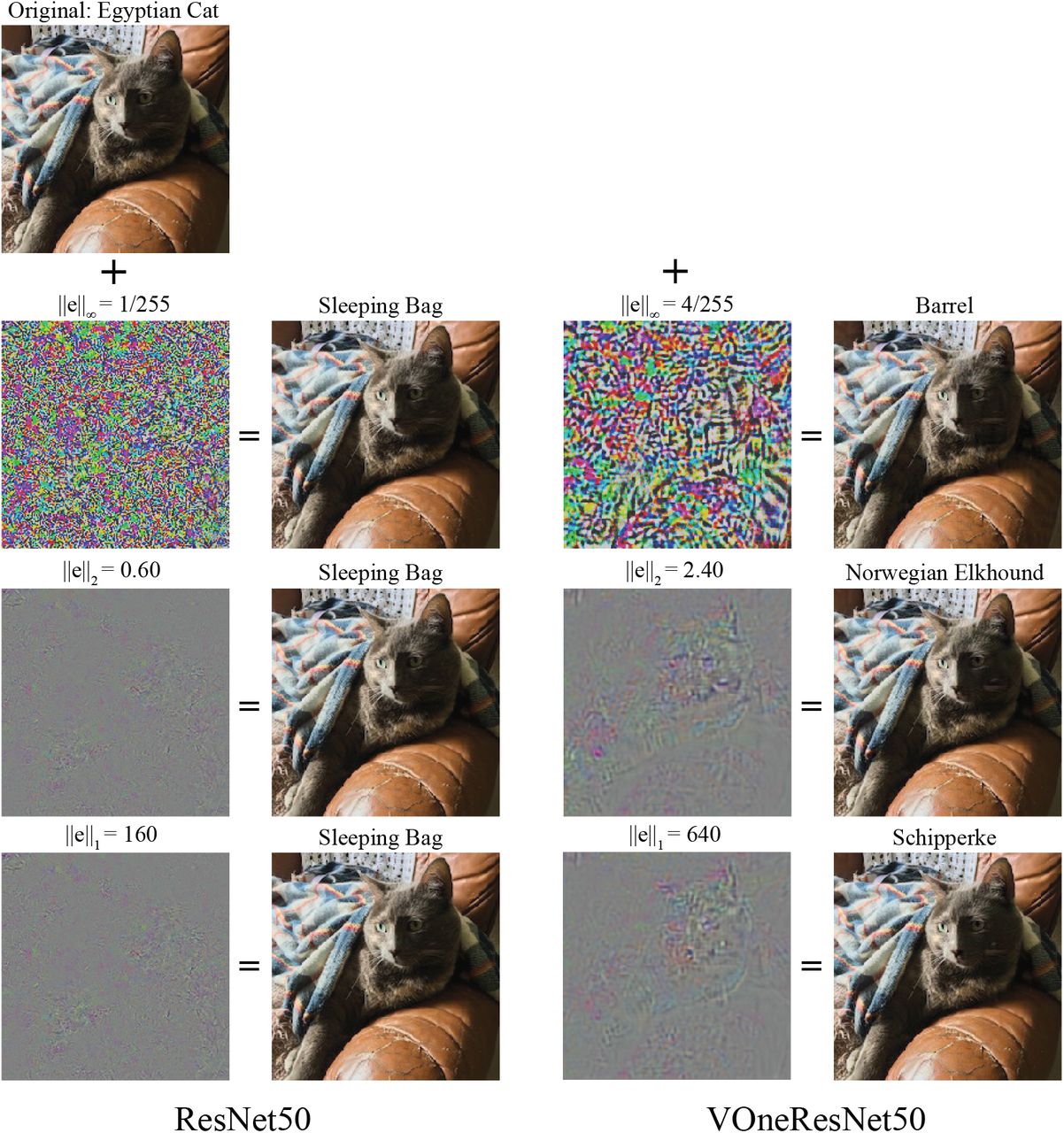
Visualization of white box attacks under the 3 different norm constraints (L∞, L2, and L1) for the perturbation strength that brings the model to nearly chance performance (Fig. B.1). Left, ResNet50; right, VOneResNet50. For each attack, the perturbation is shown on the left, scaled for visualization, and the perturbed image appears next to it. Perturbation strengths and classes of the adversarial images are shown over the images.
B.2 Common Image Corruptions
For evaluating model robustness to common image corruptions, we used ImageNet-C, a dataset publicly available at https://github.com/hendrycks/robustness [13]. It consists of 15 different types of corruptions, each at five levels of severity for a total of 75 different perturbations (Fig. B.4). The corruption types fall into four categories: noise, blur, weather, and digital effects. Noise includes Gaussian noise, shot noise, and impulse noise; blur includes motion blur, defocus blur, zoom blur, and glass blur; weather includes snow, frost, fog, and brightness; digital effects includes JPEG compression, elastic transformations, contrast, and pixelation. For every corruption type and at every severity, we tested on all 50,000 images from the ImageNet validation set. We note that these images have been JPEG compressed by the original authors for sharing, which is known to have minor but noticeable effect on final network performance.

Visualization of all 15 common image corruption types evaluated at severity = 3. First row, original image, followed by the noise corruptions; second row, blur corruptions; third row, weather corruptions; fourth row, digital corruptions.

Corruption accuracy severity curves for the four categories of common image corruptions: noise, blur, weather, and digital. Adding the VOneBlock to ResNet50 improves robustness to all corruption categories except weather. The adversarially trained model (ATL∞) is considerably worse at common image corruptions. Adversarial noise combined with Stylized ImageNet training (ANT3×3+SIN) is consistently more robust to all corruption categories. For ResNet50 and VOneResNet50, error-bars represent SD (n=3 seeds).
Adding the VOneBlock to ResNet50 improves robustness to several of the corruption types. However, for others, particularly fog and contrast, robustness decreases. Interestingly, these are the corruption types that the adversarially trained model (ATL∞) also does the worst. Adversarial noise combined with Stylized ImageNet training (ANT3×3+SIN) is the most robust model for most of the corruption types. For ResNet50 and VOneResNet50, values are mean and SD (n=3 seeds).
B.3 Other defense methods
We compared the performance of VOneResNet50 in the described computer vision benchmarks with two training-based defense methods using the ResNet50 architecture: adversarial training with a ‖δ‖∞ = 4/255 constraint (ATL∞) [74], and adversarial noise with Stylized ImageNet training (ANT3×3+SIN) [57].
The ATL∞ model was downloaded from the publicly available adversarially trained models at https://github.com/MadryLab/robustness [74]. This model was trained following the adversarial training paradigm of Madry et. al. [17], to solve the min-max problem,

Here, the goal is to learn parameters θ minimizing the loss L for training images x and labels y drawn from  , while perturbing x with
, while perturbing x with  to maximally increase the loss. In this case,
to maximally increase the loss. In this case,  is ImageNet, and PGD with ‖δ‖∞ = 4/255 is used to find the perturbation maximizing the loss for a given (x, y) pair. The ‖δ‖∞ = 4/255 constraint model was selected to compare against because it had the best performance on our conglomerate benchmark of adversarial attacks and common image corruptions. The ANT3×3+SIN model was obtained from https://github.com/bethgelab/game-of-noise. Recently, Rusak et. al. showed that training a ResNet50 model with several types of additive input noise improved the robustness to common image corruptions [57]. Inspired by this observation, the authors decided to train a model while optimizing a noise distribution that maximally confuses it. Similarly to standard adversarial training, this results in solving a min-max problem,
is ImageNet, and PGD with ‖δ‖∞ = 4/255 is used to find the perturbation maximizing the loss for a given (x, y) pair. The ‖δ‖∞ = 4/255 constraint model was selected to compare against because it had the best performance on our conglomerate benchmark of adversarial attacks and common image corruptions. The ANT3×3+SIN model was obtained from https://github.com/bethgelab/game-of-noise. Recently, Rusak et. al. showed that training a ResNet50 model with several types of additive input noise improved the robustness to common image corruptions [57]. Inspired by this observation, the authors decided to train a model while optimizing a noise distribution that maximally confuses it. Similarly to standard adversarial training, this results in solving a min-max problem,
 where pϕ(δ) is the maximally confusing noise distribution. The main difference to regular adversarial training in Equation 1, is that while in the former δ is optimized directly, here δ is found by optimizing a constrained distribution with local spatial correlations. Complementing the adversarial noise training with Stylized ImageNet training [25], produced the model with the current best robustness in the ImageNet-C benchmark as a standalone method.
where pϕ(δ) is the maximally confusing noise distribution. The main difference to regular adversarial training in Equation 1, is that while in the former δ is optimized directly, here δ is found by optimizing a constrained distribution with local spatial correlations. Complementing the adversarial noise training with Stylized ImageNet training [25], produced the model with the current best robustness in the ImageNet-C benchmark as a standalone method.
C VOneNet implementation details
C.1 Convolutional layer
The convolutional layer of the VOneBlock is a mathematically parameterized Gabor Filter Bank (GFB). We set the stride of the GFB to be four, originating a 56×56 spatial map of activations. Since the number of channels in most CNNs’ first convolution is relatively small (64 in the architectures adapted), we used a larger number in the VOneBlock so that the Gabors would cover the large parameter space and better approximate primate V1. We set the main VOneNet models to contain 512 channels equally split between simple and complex cells (Fig. C.2 A). Each channel in the GFB convolves a single color channel from the input image.
The Gabor function consists of a two-dimensional grating with a Gaussian envelope and is described by the following equation:
 where
where

 xrot and yrot are the orthogonal and parallel orientations relative to the grating, θ is the angle of the grating orientation, f is the spatial frequency of the grating, ϕ is the phase of the grating relative to the Gaussian envelope, and σx and σy are the standard deviations of the Gaussian envelope orthogonal and parallel to the grating, which can be defined as multiples (nx and ny) of the grating cycle (inverse of the frequency).
xrot and yrot are the orthogonal and parallel orientations relative to the grating, θ is the angle of the grating orientation, f is the spatial frequency of the grating, ϕ is the phase of the grating relative to the Gaussian envelope, and σx and σy are the standard deviations of the Gaussian envelope orthogonal and parallel to the grating, which can be defined as multiples (nx and ny) of the grating cycle (inverse of the frequency).
Although the Gabor filter greatly reduces the number of parameters defining the linear spatial component of V1 neurons, it still has five parameters per channel. Fortunately, there is a vast literature in neurophysiology with detailed characterizations of primate V1 response properties which can be used to constrain these parameters. To instantiate a VOneBlock with CV1 channels, we sampled CV1 values for each of the parameters according to an empirically constrained distribution (Table C.1). Due to the resolution of the input images, we limited the ranges of spatial frequencies (f < 5.6cpd) and number of cycles (n > 0.1).
Critical to the correct implementation of the biologically-constrained parameters of the GFB is the choice of the model’s field of view in degrees. As previously mentioned in Section A, we used 8deg as the input spatial extent for all CNN models. It’s important to note that the set of spatial filters in the VOneBlock’s GFB differs considerably from those in the first convolution in most CNNs (Fig. C.1). While standard CNNs learn filters that resemble Gabors in their input layer [1, 95, 96], due the limited span of their kernels, they do not vary significantly in size and spatial frequency. V1 neurons, on the other hand, are known to exhibit a wide range of receptive field properties. This phenomena is captured in the VOneBlock with spatial frequencies and receptive field sizes of Gabors ranging more than one order of magnitude. Due to this high variability, we set the convolution kernel to be 25 × 25px, which is considerably larger than those in standard CNNs (Fig. C.1).

Example filters from the first convolution in the VOneBlock, ResNet50, CORnet-S, and AlexNet (from left to right). VOneBlock filters are all parameterized as Gabors, varying considerably in size and spatial frequency. Standard CNNs have some filters with shapes other than Gabors, particularly center-surround, and are limited in size by their small kernel. Kernel sizes are 25px, 7px, 7px, and 11px for VOneBlock, ResNet50, CORnet-S, and AlexNet, respectively.
C.2 Nonlinear layer
VOneBlock’s nonlinear layer has two different nonlinearities that are applied to each channel depending on its cell type: a rectified linear transformation for simple cells (6), and the spectral power of a quadrature phase-pair (7) for complex cells:

 where
where  and
and  are the linear and nonlinear responses of a simple neuron and
are the linear and nonlinear responses of a simple neuron and  and
and  are the same for a complex neuron.
are the same for a complex neuron.
C.3 Neuronal stochasticity generator
In awake monkeys, spike trains of V1 neurons are approximately Poisson, i.e. the variance and mean of spike counts, in a given time-window, over a set of repetitions are roughly the same [80]. We incorporated stochasticity into the VOneBlock to emulate this property of neuronal responses. Since the Poisson distribution is not continuous, it breaks the gradients in a white box attack giving a false sense of robustness [66]. In order to avoid this situation and facilitate the evaluation of the model’s real robustness, our neuronal stochasticity generator as implemented uses a continuous, second-order approximation of Poisson noise by adding Gaussian noise with variance equal to the activation:
 where Rns and Rs are the non-stochastic and stochastic responses of a neuron.
where Rns and Rs are the non-stochastic and stochastic responses of a neuron.
To approximate the same levels of neuronal stochasticity of primate V1 neurons, it is critical that the VOneBlock activations are on the same range as the V1 neuronal responses (number of spike counts in a given time-window). Thus, we applied an affine transformation to the activations so that both the mean stimulus response and the mean baseline activity are the same as those of a population of V1 neurons (Table C.2 shows the mean responses and spontaneous activity of V1 neurons measured in different time-windows).
Since the exact time-window that responses in V1 are integrated during visual perception is still an open question, we considered a time-window of 25ms (Fig. C.2 B). In order to keep the outputs of the VOneBlock on a range that does not deviate considerably from the typical range of activations in CNNs, so that the model can be efficiently trained using standard training parameters, we applied the inverse transformation to scale the outputs back to their original range after the stochastic layer.
C.4 Hyper-parameters and other design choices
We developed VOneNets from three different standard CNN architectures: ResNet50, CORnet-S, and AlexNet. As previously mentioned, we replaced the first block of each architecture by the VOneBlock and the transition layer to create the respective VOneNet. Table C.3 contains the layers that were removed for each base architecture. Except CORnet-S, the layers removed only contained a single convolution, nonlinearity and maxpool. Since CORnet-S already had a pre-committed set of layers to V1, we replaced them by the VOneBlock. The torchvision implementation of AlexNet contains a combined stride of eight in the removed layers (four in the convolution and two in the maxpool), followed by a stride of one in the second convolution (outside of the removed layers). In order to more easily adapt it to a VOneBlock with a stride of four, we slightly adapted AlexNet’s architecture so that it had strides of two in these three layers (first convolution, first maxpool, and second convolution). The results shown in Fig. 2 were obtained using this modified architecture.
The VOneNet architecture was designed to have as few hyper-parameters as possible. When possible these were either constrained by the base CNN architecture or by neurobiological data: most parameters of the GFB were instantiated by sampling from neuronal distributions of primate V1 neurons; the kernel size was set to 25×25px to capture the high variability in Gabor sizes; like all other CNN models, the spatial extent of the field of view was set to 8deg (Section A). Nevertheless, there were two hyper-parameters where the choice was rather arbitrary: the number of channels in the VOneBlock, and the time-window for integrating V1 responses to scale the activations prior to the stochasticity generator.
Since primate V1 has neurons tuned to a wide range of spatial frequencies, for each orientation and at any given location of the visual space [97], we expected that a large number of channels would be required to cover all of the combinations of Gabor parameters. For the VOneRes-Net50 architecture, we varied the number of channels in the VOneBlock between 64 and 1024, equally split between simple and complex cells, and measured the performance of the several models after training (Fig. C.2 A). Clean ImageNet and common image corruption performance improved with channel number. Remarkably, the opposite happened for white box accuracy, with variants of VOneResNet50 with 64 and 128 channels achieving the highest robustness to white box attacks. This result is particularly interesting since it had been shown that increasing the number of channels in all layers of a CNN improves robustness to white box attacks in both standard and adversarially trained models [17]. Therefore, this shows that the improvement in white box robustness of VOneNets, when compared to their base models, cannot be attributed to the higher number of channels. For the main model, we set the channel number to be 512 as it offered a good compromise between the different benchmarks. Regarding the time-window for integrating V1 responses, we observed small effects on the models’ performance when varying it between 25 and 200ms. We chose 25ms for the main model due to a small trend for higher robustness to white box attacks with shorter time-windows.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A Performance of different VOneResNet50 models with varying number of channels in the VOneBlock. B Same as in A but varying time-window for integrating neuronal activity. Error-bars show SD (n=3 seeds). Red arrows represent the values used in the main model.
C.5 VOneBlock variations experiments details
To investigate which components of the VOneBlock are responsible for the increased robustness, we created six variants of the VOneBlock by removing or modifying one of its parts. In all cases, we trained from scratch a corresponding variant of VOneResNet50 with the modified VOneBlock. All other properties of the model and components of the VOneBlock were left unmodified. Here we describe in more detail each of these variants (the name of the variant refers to the component removed):
V1 distributions: the GFB parameters were sampled from uniform distributions with the same domain as the empirical distributions used in the default VOneBlock (Table C.1).
Low SF: when sampling the spatial frequencies for the GFB, neurons with low peak spatial frequencies (f < 2cpd) were removed from the empirical distribution [77].
High SF: similar to the previous variant but removing neurons with high peak spatial frequencies (f > 2cpd).
Complex NL: complex cell channels were removed from the VOneBlock and replaced by simple cell channels.
Simple NL: simple cell channels were removed from the VOneBlock and replaced by complex cell channels.
V1 stochasticity: V1 stochasticity generator was removed from the VOneBlock.
While all of the variants resulted in worse overall mean performance than the unmodified VOneResNet50 (Table 2), some improved specific benchmarks: the variant without high SF had higher accuracy under noise and blur corruptions (Table C.4), the variant without V1 stochasticity had higher accuracy to clean images and images with noise and weather corruptions (Tables 2 and C.4), and the variant without V1 distributions had higher accuracy to white box attacks with high L∞ perturbations (Table C.5).
Removal of simple cells reduced accuracy to all common image corruption types. Removal of some components of the VOneBlock improved accuracy in specific common image corruption: removing high SF consistently improved performance for noise and blur corruptions, and removing V1 stochasticity improved performance for noise and weather corruptions.
Removal of V1 stochasticity considerably reduced accuracy to all white box attacks. Removal of V1 distributions improved accuracy for L∞ white box attacks, particularly those with high perturbation strengths..
C.6 Training details
We used PyTorch 0.4.1 and trained the model using ImageNet 2012 [34]. Images were preprocessed (1) for training—random crop to 224 × 224 pixels and random flipping left and right; (2) for validation—central crop to 224 × 224 pixels. Preprocessing was followed by normalization— subtraction and division by [0.5, 0.5, 0.5]. We used a batch size of 256 images and trained either on 2 GPUs (NVIDIA Titan X / GeForce 1080Ti) or 1 GPU (QuadroRTX6000 or V100) for 70 epochs. We use step learning rate scheduling: 0.1 starting learning rate, divided by 10 every 20 epochs. For optimization, we use Stochastic Gradient Descent with a weight decay 0.0001, momentum 0.9, and a cross-entropy loss between image labels and model predictions (logits).
Several ImageNet-trained models and code will be available in a github repository.
Acknowledgments and Disclosure of Funding
We thank J. Anthony Movshon and Corey M. Ziemba for access to the V1 neural dataset, John Cohn for technical support, Sijia Liu for advice on adversarial attacks and training, and Adam Marblestone for insightful discussion. This work was supported by the PhRMA Foundation Postdoctoral Fellowship in Informatics (T.M), the Semiconductor Research Corporation (SRC) and DARPA (J.D., M.S., J.J.D.), the Massachusetts Institute of Technology Shoemaker Fellowship (M.S.), Office of Naval Research grant MURI-114407 (J.J.D.), the Simons Foundation grant SCGB-542965 (J.J.D.), the MIT-IBM Watson AI Lab grant W1771646 (J.J.D.).
Footnotes
dapello{at}mit.edu, tmarques{at}mit.edu
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵
- [79].↵
- [80].↵
- [81].↵
- [82].↵
- [83].↵
- [84].↵
- [85].↵
- [86].↵
- [87].↵
- [88].↵
- [89].↵
- [90].↵
- [91].↵
- [92].↵
- [93].↵
- [94].↵
- [95].↵
- [96].↵
- [97].↵




