

Abstract
We study whether novel ideas in biomedical literature appear first in preprints or traditional journals. We develop a Bayesian method to estimate the time of appearance for a phrase in the literature, and apply it to a number of phrases, both automatically extracted and suggested by experts. We see that presently most phrases appear first in the traditional journals, but there is a number of phrases with the first appearance on preprint servers. A comparison of the general composition of texts from bioRxiv and traditional journals shows a growing trend of bioRxiv being predictive of traditional journals. We discuss the application of the method for related problems.
1 Introduction
A paper submitted to a journal goes through several stages: peer review, editorial work, copyediting, publication. This leads to a long waiting time between submission and the final publication (Powell, 2016). The situation is especially bad in the life sciences, where the waiting time between submission and publication approaches the duration of a traditional PhD study, creating serious difficulties for young scientists (Vale, 2015). While this is frustrating for scientists whose recognition and promotion often depend on the publication record, it is also bad for science itself, significantly slowing down its progress (Qunaj et al., 2018).
Preprint servers were offered as a means of accelerating science (Berg et al., 2016; Desjardins-Proulx et al., 2013; Sarabipour et al., 2019; Schloss, 2017; Lauer et al., 2015; Peiperl, 2018), especially in the wake of COVID-19 epidemics (Krumholz et al., 2020). The discussion about the benefits (and dangers) of preprint is no longer confined to the scientific literature, coming to the pages of popular newspapers (Eisen and Tibshirani, 2020).
The benefits of preprints for accelerating science are often raised in the discussions between regulatory agencies, funders, scientists and publishers. Thus a method to objectively assess them is important. One way to do this assessment is to look at a new important idea and to measure whether it first appears in a traditional journal or on a preprint server.
An implementation of this approach requires one to define what is an important idea, and how to find the time of appearance for it. This is the goal of our work.
The definition of novelty in science and the methods to determine and predict novelty have a long history discussed in the next section. In this work we use a very simple approach (Garfield, 1967; Latour and Woolgar, 1986): new ideas correspond to new terms. Thus if we find new words and phrases in scientific papers, we can surmise the appearance of new ideas.
The definition of the time of appearance for a new idea is not trivial. It is not enough to register the first mention of a term. First, some hits might be erroneous, and give us false positives. On the other hand, we might miss some mentions of a term due to the incompleteness of the corpus. Therefore a more subtle method to determine the time of appearance is needed. In this work we offer a Bayesian approach to this problem.
Based on our definitions of novelty and the time of appearance for novel ideas we compare the time of appearance for several novel ideas in the papers published in bioRxiv/medRxiv https://www.biorxiv.org/ and PubMed Central full text collection https://www.ncbi.nlm.nih.gov/pmc/.
2 Related Works
Novel ideas and breakthroughs are among the central concepts for the science of science. A number of studies propose different ideas to quantify originality in science and technology (Cozzens et al., 2010; Alexander et al., 2013; Rzhetsky et al., 2015; Rotolo et al., 2015; Wang et al., 2016; Wang and Chai, 2018; Shibayama and Wang, 2020) or their impact on the other works (Shi et al., 2010; Shahaf et al., 2012; Sinatra et al., 2016; Hutchins et al., 2016; Wesley-Smith et al., 2016; Herrmannova et al., 2018b,a; Zhao et al., 2019; Bornmann et al., 2019; Small et al., 2019). The prediction of break-throughs, scientific impact and citation counts is a well developed area (Schubert and Schubert, 1997; Garfield et al., 2002; Dietz et al., 2007; Lokker et al., 2008; Shi et al., 2010; Uzzi et al., 2013; Alexander, 2013; Klimek et al., 2016; Tahamtan et al., 2016; McKeown et al., 2016; Clauset et al., 2017; Peoples et al., 2017; Salatino et al., 2018; Dong et al., 2018; Iacopini et al., 2018; Feldman et al., 2018; van den Besselaar and Sandström, 2018; Klavans et al., 2020). However, the question asked in these works is different from the one we ask. Most of the researchers tried to determine what makes a work original or impactful, and how to predict originality or impact. Our question is the following: suppose we know a certain idea is novel (or impactful). Can we pinpoint a moment in time when this idea appeared, and where did it appear?
Sentence level novelty detection was a topic of novelty tracks of Text Retrieval Conferences (TREC) from 2002 to 2004 (Soboroff and Harman, 2003; Harman, 2002; Clarke et al., 2004; Soboroff and Harman, 2005). The goal of these tracks was to highlight the relevant sentences that contain novel information, given a topic and an ordered list of relevant documents. At the document level, Karkali et al. (2013) computed novelty score based on the inverse document frequ function. Another work by Verheij et al. (2012) presents a comparison study of diffe detection methods evaluated on news a language model based methods perform better than the cosine similarity based ones. Dasg (2016) conducted experiments with information entropy measure to calculate novelty of a document. Again, the work that we present here significantly differs from the existing novelty detection methods since we use the novelty detection as a starting point rather than a goal. We first get candidate phrases from the documents with the most appropriate key phrases extraction method, and then determine the appearance timing of these phrases.
Another field that is relevant to our research is the detection of change points in a stream of events. Change point detection (or CPD) detects abrupt shifts in time series trends that can be easily identified via the human eye, but are harder to pinpoint using traditional statistical approaches. The research in CPD is applicable across an array of industries, including finance, manufacturing quality control, energy, medical diagnostics, and human activity analysis. There are many representative methods of CPD. Binary segmentation (Bai, 1997) is a sequential approach: first, one change point is detected in the complete input signal, then series is split around this change point, then the operation is repeated on the two resulting sub-signals. As opposite to binary segmentation, which is a greedy procedure, bottom-up segmentation (Fryzlewicz, 2007) is generous: it starts with many change points and successively deletes the less significant ones. First, the signal is divided in many sub-signals along a regular grid. Then contiguous segments are successively merged according to a measure of how similar they are. Because the enumeration of all possible partitions is impossible, Pelt (Killick et al., 2012) relies on a pruning rule. Many indexes are discarded, greatly reducing the computational cost while retaining the ability to find the optimal segmentation. Window-based change point detection (Aminikhanghahi and Cook, 2016) uses two windows which slide along the data stream. Dynamic programming was also used for this task (Truong et al., 2020). In this work we propose a simple Bayesian approach to the detection of change points, which seems to give intuitively reasonable results for our purpose.
3 Bayesian Approach to Novelty Detection
Our proposed Bayesian Approach to Novelty Detection (BAND) finds the time interval τ that maximizes the observed series of publication frequency for a phrase (Figure 1). Paper publications are events, so it is reasonable to assume that the number of publications n in a unit interval at the time t containing the given phrase z follows a Poisson distribution. The joint density function for publication frequency is given by the equation
 where μt is modeled by a piecewise linear function of t:
where μt is modeled by a piecewise linear function of t:


Our Bayesian Approach to Novelty Detection (BAND). The goal is to find the inflection point τ that indicates the earliest point attributed to the rapid research growth associated with a novel idea.
Prior to τ, we expect the number of publications containing the given phrase to be small, ideally zero. The parameter α > 0 controls for the noise (misattributed papers, improper or ambiguous us-age of the phrase, etc.). After the moment τ, we expect the steady grow of phrase popularity with the rate β. In other words, τ is the point in time ehen the phrase begins to be adopted.
We consider each phrase independently and use Bayesian modeling to find the most probable parameters α, β, and τ given the observed data using the standard Bayesian approach

We use a flat uniformative prior with

Our motivation for finding τ using BAND is to compare the impact of different publication venues (i.e. preprint servers and peer-reviewed journals) that cover overlapping research topics. For a single phrase z, we use the observed data from two sources and estimate the posterior probability P (α, β, τ) for each source separately. Then we run a simulation to find the 95% confidence interval of τ using the following procedure:
For a single data source, compute P (α, β, τ) for all possible configurations on a grid.
Sample a large number of triplets (α, β, τ) from the posterior computed in Step 1.
Remove 2.5% of the triples with the highest value of τ, and 2.5% of triplets with the lowest value of τ. The probability for τ to lie in the remaining interval can be estimated as 95%.
In order to compare two sources, we create two sets of tuples, one for each source. Then we randomly draw a tuple from the first set and a tuple from the second one. For each pair i we compute δi, the expected difference between the two sources where  is the i-th sample in source s:
is the i-th sample in source s:

The conclusion about the priority is based on distribution of δ around zero. If δ > 0 for the majority of the pairs, then the phrase gains traction first on source s0. Otherwise the second source wins.
4 Experimental Setup
In this section we describe our data collection procedure and background on methods of text processing and assessing data quality. Our code for running experiments is publicly available.1
4.1 Data Sources (Publication Venues)
We consider two types of publication venues: peer-reviewed journals and preprint servers. There are now many preprint servers for various areas of science, including arXiv, bioRxiv, medRxiv, PsyArXiv, SocArXiv, ChemRxiv, AgriRXiv, and others. To compare a preprint server to a traditional venue one needs a large open access collection of traditionally published papers. In biomedical sciences there is a huge Pubmed Central Open Access Dataset described below, which drove our choice for bioRxiv/medRxiv as a comparison venue. Another reason for this choice of data sources is that one of our organizations, Chan Zuckerberg Initiative, has a special interest in biomedical sciences in general and bioRxiv & medRxiv in particular.
PubMed is a central repository for biomedical papers published in peer-reviewed journals. It contains over 26 million journal publications. Abstracts are publicly available for all papers, and for a subset (the PubMed Central Open Access Dataset with over 1.6 million papers) full texts are available.2
In contrast to PubMed, bioRxiv is a preprint server for the biological sciences. Papers published there are not required to pass a strict and lengthy review process. BioRxiv hosts over 70,000 full text articles, each open to the public. Recently medical papers were separated into a special server medRxiv. Since the search engine provided by bioRxiv can search both servers, below we use the term “bioRxiv” for the longer, but more correct term “the union of bioRxiv and medRxiv papers”.
PubMed and bioRxiv cover the two representative categories of publication venue. We also include data sources using information from COVID-19 Open Research Dataset Challenge (Wang et al., 2020).
4.2 Text Processing and Data Collection
In our experiments and analysis we leverage a large collection of phrases collected in an unsupervised way using TextRank (Mihalcea and Tarau, 2004; Nathan, 2016). The procedure to extract the phrase is the following:
First we extract all candidate phrases from bioRxiv abstracts using TextRank. This results in 1,587,408 phrases.
We filter the phrases from Step 1 to the 239,608 phrases by eliminating phrases that were detected by TextRank only once.
For each phrase from Step 2 we generate monthly time series data for both PMC and bioRxiv using full text.3
We use this data collection procedure and recommendations from CZI biomedical curators to create three groups of phrases:
Common phrases: 20 banal phrases manually selected that are also extracted by TextRank (includes ‘medical history’, ‘heart disease’, ‘x-ray’, etc.).
Novel phrases: 20 phrases selected by experts (includes ‘mass cytometry’, ‘gene editing’, ‘fluorescence activated cell sorting’, etc.).
Top extracted phrases: The top 7000 phrases extracted by TextRank determined by average importance score.
All common and novel phrases, and a subset of the top ranking phrases are shown in Appendices A.2, A.1.2, and A.1.1.
4.3 Baselines for finding τ
To assess the effectiveness of BAND for finding τ we include a strong baseline in our experiments. In our analysis (Section 5.2), we compare these methods to BAND not only for finding t he first clear inflection point, but also how relevant τ is for the end goal of novelty detection and comparing research impact.
The baseline we include is Window-based Change Point Detection (see Section 2). It works by maximizing the discrepancy measuring function
 which is large when the left segment c(xa, τ) is dissimilar from the right segment c(τ, xb).
which is large when the left segment c(xa, τ) is dissimilar from the right segment c(τ, xb).
Window-based Changepoint Detection (WCPD) is flexible and has been successful when applied to many tasks. However, for a number of novel phrases (see the first two examples on Figure 3) it gives intuitively unsatisfactory results for the detection of the idea onset. The reason is, WCPD tries to find the point where the publication frequency significantly changes, which often corresponds to the moment the idea is widely adopted. Our task, on the other hand, is to find the point when the idea appears, which is a different problem. Therefore one may expect BAND to work better for the cause of the novelty detection because its model of growth starting from zero might be more suitable to describe the publication frequency than the generic model of WCPD.
We found necessary to run WCPD using the finite difference approximation of the publication frequency gradient to obtain reasonable predictions.
We use the implementation of WCPD provided in ruptures (Truong et al., 2020) with an L2-cost function (c), window size of 10, penalty of 1, and no specification on how many changepoints to return.4 In our figures we display all changepoints from WCPD to illustrate these changepoints do not solely identify the point before rapid growth in idea adaptation. On the other hand our method (BAND) consistently finds changepoints that match this criterion.
5 Results and Analysis
In this section we discuss the following hypotheses and research questions:
Can we find the point τ in time when a phrase is determined novel using our Bayesian Approach to Novelty Detection (BAND)?
Is the value of τ effective for comparing the impact of two publication venues?
Do our findings verify that preprint servers are having a positive impact on the development of novel ideas?
How effective is publication frequency for distinguishing from novel and banal phrases?
Below we answer each of these questions.
5.1 Are pre-print servers accelerating research?
The common wisdom is the preprint servers have positive impact on research, by making research available openly and quickly. We attempt to verify that ideas develop faster on bioRxiv rather than on PubMed. Our results indicate that this might be true in some, but not all, cases. For some phrases δ leans positive (see Figure 2 top), indicating the relevant phrase and presumably the novel idea appeared first on bioRxiv. However, the opposite is true more often than not (see Figure 2, bottom).

The distribution of δ (left column), publication frequency on bioRxiv (center), and publication frequency on PubMed (right) for two phrases
Why is PubMed frequently the first place that novel ideas appear? One reason might be that bioRxiv is relatively new, did not gain enough traction yet, and its benefits are not widely appreciated. One can even say it is surprising and encouraging that some novel ideas appear first on bioRxiv despite the it being a relative newcomer. Thus one interpretation of our finding is that while preprint servers are already having a positive impact on research, there is still a potential for the growth. In this case we expect that in the future novel ideas will appear first on bioRxiv at a higher rate. We further check this assumption in Section 5.3.
5.2 Is BAND effective at determining τ ?
We assume that curves of publication frequency of novel ideas follow a particular shape—they are relatively flat followed by a growth period. This assumption is built in the design of BAND. To verify BAND’s effectiveness, we use a set of novel phrases provided by the team of biomedical curators at Chan Zuckerberg Initiative (CZI), extract their publication frequency data from PubMed, and calculate τ using BAND. Qualitatively, we see in Figure 3 that BAND results agree with the intuition about the novelty onset.

BAND often finds a more desirable point of inflection than WCPD (left). In addition, WCPD may return multiple points (center). However, in cases when the evolution of a term does not follow our model, WCPD is more effective (right).
As discussed in Section 4.3, WCPD is another technique for finding points of inflection. WCPD is a useful method because it finds inflection points without requiring any prior model of the data. As expected, if the evolution of data follows our model of growth, BAND gives a better estimate for the novelty onset (Figure 3, left and center). On the other hand, if the data do not follow BAND model, BAND is not supposed to work well, and assumption-free models like WCPD might work better. An example is shown on (Figure 3, right), where a period of growth is followed by a plateau rather than the growth assumed by BAND model.
5.3 Are pre-print servers mature?
A potentially confounding variable in our experimental setup is the relative recency in the establishment of bioRxiv (2013) compared to PubMed (1996). This motivates us to measure the correlation between the publication frequency of these two data sources. We proceed by looking at three groups of phrases: (a) common phrases found in medical terminology, (b) novel phrases provided by experts, and (c) highest scoring phrases according to TextRank.
First, we aggregated the last 6 years of data. We found the similarity between PubMed and bioRxiv for common phrases and phrases extracted from TextRank most similar when comparing the early snapshot of bioRxiv with the later snapshot of PubMed (Figure 4). Thus for these phrases bioRxiv is predictive of PubMed. On the other hand, phrases selected by experts (Section 5.2) tend to appear on PubMed first (Figure 4, center).

We report average correlation between PubMed and bioRxiv for publication frequency in a 6-year window. We shift the window for bioRxiv one month at a time, where positive values on the x-axis correspond to shifts back in time and negative values indicate shifts forward in time. If at the highest value (indicated by the dotted red line) the offset is positive bioRxiv is a predictor of PubMed’s content. If the offset is negative, the opposite is true. We perform this analysis for 3 subsets of terms: common phrases (a), novel phrases (b), and phrases from TextRank (c) starting in January 2014.
Taking into account that bioRxiv is still evolving, we performed a more fine-grained analysis where results are only aggregated across 2 years instead of 6. This also allowed us to study how the content alignment between PubMed and bioRxiv has changed over time. The result is shown on Figure 5. According to this figure, as bioRxiv matures, it becomes a better leading indicator of PubMed. Perhaps more critically, it also shows that the content alignment is indeed changing.

We perform the same analysis as in Figure 4, except with a smaller window (two years) and shifting both bioRxiv (x-axis) and the starting month (y-axis). If x = 1 and y = 3, then the start month is April 2014 for PubMed and March 2014 for bioRxiv. The data are shown on a grid with darker red indicate high correlation and dark blue indicating low or inverse correlation. In general, we see higher correlation between bioRxiv and PubMed as bioRxiv matures.
The analysis we provide in this work at best is a glimpse into the relationship between pre-print servers and peer-reviewed journals. It will likely change as bioRxiv continues to mature.
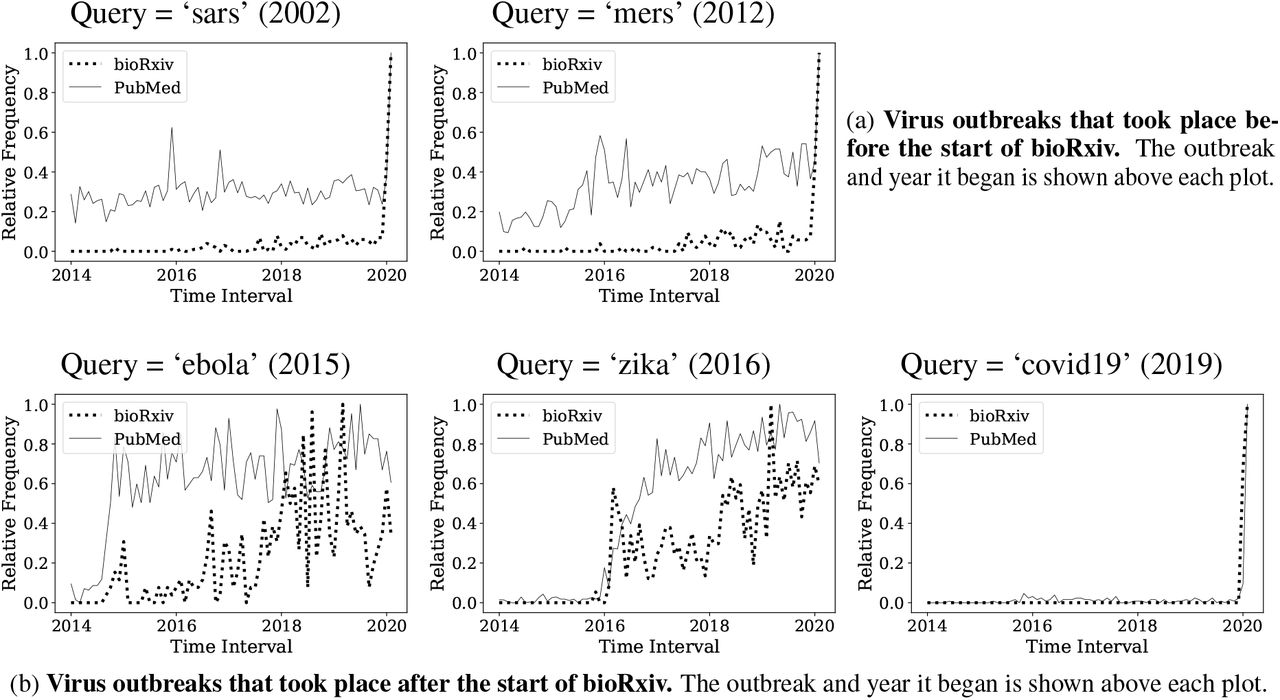
5.4 Qualitative analysis for the spread of ideas during virus outbreaks
During natural disasters such as virus outbreaks, scientific progress towards understanding diseases and their cures is critical, warranting fast dissemination of ideas and results of research. Pre-print servers are particularly well suited to this end. Thus we compare bioRxiv to PubMed for five recent virus outbreaks, some of which took place prior to the founding of bioRxiv.
Each virus outbreak was analyzed using a composite of publication frequency of multiple related phrases. For example, values for ‘sars-cov2’ and ‘covid-19’ are aggregated in the COVID-19 plot. The five relevant outbreaks are listed below:
Prior to bioRxiv establishment (before November 2013, Figure 6, top): MERS and SARS.
After bioRxiv establishment (Figure 6, bottom): Zika, Ebola, and COVID-19.

Outbreaks that occurred before bioRxiv became widespread (top row, a) with publishing activity plateaued in recent years v. outbreaks occurring after bioRxiv was founded (bottom row, b) with recent growth in research activity.
The first group of outbreaks exhibits the expected behavior: bioRxiv activity is fairly minimal given that the growth of research on those topics had begun to saturate by the time bioRxiv was formed. But the second group exhibits a different behavior. For Ebola outbreak, which took place in 2015, the activity in bioRxiv is fairly low compared to PMC. For Zika (2017) and Covid-19 (2019) bioRxiv has an early activity spike.
Through this analysis we can see that bioRxiv has become increasingly important in emergency situations during recent years.
6 Future Directions
Our work serves as a first attempt for discovering research impact of publication venues using full text analysis. One notable assumption we make is that all phrase mentions are treated equally. In the future, we may want to distinguish how a phrase is being used. For example, if the phrase of interest is z, then a research paper may write about works extending z, but alternatively it may simply discuss techniques similar to z. Similar analysis has provided useful for citations (Jurgens et al., 2018).
Furthermore, our approach leverages TextRank to find many relevant phrases, but we do not cluster phrases, so two or more phrases with similar meaning will be treated separately (i.e. FACS and Fluorescence Activated Cell Sorting). A simple alias table or string similarity extension (Tam et al., 2019) would be a clear improvement. Leveraging high precision concept extraction systems (King et al., 2020) might improve clustering even more.
Another approach would be to use a better proxy for ideas than textual phrase, like concepts or topics extracted from the corpus.
7 Conclusions
We introduce a Bayesian model for novelty detection (BAND), and use this model to investigate how quickly new ideas form on pre-print servers compared to peer-reviewed journals. Our findings indicate that novel phrases, which we use as a proxy for new ideas, in most cases appear on pre-print servers and in peer reviewed journals. In some cases, novel phrases appear on pre-print servers first. In many cases the content of preprints is a pre-dictor of the content of peer reviewed journals. As the preprint servers mature, this feature becomes more prominent. When a fast review time is in high demand (such as during epidemic outbreaks), pre-print servers have a high utility, and the related novel phrases appear on pre-print servers first.
Acknowledgments
The authors are grateful to Bill Burkholder (Chan Zuckerberg Biohub) who suggested this research, and to Barbara Vidal & Michaela Torkar (Chan Zuckerberg Initiative) for their expert help in selecting the phrases for comparison.
This research was initiated at the University of Massachusetts Amherst Industry Mentorship Program.
A Appendices
A.1 Summary of phrases found in data sources
In our experiments and analysis we primarily consider two data sources: bioRxiv (representative of pre-print servers) and PubMed (representative of peer-reviewed journals). We extract phrases using TextRank as described in Section 4.2. In this section of the appendix, we summarize the phrases considered in the experiments.
A.1.1 Phrases from TextRank
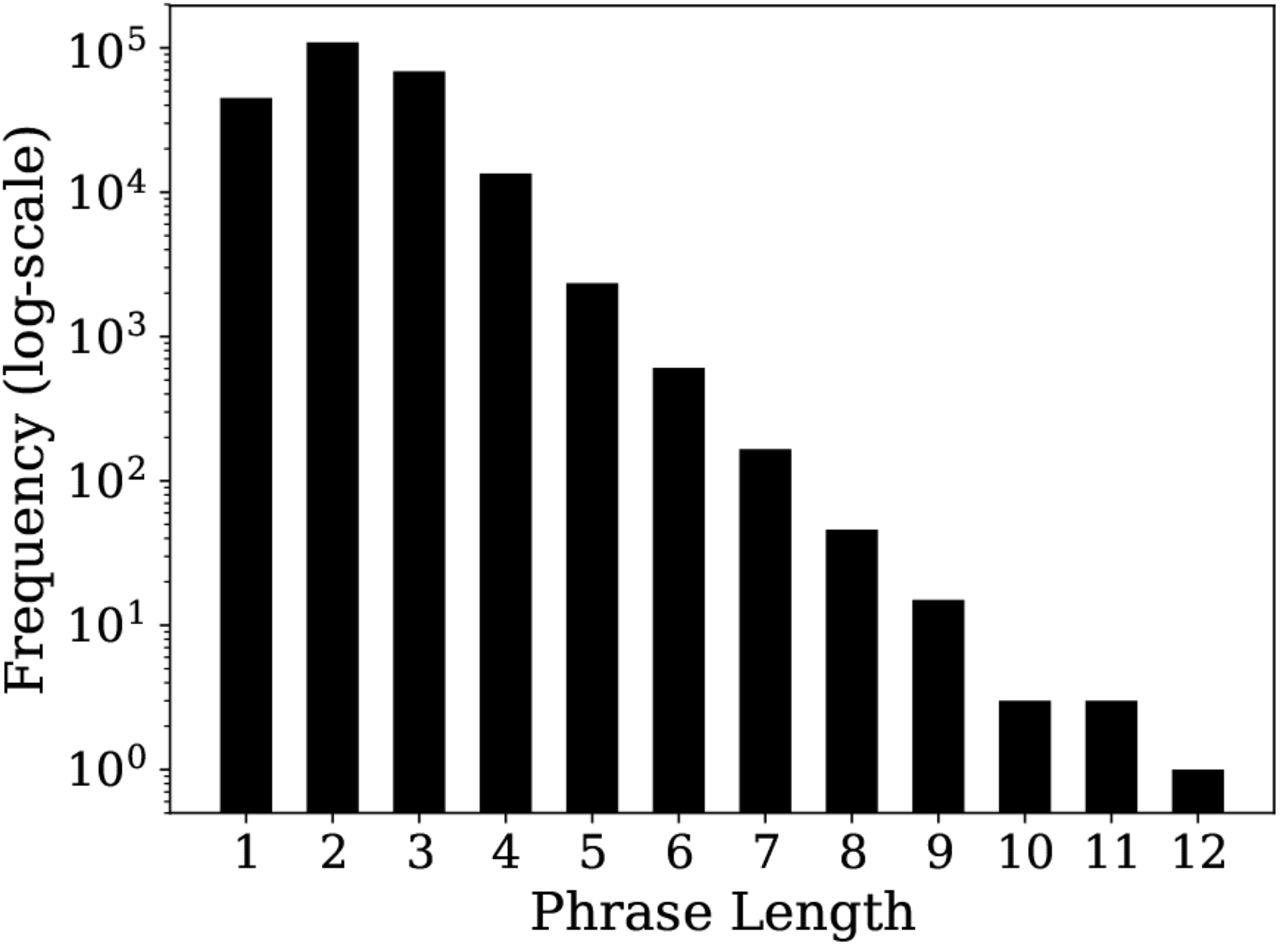
TextRank extracted 1,587,408 phrases from bioRxiv abstracts. We further filter this list to 239,608 by only including phrases that were detected by TextRank more than once. This does not necessarily mean that the phrases that were filtered only occur in the bioRxiv abstracts a single time but that TextRank only found it to be a key phrase once. The distribution of phrase lengths is shown in Figure 7. A sample of phrases is listed in Table 3.

Frequency of various phrase lengths that were extracted from our corpus using TextRank.
A.1.2 Phrases from Experts
To validate the effectiveness of BAND, we use a small set of curated phrases provided by experts at CZI. Those results are discussed in detail in Section 5.2. The complete list of phrases is shown in Table 1.
The list of phrases used in Section 5.2. These phrases were provided by experts at CZI.
A.2 Common phrases used in bio-medicine
In conducting the correlation study, explained in Section 5.3, we used a set of phrases that can be considered to be commonly used in biomedical literature. The complete list can be found in the Table 2.
The list of common phrases used in our correlation analysis in Section 5.3. These phrases are phrases that can be considered common in medical literature
The list of top ranked phrases from TextRank used in our correlation analysis Section 5.3.
A.2.1 Phrases for Crises
Pre-print servers are especially useful during crises such as pandemics. We chose 5 recent virus out-breaks to study their response which is discussed in Section 5.4: SARS, MERS, Ebola, Zika, and Covid-19. We made one compound time series curve for each virus’s frequency based occurrence in PubMed and bioRxiv. Table 4 shows two lists. The phrases are obtained using all ordered combinations of entries from column 2 and column 3. For example we can combine “SARS-Cov” and “epidemic” to form “SARS-Cov epidemic”. Each epidemic is associated with a set of phrases to form one compound set of phrases.
A reference table for constructing phrases used in 5.4. For each virus outbreak, the list of phrases consists of all combinations of the first component concatenated with the second component. For instance, ‘SARS epidemic’ or ‘COVID-19 forecasting’.
Footnotes
ssatish{at}cs.umass.edu, adrozdov{at}cs.umass.edu, zonghaiyao{at}cs.umass.edu
↵2 A minute percentage of titles are missing from the PubMed data. This is attributed to noisy data entry rather than some data being closed or open.
↵3 For computing time series, we simply count if a phrase occurred in a document independent of its importance score from TextRank. This approach scales easily to large corpora such as full text from PubMed papers.
↵4 A simple heuristic to get one changepoint is to use the first one, although this does not work universally well. Constraining WCPD to return a single changepoint (e.g. highest discrepancy) similarly does not consistently return the most desirable changepoints.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}