

Abstract
Molecular characterization of cell types using single cell transcriptome sequencing is revolutionizing cell biology and enabling new insights into the physiology of human organs. While most work has focused on specific organs, there is a need for a reference which enables comparisons of cell types between organs and tissues. We present a human single cell transcriptomic atlas comprising nearly 500,000 cells from 24 different tissues and organs, many from the same donor. This allows us to control for individual variation and enables characterization of more than 400 cell types, their distribution across tissues and tissue specific variation in gene expression. From this we identify the clonal distribution of T cells between tissues, the tissue specific mutation rate in B cells, and analyze the cell cycle state and proliferative potential of shared cell types across tissues. Finally, we characterize cell type specific RNA splicing and how such splicing varies across tissues within an individual.
One Sentence Summary We used single cell transcriptomics to create a molecularly defined phenotypic reference of human cell types which spans 24 human tissues and organs.
Introduction
Although the genome is often called the blueprint of an organism, it is perhaps more accurate to describe it as a parts list composed of the various genes which may or may not be used in the different cell types of a multicellular organism. Despite the fact that nearly every cell in the body has the same genome, each cell type makes different use of that genome and expresses a subset of all possible genes (1). Therefore, the genome in and of itself does not provide an understanding of the molecular complexity of the various cell types of that organism. This has motivated efforts to characterize the molecular composition of various cell types within humans and multiple model organisms, both by transcriptional (2) and proteomic (3, 4) approaches.
While such efforts are yielding insights and producing data (5–7), one caveat to current approaches is that individual organs are often collected at different locations, from different donors (8) and processed using different protocols, or lack replicate data (9). Controlled comparisons of cell types between different tissues and organs are especially difficult when donors differ in genetic background, age, environmental exposure, and epigenetic effects. To address this, we developed an approach to analyzing large numbers of organs from the same individual (10), which we originally used to characterize age-related changes in gene expression in various cell types in the mouse (11).
Data Collection and Cell Type Representation
We collected multiple tissues from individual human donors (designated TSP 1-15) and performed coordinated single cell transcriptome analysis on live cells (12). We collected 17 tissues from one donor, 14 tissues from a second donor, and 5 tissues from two other donors (Fig. 1). We also collected smaller numbers of tissues from a further 11 donors, which enabled us to analyze biological replicates for nearly all tissues. The donors comprise a range of ethnicities, are balanced by gender, have a mean age of 51 years and a variety of medical backgrounds (table S1). Tissues were processed consistently across all donors. Fresh tissues were collected from consented brain-dead transplant donors through an organ procurement organization (OPO) and transported immediately to tissue experts where each tissue was dissociated. For some tissues the dissociated cells were purified into compartment-level batches (immune, stromal, epithelial and endothelial) and then recombined into balanced cell suspensions in order to enhance sensitivity for rare cell types (12).

The Tabula Sapiens was constructed with data from 15 human donors; for detailed information on which tissues were examined for each donor please refer to table S2. Demographic and clinical information about each donor is listed in the supplement and in table S1. Donors 1, 2, 7 and 14 contributed the largest number of tissues each, and the number of cells from each tissue is indicated by the size of each circle. Tissue contributions from additional donors who contributed single or small numbers of tissues are shown in the “Additional donors” column, and the total number of cells for each organ are shown in the final column.
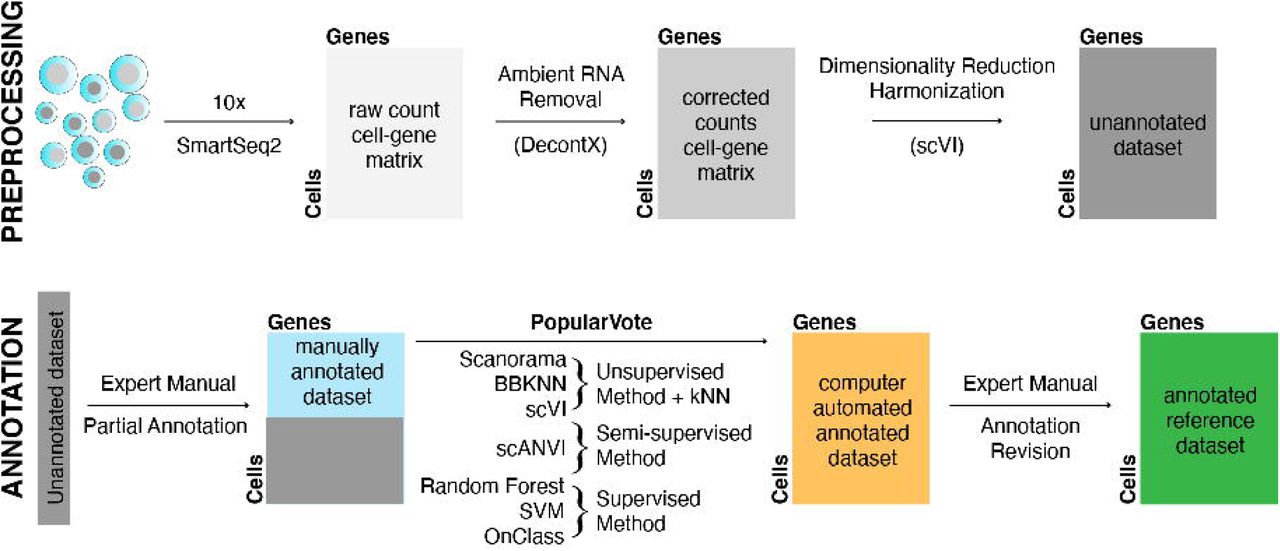
Single cell transcriptome sequencing was performed with both FACS sorted cells in well plates with smartseq2 amplification as well as 10x microfluidic droplet capture and amplification for each tissue (fig. S1). The raw data was processed to remove low quality cells, projected into a lower-dimensional latent space using scVI (13), and visualized with UMAP (14) (fig. S2). Next, the tissue experts used cellxgene (15) to annotate the cells that could be confidently identified by marker gene expression (12). These annotations were verified through a combination of automated annotation (16) and manual inspection (12). A defined Cell Ontology terminology was used to make the annotations consistent across the different tissues (17), leading to a total of 475 distinct cell types with reference transcriptome profiles (tables S2, S3). The full dataset can be explored online with the cellxgene tool via a data portal located at (18).

Data was collected for bladder, blood, bone marrow, eye, fat, heart, kidney, large intestine, liver, lung, lymph node, mammary, muscle, pancreas, prostate, salivary gland, skin, small intestine, spleen, thymus, tongue, trachea, uterus and vasculature. 59 separate specimens in total were collected, processed, and analyzed, and 481,120 cells passed QC filtering (figs. S3-S7 and table S2). On a per compartment basis, the dataset includes 264,009 immune cells, 102,580 epithelial cells, 32,701 endothelial cells and 81,529 stromal cells. Working with live cells as opposed to isolated nuclei ensured that the dataset includes all mRNA transcripts within the cell, including transcripts that have been processed by the cell’s splicing machinery, thereby enabling insight into variation in alternative splicing.





For several of the tissues we also performed literature searches and collected tables of prior knowledge of cell type identity and abundance within those tissues (table S4). We compared literature values with our experimentally observed frequencies for three well annotated tissues: lung, muscle and bladder (fig. S8). We observed surprisingly good correspondence in these frequencies, especially considering that the single cell data was obtained on dissociated tissues and that some compartments were enriched. Dissociation is known to alter the representation of various cell types and generally to increase the representation of immune cell types at the expense of others. The balancing process used on some tissues creates another distortion to absolute representation, but not to the extent that the compartments become completely equalized and thus some aspects of the original representation statistics are preserved.

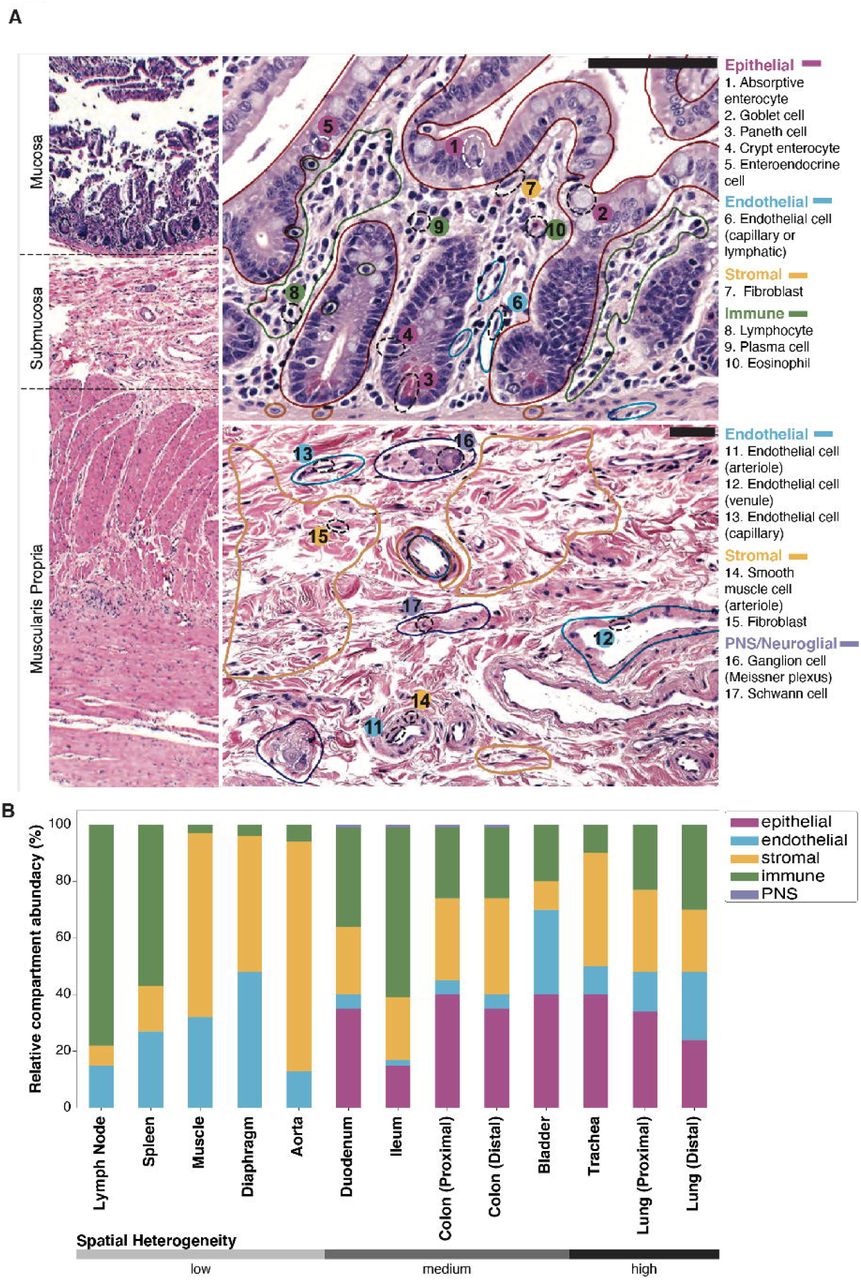
To further characterize the relationship between transcriptome data and conventional histologic analysis of tissue, a team of trained pathologists analyzed H&E stained sections prepared from 9 tissues from donor TSP2 and 13 tissues from donor TSP14 (18). Cells were identified by morphology and classified broadly into epithelial, endothelial, immune and stromal compartments, as well as rarely detected peripheral nervous system (PNS) cell types. In some cases, finer cell type classification was also performed. An example of such cellular and compartmental identification is illustrated in the case of the distal small intestine (Fig. 2A). These classifications were used to estimate the relative abundances of cell types across four compartments, as well as to the uncertainties in these abundances due to spatial heterogeneity of each tissue type (Fig. 2B, fig. S9). We compared the histologically determined abundances with those obtained by single cell sequencing (fig. S10). Although, as expected, there can be substantial variation between the abundances determined by these methods, in aggregate we observe broad concordance over a large range of tissues and relative abundances. This approach enables an estimate of true cell type proportions for organs where the compartments were purified, and more generally in every organ since not every cell type survives dissociation with equal efficiency (19). The histology images of the tissue are available as part of the online data portal (18).


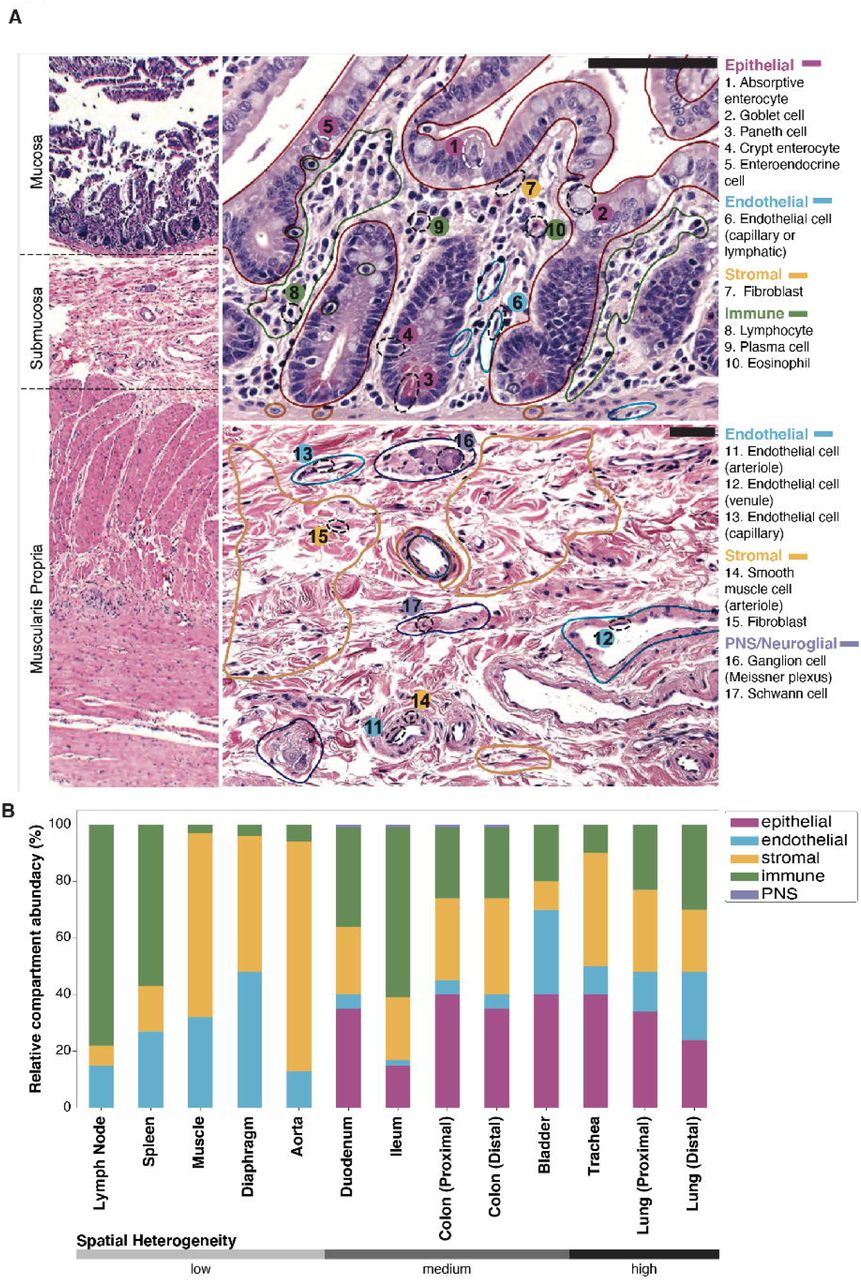
Clinical pathology was performed on nine tissues from donors TSP2 and TSP13. A. Hematoxylin and eosin (H&E) stained image used for histology of the colon from TSP2, with compartments (solid, colored lines) and individual cell types (dashed black ellipses) identified by the pathologists. B. Coarse cell type representation of TSP2 as morphologically estimated by pathologists across several tissues, ordered by increasing heterogeneity of the tissue. Compartment colors are consistent between panels A and B.
Immune Cells: Variation in Gene Expression Across Tissues and a Shared Lineage History
The Tabula Sapiens can be used to study subtle differences in the gene expression programs and lineage histories of cell types that are shared across tissues. Importantly, these analyses were performed after correcting counts for potential ambient mRNA contamination and dissociation artifacts (12), which would otherwise result in the detection of differentially expressed genes (DEGs) that are specific to a tissue rather than to the cell type of interest. We first examined immune cells, which are born in one niche, circulate through the body, and home into other niches where they stay over time scales ranging from minutes to years. We identified tissue-specific gene expression features for most immune cell ontology classes via classical DEG analysis.
Here we focus on the signatures of tissue similarity and differences in the 36,475 macrophages distributed amongst 20 tissues, as tissue-resident macrophages are known to carry out specialized functions in different tissues and under different conditions. These shared and orthogonal signatures are summarized in a correlation map (fig. S11A). For example, macrophages in the spleen were different from most other macrophages, and this was driven largely by higher expression of CD5L (fig. S11B). We also observed a shared signature of elevated EREG expression in solid tissues such as the skin, uterus and mammary compared with EREG expression in circulatory tissues (fig. S11B).

Macrophages likely secrete abnormal levels of EREG during cancer-progression and facilitate the tumor micro-environment (20), but secretion of such factors also has a role in the homeostatic maintenance of tissues (21). We observed an antimicrobial phenotype of macrophage in the lung and lymph node characterized by CHIT1 expression (fig. S11B). Interestingly, macrophages in the lymph nodes co-expressed CHIT1 and CTSK, while CTSK was largely not expressed in the lung (fig. S11B). Like EREG, CTSK is thought to have roles in cancer metastasis as well as normal tissue regulation and these data provide insight into tissue-specific specializations and functional differences of macrophages (22, 23).
To characterize the lineage relationships between T cells in organs we performed computational assembly of the T cell receptor sequence from T cells sequenced via Smartseq2 from donor TSP2. Multiple T cell lineages were distributed across various tissues in the body, and we mapped their relationships (Fig. 3A). Large clones were often found to reside in multiple organs, and several clones of Mucosal Associated Invariant T cells were shared across donors; we identified these cells by their characteristic expression of TRAV1-2 as they are thought to be innate-like effector cells (24).

Illustration of clonal distribution of T cells across multiple tissues. The majority of T cell clones are found in multiple tissues and represent a variety of T cell subtypes. B. Prevalence of B cell isotypes across tissues, ordered by decreasing abundance of IgA. C. Expression level of tissue specific endothelial markers, shown as violin plots, in the entire dataset. Many of the markers are highly tissue specific, and typically derived from multiple donors as follows: bladder (3 donors), eye (2), fat (2), heart (1), liver (2), lung (3), mammary (1), muscle (4), pancreas (2), prostate (2), salivary gland (2), skin (2), thymus (2), tongue (2), uterus (1) and vasculature (2). A detailed donor-tissue breakdown is available in table S2.
Lineage information can also be used to measure the level of tissue-specific somatic hyper-mutation in B cells. We computationally assembled the B Cell Receptor (BCR) gene from Smartseq2 data from donor TSP2 and then inferred the germline ancestor of each cell. The mutational load varies dramatically by tissue of residence, with blood have the lowest mutational load compared to all of the solid tissues (fig. S11D); in quantitative terms solid tissues have an order of magnitude more mutations per nucleotide (mean=0.076, s.d.=0.026) compared to the blood (0.0069), suggesting that the immune infiltrates of solid tissues are dominated by mature B cells.
B cells also undergo class-switch recombination which diversifies the humoral immune response by using constant region genes with distinct roles in immunity. We classified every B cell in the dataset as IgA, IgG, or IgM expressing and then calculated the relative amounts of each cellular isotype in each tissue (Fig. 3B, table S5). Secretory IgA is known to interact with pathogens and commensals at the mucosae, IgG is often involved in direct neutralization of pathogens, and IgM is typically expressed in naive B cells or secreted in first response to pathogens. Consistent with these functions, our analysis revealed opposing gradients of prevalence of IgA and IgM expressing B cells across the tissues with blood having the lowest relative abundance of IgA producing cells and the large intestine having the highest relative abundance, and the converse for IgM expressing B cells (Fig. 3B).
Endothelial Cells Subtypes with Tissue-Specific Gene Expression Programs
As another example application of using the Tabula Sapiens to analyze shared cell types across organs, we focused on endothelial cells (ECs). These cells line the surface of blood vessels and together form a conduit allowing for inter-tissue communication, oxygen, nutrient and waste exchange, and tissue-level homeostasis. While ECs are widely categorized as a single cell type, they exhibit differences in morphology, structure, immunomodulatory and metabolic phenotypes depending on their tissue of origin. Here, we discovered that tissue-specificity is also reflected in their transcriptomes, as ECs mainly cluster by tissue-of-origin (table S6). UMAP analysis (fig. S12A) revealed that lung, heart, uterus, liver, pancreas, fat and muscle ECs exhibited the most distinct transcriptional signatures, reflecting their highly specialized roles. These distributions were conserved across donors (fig. S12B).

Interestingly, ECs from the thymus, vasculature, prostate, and eye were similarly distributed across several clusters, suggesting not only similarity in transcriptional profiles but in their sources of heterogeneity. Differential gene expression analysis between ECs of these 16 tissues revealed several canonical and previously undescribed tissue-specific vascular markers (Fig. 3C). These data recapitulate tissue-specific vascular markers such as LCN1 (tear lipocalin) in the eye, ABCG2 (transporter at the blood-testis barrier) in the prostate, and OIT3 (oncoprotein induced transcript 3) in the liver. Of the potential novel markers determined by this analysis, SLC14A1 (solute carrier family 14 member 1) appears to be a new specific marker for endothelial cells in the heart, whose expression was independently validated with data from the Human Protein Atlas (25) (fig. S13). Vascular-bed specific genes could provide further insight into tissue-specific homeostatic mechanisms, as well as allow for EC tissue-specificity to be deconvolved in experiments like flow cytometry.

Notably, lung ECs formed two distinct populations, which is in line with the aerocyte (aCap- EDNRB+) and general capillary (gCap - PLVAP+) cells described in the mouse and human lung (26) (fig. S12 C,D). The transcriptional profile of gCaps were also more similar to ECs from other tissues, indicative of their general vascular functions in contrast to the more specialized aCap populations. Lastly, we detected two distinct populations of ECs in the muscle, including a MSX1+ population with strong angiogenic and endothelial cell proliferation signatures, and a CYP1B1+ population enriched in metabolic genes, suggesting the presence of functional specialization in the muscle vasculature (fig. S12 E,F).
Alternative Splice Variants are Cell Type Specific
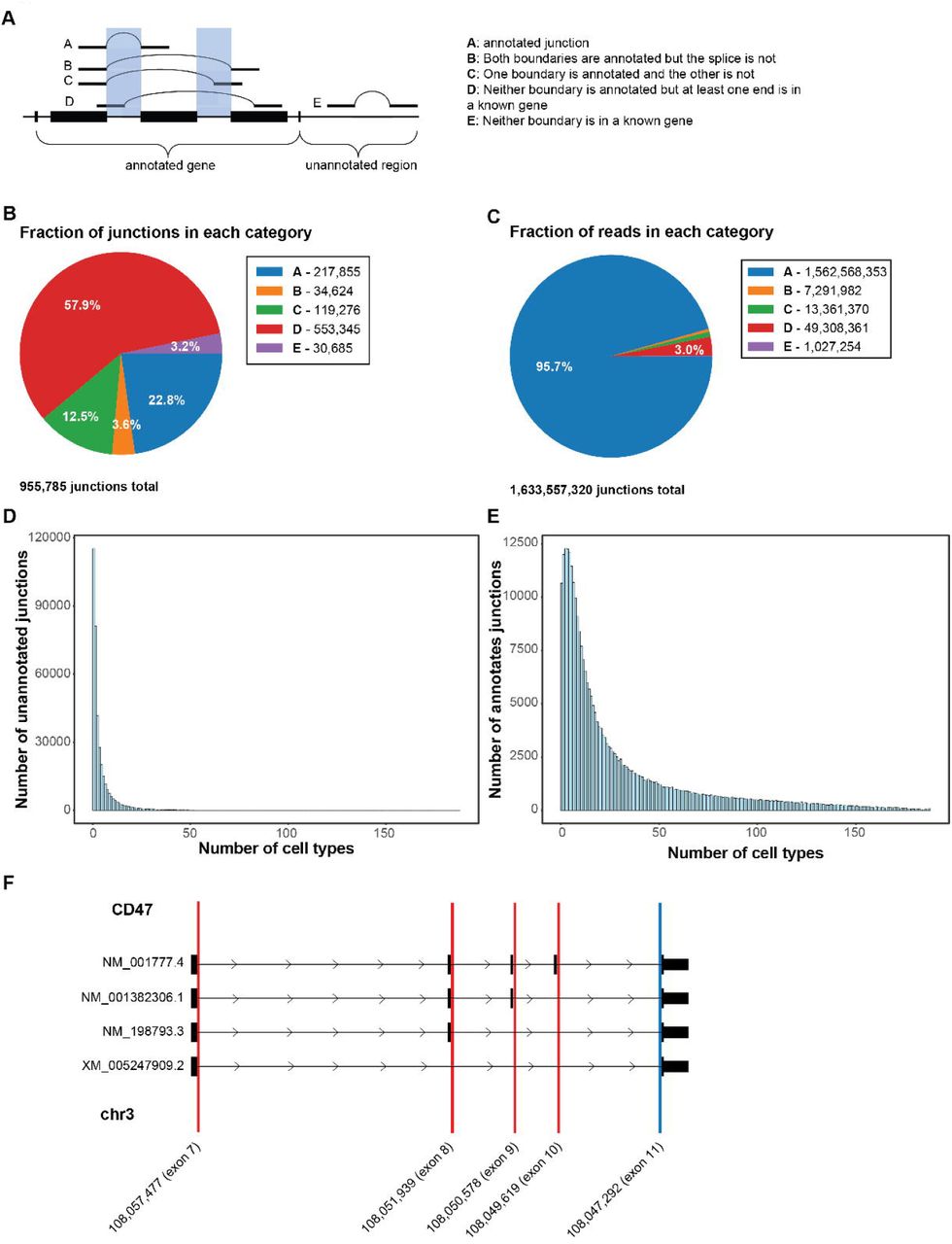
The Tabula Sapiens can also be used to understand cell type specific usage of alternative splicing. The GRCH38 RefSeq genome annotation contains 37,344 genes with multiple annotated exons, 21,923 of which have multiple annotated transcripts, totaling 169,061 splice variants derived from 328,603 possible splice junctions (27). Yet the function of alternative splicing and the extent to which regulation is cell type specific remains largely unexplored. We used SICILIAN (28), a statistical method that removes false positive spliced alignments due to technical artifacts, to identify splice junctions in the Tabula Sapiens corpus. Among other statistical filters, SICILIAN requires each called junction to have at least two supporting reads and has an estimated false positive rate of 2.8%.
SICILIAN detected a total of 955,785 junctions (fig. S14A-E, table S7). Of these, 217,855 were previously annotated, and thus our data provides independent validation of 61% of the total junctions catalogued in the entire RefSeq database. Although annotated junctions made up only 22.8% of the unique junctions, they represent 93% of total reads, indicating that previously annotated junctions tend to be expressed at higher levels than novel junctions. We additionally found 34,624 novel junctions between previously annotated 3’ and 5’ splice sites (3.6%). We also identified 119,276 junctions between a previously annotated site and a novel site in the gene (12.4%). This leaves 584,030 putative junctions for which both splice sites were previously unannotated, i.e. about 61% of the total detected junctions. Most of these have at least one end in a known gene (94.7%), while the remainder represent potential new splice variants from unannotated regions (5.3%). In the absence of independent validation, we conservatively characterized all of the unannotated splices as putative novel junctions. We then used the GTEx database (29) to seek independent corroborating evidence of these putative novel junctions, and found that reads corresponding to nearly one third of these novel junctions can be found within GTEx data (table S7); this corresponds to more than 300,000 new validated splice variants revealed by the Tabula Sapiens.

Hundreds of splice variants are used in a highly cell-type specific fashion; these can be explored in the cellxgene browser (18) which uses a statistical approach for detecting cell-type-specific splicing called the SpliZ (30). Here we focus on two examples of cell type specific usage of two well studied genes: MYL6 and CD47. Both genes are ubiquitously expressed yet are highly regulated in single cells at the level of splicing (Fig. 4). Similar cell-type specific splice usage was also observed with TPM1, TPM2, and ATP5F1C, three other genes with well-characterized splice variants (fig. S15). MYL6 is an “essential light chain” (ELC) for myosin (as opposed to Ca2+-sensitive “regulatory light chains” (RLCs) such as calmodulin), and is highly expressed in all tissues and compartments. Yet, splicing of MYL6, in particular involving the inclusion/exclusion of exon 6 (Fig. 4A) varies in a cell-type and compartment-specific manner (Fig. 4B). The two isoforms differ by 5 amino acids in the C-terminal helix, which is in close contact with the myosin lever arm; some studies suggest that the - exon6 isoform confers on myosin a faster shortening velocity (31). While the -exon6 isoform has previously been mainly described in phasic smooth muscle (32), the Tabula Sapiens atlas shows that it can also be the predominant isoform in non-smooth-muscle cell types. Our analysis establishes pervasive regulation of MYL6 splicing in many cell types, such as endothelial and immune cells. Further, these previously unknown compartment-specific expression patterns of the two MYL6 isoforms are reproduced in multiple individuals from the Tabula Sapiens dataset (Fig. 4A,B) and using both 10X and Smart-Seq2 sequencing technologies.


A,B. The sixth exon in MYL6 is skipped at different proportions in different compartments. Cells in the immune and epithelial compartments tend to skip the exon, whereas cells in the endothelial and stromal compartments tend to include the exon. Boxes are grouped by compartment and colored by tissue. The fraction of junctional reads that include exon 6 was calculated for each cell with more than 10 reads mapping to the exon skipping event. Only shared cell types with more than 10 cells with spliced reads mapping to MYL6 are shown. Horizontal box plots in B show the distribution of exon inclusion in each cell type (point outside of 1.5*IQR are plotted individually). C,D. Alternative splicing in CD47 involves one 5’ splice site (exon 11, 108,047,292) and four 3’ splice sites. Horizontal box plots in D show the distribution of weighted averages of alternative 3’ splice sites (based on read counts and using exon numbers) in each cell type. Epithelial cells tend to use closer exons to the 5’ splice site compared to immune and stromal cells. Boxes are grouped by compartment and colored by tissue. The average splice site rank was calculated for each cell with more than one read corresponding to the splice site. Only shared cell types with more than 5 cells with spliced reads mapping to CD47 are shown. Both genes were found significant (controlled FDR< 0.05) by the SpliZ analysis (30).
As another example, CD47 is a multi-spanning membrane protein involved in many cellular processes, including angiogenesis, cell migration, and as a “don’t eat me” signal to macrophages (33). Targeting the latter function has been promising for treating some myeloid malignancies (34). CD47 has complex splicing patterns that include alternative inclusion of at least 4 different exons immediately adjacent to the signaling domain ending at the 3’ splice splice site at exon 11 (fig. S14F). Differential use of exons 7-10 (Fig. 4C and fig. S14F) compose a variably long cytoplasmic tail (35). Immune cells – but also stromal and endothelial cells – have a distinct, consistent splicing pattern in CD47 that dominantly excludes two proximal exons and splicing directly to exon 8. In contrast to other compartments, epithelial cells exhibit a different splicing pattern that increases the length of the cytoplasmic tail by splicing more commonly to exon 9 and exon 10 (Fig. 4D). Characterization of the splicing programs of CD47 in single cells may have implications for understanding the differential signaling activities of CD47 and for understanding potentially therapeutic manipulation of CD47 function.
Cell State Dynamics Can Be Inferred From A Single Time Point
Although the Tabula Sapiens was created from a single moment in time for each donor, it is possible to infer various forms of dynamic information about the cells from the data. For example, one of the most important transient changes of internal cell state is cell division. We computed a cycling index for each cell type across all organs to identify actively proliferating versus quiescent or post-mitotic cell states. This index was derived on the basis of the log ratio of the number of cycling to non-cycling cells for each cell type, determined by high confidence cell cycle markers for G1-M phases (G1/S markers: CEP57, CDCA7L; S markers: ABHD10, CCDC14, CDKN2AIP, NT5DC1, SVIP, PTAR1; G2 makers: ANKRD36C, YEATS4, DCTPP1; G2/M markers: SMC4, TMPO, LMNB1, HINT3; M markers: HMG20B, HMGB3, HPS4) to indicate cycling and G0 phase markers (CDKN1A, CDKN1B, CDKN1C) for non-cycling (12).
We observed that rapidly dividing progenitor cells had among the highest cycling indices, while cell types mostly from the endothelial and stromal compartments, which are known to be largely quiescent, had low cycling indices (Fig. 5A). In intestinal tissue, transient amplifying cells and the crypt stem cells divide rapidly in the intestinal crypts to give rise to terminally differentiated cell types of the villi (36). These cells were ranked with the highest cycling indices whereas terminally differentiated cell types such as the goblet cells had the lowest ranks (fig. S16A). To complement the computational analysis of cell cycling, we performed immunostaining of intestinal tissue for MKI67 protein (commonly referred to as Ki-67) and confirmed that transient amplifying cells abundantly express this proliferation marker (fig. S16B,C), supporting that this marker is differentially expressed in the G2/M cluster.


A. Cell types ordered by magnitude of cell cycling index, per donor (each a separate color) with the most highly proliferative at the top and quiescent cells at the bottom of the list. B. RNA velocity analysis demonstrating mesenchymal to myofibroblast transition in the bladder. The arrows represent a flow derived from the ratio of unspliced to spliced transcripts which in turn predicts dynamic changes in cell identity. C,D. Latent time analysis of the mesenchymal to myofibroblast transition in the bladder demonstrating stereotyped changes in gene expression trajectory.
We observed several interesting tissue-specific differences in cell cycling. To illustrate one example, UMAP clustering of macrophages showed tissue-specific clustering of this cell type, and that blood, bone marrow, and lung macrophages have the highest cycling indices compared to macrophages found in the bladder, skin, and muscle (fig. S16D-G). Consistent with this finding, the expression values of CDK-inhibitors (in particular the gene CDKN1A), which block the cell cycle, have the lowest overall expression in macrophages from tissues with high cycling indices (fig. S16F).
As a further example of how the Tabula Sapiens can be used to reveal cell state dynamics, we used RNA velocity (37) to study trans-differentiation of bladder mesenchymal cells to myofibroblasts (Fig. 5B). This process is important for tissue remodeling and healing, and if left unchecked can result in fibrosis. Myofibroblasts produce different components of the ECM such as collagen and fibronectin. RNA velocity captures the ratio of unspliced to spliced RNA on a per-gene basis, and thus provides temporal information (37, 38). RNA velocities across many genes are used to infer a latent temporal axis on which cells undergoing a dynamic process such as differentiation can be ordered on. The inferred transitions on this temporal axis as bladder mesenchymal cells transdifferentiate to myofibroblasts are shown. Latent time analysis, which provides an estimate of each cell’s internal clock using RNA velocity trajectories (39), correctly identified the direction of differentiation without requiring specification of root cells (Fig. 5C). Similar trajectories were found across multiple donors. Finally, the ordering of cells as a function of latent time shows clustering of the mesenchymal and myofibroblast gene expression programs for the most dynamically expressed genes (Fig. 5D). Among these genes, ACTN1 (Alpha Actinin 1) – a key actin crosslinking protein that stabilizes cytoskeleton-membrane interactions (40) – increases across the mesenchymal to myofibroblast trans-differentiation trajectory (fig. S16H). Another gene with a similar trajectory is MYLK (myosin light-chain kinase), which also rises as myofibroblasts attain more muscle-like properties (41). Finally, a random sampling of the most dynamic genes shared across TSP1 and TSP2 demonstrated that they share concordant trajectories and revealed some of the core genes in the transcriptional program underlying this trans-differentiation event within the bladder (fig. S16I).
Unexpected Spatial Variation in the Microbiome
Imbalances in the interactions between the gut microbiome and the host immune system impact are linked to many region-specific intestinal diseases (42, 43), and stool is not necessarily representative of the spatially distinct microbial (44) and immune (45) niches throughout the intestinal tract. Despite its importance, the spatial heterogeneity of the microbiome remains understudied and largely unknown. The Tabula Sapiens provided an opportunity to densely and directly sample the human microbiome throughout the gastrointestinal tract. The intestines from donors TSP2 and TSP14 were sectioned into five regions: the duodenum, jejunum, ileum, and ascending and sigmoid colon (Fig. 6A). Each section was transected, and three to nine samples of ∼1 g of digesta were collected from each location using an inoculating loop (23 samples in total from TSP2 and 30 samples from TSP14).
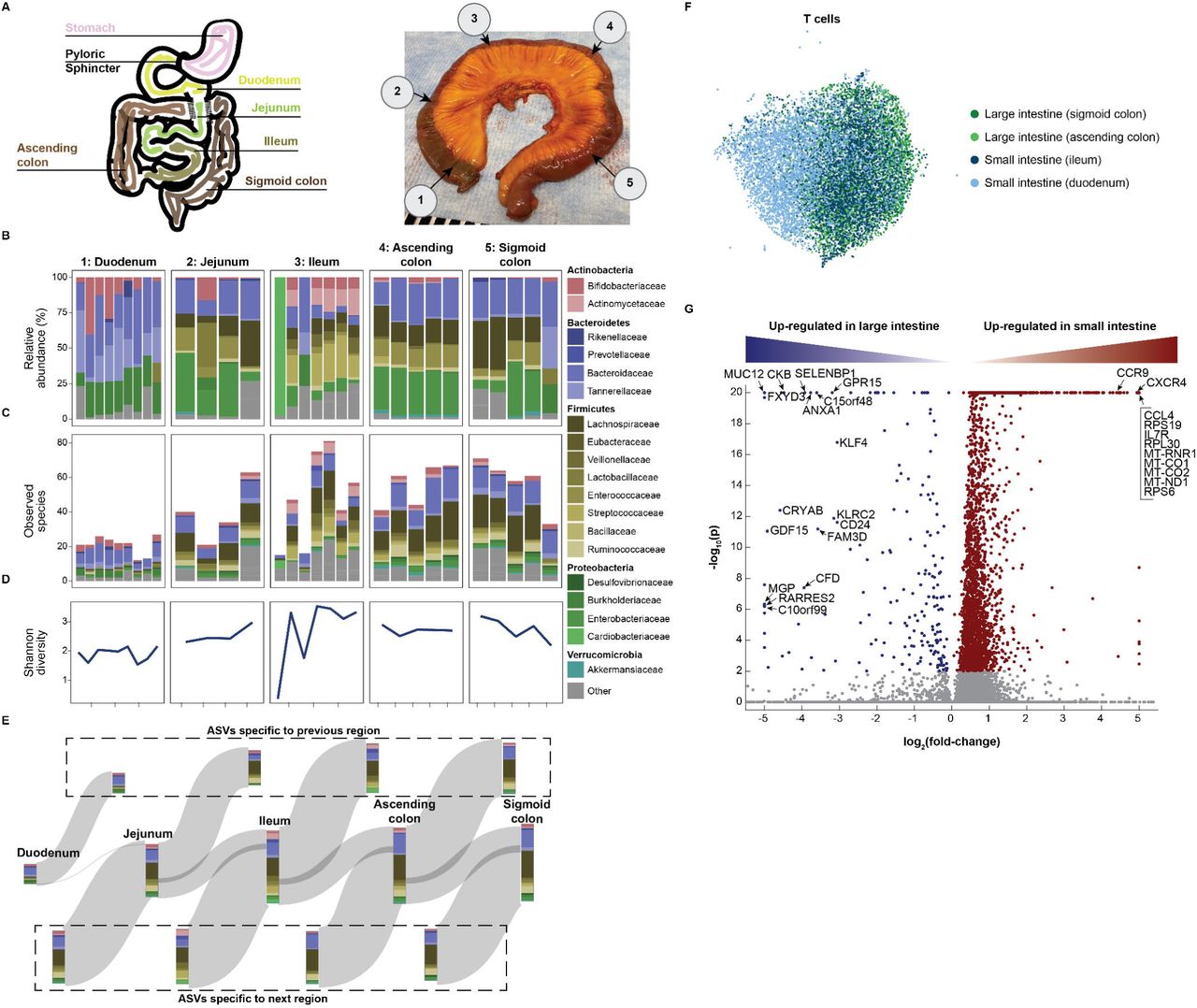
A. Schematic (left) and photo of the colon from donor TSP2 (right), with numbers 1-5 representing microbiota sampling locations. B-D. Relative abundances (B) and richness (number of observed species, C) at the family level in each sampling location, as determined by 16S rRNA sequencing. The Shannon diversity (D), a metric of evenness, mimics richness. Variability in relative abundance and/or richness/Shannon diversity was higher in the duodenum, jejunum, and ileum as compared with the ascending and sigmoid colon. E. A Sankey diagram showing the inflow and outflow of microbial species from each section of the gastrointestinal tract. The stacked bar for each gastrointestinal section represents the number of observed species in each family as the union of all sampling locations for that section. The stacked bar flowing out represents gastrointestinal species not found in the subsequent section and the stacked bar flowing into each gastrointestinal section represents the species not found in the previous section. F. UMAP clustering of T cells reveals distinct transcriptome profiles in the distal and proximal small and large intestines. G. Dots in volcano plot highlight genes up-regulated in the large (left) and small (right) intestines. Labeled dots include genes with known roles in trafficking, survival, and activation.
The taxonomic composition of the microbiome was characterized by amplifying the 16S rRNA gene from all samples. Uniformly there was a high (∼10-30%) relative abundance of Proteobacteria, particularly Enterobacteriaceae (Fig. 6B), even in the colon. Enterobacteriaceae are rarely found at such high abundance in stool, hence this high relative abundance may be due to the postmortem state of the donor. Most samples within the sigmoid and ascending colon were similar to each other, although the relative abundances of the Proteobacteria phylum and Lachnospiraceae family were variable in the sigmoid colon. By contrast, samples from each of the duodenum, jejunum, and ileum were largely distinct from one another, with samples exhibiting individual patterns of blooming or absence of certain families (Fig. 6B). These data reveal that the microbiota is patchy even at a 3-inch length scale. We observed similar heterogeneity in the spatial pattern of TSP2’s microbiome (fig. S17A-C).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In the small intestine, richness (number of observed species) was also variable, and was negatively correlated with the relative abundance of Burkholderiaceae (Fig. 6C); in TSP2, the Proteobacteria phylum was dominated by Enterobacteriaceae, which was present at >30% in all samples at a level negatively correlated with richness (fig. S17A-C). Shannon diversity largely mimicked the number of observed species (Fig. 6D). In a comparison of species from adjacent regions across the gut, a large fraction of species was unique to each region (Fig. 6E), reflecting the patchiness. The average number of unique ASVs (a proxy for species) in each sample was 41.4±21.1 for the five regions of TSP14, and within each location, samples in the duodenum, jejunum, and ileum exhibited 1.83±1.6, 8.5±4.4, and 11.4±6.9 unique ASVs, respectively, compared with 18.2±8.2 and 16.2±7.9 for the ascending and sigmoid colon, respectively. These numbers indicate that ∼25% of the ASVs in each sample were unique when comparing to other samples from the same region. For TSP2, somewhat higher fractions of unique ASVs were observed in the small intestine and very few ASVs were unique to the colon (both in comparisons across regions and within each region, fig. S17D), indicating greater patchiness in the SI of this donor.
To compare our findings to existing fecal microbiome data, we analyzed the prevalence of each of the 601 ASVs detected across all TSP14 samples to a set of stool samples collected from healthy individuals in a separate study. Of the 1193 ASVs detected in the stool samples, only 31 were also found in TSP14 samples, of which 7 were specific to the small intestine, 9 were specific to the colon, and 15 were found in both the small and large intestine. The 31 ASVs were typically found in only a few of the stool samples (4.0±3.5), highlighting the unique aspect of the ASVs that we observed in the small intestine.
We analyzed host immune cells in conjunction with the spatial microbiome data; UMAP clustering analysis revealed that the small intestine T cell pool from TSP14 contained a population with distinct transcriptomes (Fig. 6F). The most significant transcriptional differences in T cells between the small and large intestine were genes associated with trafficking, survival, and activation (Fig. 6G, table S8). For example, expression of the long non-coding RNA MALAT1, which impacts the regulatory function of T cells, and CCR9, which mediates T lymphocyte development and migration to the intestine (46), were high only in the small intestine, while GPR15 (colonic T cell trafficking), SELENBP1 (selenium transporter), ANXA1 (repressor of inflammation in T cells), KLRC2 (T cell lectin), CD24 (T cell survival), GDF15 (T cell inhibitor), and RARRES2 (T cell chemokine) exhibited much higher expression in the large intestine. Within the epithelial cells, we observed distinct transcriptomes between small and large intestine Paneth cells and between small and large intestine enterocytes, while there was some degree of overlap for each of the two cell types for either location (fig. S17E,F). The site-specific composition of the microbiome in the intestine, paired with distinct T cell populations at each site helps to define local host-microbe interactions that occur in the GI tract and is likely reflective of a gradient of physiological conditions that influence host-microbe dynamics.
Conclusion
The Tabula Sapiens is unique in being constructed from live cells from multiple-organ donors and including biological replicates from more than one donor. It is part of a growing set of data which when analyzed together will enable many interesting comparisons of both a biological and a technical nature. For example, choosing a particular cell type and studying it across organs, datasets, and species will yield new biological insights – as was demonstrated recently with fibroblasts (47). As another example, one can compare gene expression in fetal human cell types (48) to those determined here in adults to glean insight into the effects of aging and the loss of plasticity from early development to maturity. Many of these datasets were created with different technical approaches and having data from cell types shared across many organs may facilitate the development of normalization methods to compare such diverse data – and also may enable better understanding of technical artifacts introduced by the various approaches (8, 9, 49, 50). The Tabula Sapiens has enabled several discoveries relating to shared behavior or subtle organ specific differences across a number of cell types. For example, we found specific T cell clones which are shared between organs, and characterized organ dependent hypermutation rates amongst B cells. Cell types which are shared across tissues often show subtle but clear differences in gene expression, as we found with both endothelial cells and macrophages. We found an unexpectedly large and diverse amount of cell-type specific RNA splice variant usage, and discovered and validated many new splices. Finally, we performed direct spatial characterization of microbiome diversity and related that to gene expression in resident immune cells. These are but a few examples of how the Tabula Sapiens represents a broadly useful reference to understand and explore human biology deeply at cellular resolution. We expect that, similar to the human genome project, over time the release of updated versions of Tabula Sapiens will incorporate data from additional donors and include further refinements in the cell type annotations.
Brief synopsis of methods
Fresh whole non-transplantable organs, or 1-2cm2 organ samples, were obtained from surgery and then transported on ice by courier as rapidly as possible to individual tissue expert labs where they were immediately prepared for transcriptome sequencing. When available, a 1-2 cm2 sample was preserved in Formalin for histological analysis. For each organ/tissue, single-cell suspensions were prepared for 10x Genomics 3’ V3.1 droplet-based sequencing and for FACS sorted 384-well plate Smart-seq2. Preparation began with dissection, digestion with enzymes and physical manipulation; the details of which are tissue specific and explained in the methods supplement (12). To detect as many cell types as possible, the cell suspensions from some organs were normalized by major cell compartment (epithelial, endothelial, immune, and stromal) using antibody-labelled magnetic microbeads to enrich rare cell types. cDNA and sequencing libraries were prepared and run on the Illumina NovaSeq 6000 with the goal to obtain 10,000 droplet-based cells and 1000 plate-based cells for each organ. Sequences were de-multiplexed and aligned to the GRCh38 reference genome. Gene count tables were generated with CellRanger (droplet samples), or STAR and HTSEQ (plate samples). Cells with low UMI counts and low gene counts were removed. Droplet cells were filtered to remove barcode-hopping events and filtered for ambient RNA using DecontX. Sequencing batches were harmonized using scVI and projected to 2-D space with UMAP for analysis by the tissue experts. Expert annotation was made through the cellxgene browser and regularized with a public cell ontology. Annotation was manually QC checked and cross-validated with PopV, an annotation tool, which employs seven different automated annotation methods.
For complete methods, see supplementary materials (12).
Data and materials availability
The entire dataset can be explored interactively at http://tabula-sapiens-portal.ds.czbiohub.org/. The code used for the analysis is available from GitHub at https://github.com/czbiohub/tabula-sapiens. Gene counts and metadata are available from figshare (https://doi.org/10.6084/m9.figshare.14267219) and have been deposited in the Gene Expression Omnibus (GSE149590); the raw data files are available from a public AWS S3 bucket (https://registry.opendata.aws/tabula-sapiens/) and instructions on how to access the data have been provided in the project GitHub. The histology images are available from figshare (https://doi.org/10.6084/m9.figshare.14962947). SpliZ scores are available from figshare (https://doi.org/10.6084/m9.figshare.14977281).
The Tabula Sapiens Consortium Author List
Overall Project Direction and Coordination
Robert C. Jones1, Jim Karkanias2, Mark Krasnow3,4, Angela Oliveira Pisco2, Stephen R. Quake1,2,5, Julia Salzman3,6, Nir Yosef2,7,8,9
Donor Recruitment
Bryan Bulthaup10, Phillip Brown10, William Harper10, Marisa Hemenez10, Ravikumar Ponnusamy10, Ahmad Salehi10, Bhavani A. Sanagavarapu10, Eileen Spallino10
Surgeons
Ksenia A. Aaron11, Waldo Concepcion10, James M. Gardner12,13, Burnett Kelly10,14, Nikole Neidlinger10, Zifa Wang10
Logistical coordination
Sheela Crasta1,2, Saroja Kolluru1,2, Maurizio Morri2, Angela Oliveira Pisco2, Serena Y. Tan15, Kyle J. Travaglini3, Chenling Xu7
Organ Processing
Marcela Alcántara-Hernández16, Nicole Almanzar17, Jane Antony18, Benjamin Beyersdorf19, Deviana Burhan20, Kruti Calcuttawala21, Matthew M. Carter16, Charles K. F. Chan18,22, Charles A. Chang23, Stephen Chang3,19, Alex Colville21,24, Sheela Crasta1,2, Rebecca N. Culver25, Ivana Cvijović1,5, Gaetano D’Amato26, Camille Ezran3, Francisco X. Galdos18, Astrid Gillich3, William R. Goodyer27, Yan Hang23,28, Alyssa Hayashi1, Sahar Houshdaran29, Xianxi Huang19,30, Juan C. Irwin29, SoRi Jang3, Julia Vallve Juanico29, Aaron M. Kershner18, Soochi Kim21,24, Bernhard Kiss18, Saroja Kolluru1,2, William Kong18, Maya E. Kumar17, Angera H. Kuo18, Rebecca Leylek16, Baoxiang Li31, Gabriel B. Loeb32, Wan-Jin Lu18, Sruthi Mantri33, Maxim Markovic1, Patrick L. McAlpine11,34, Antoine de Morree21,24, Maurizio Morri2, Karim Mrouj18, Shravani Mukherjee31, Tyler Muser17, Patrick Neuhöfer3,35,36, Thi D. Nguyen37, Kimberly Perez16, Ragini Phansalkar26, Angela Oliveira Pisco2, Nazan Puluca18 , Zhen Qi18, Poorvi Rao20, Hayley Raquer-McKay16, Nicholas Schaum18,21, Bronwyn Scott31, Bobak Seddighzadeh38, Joe Segal20, Sushmita Sen29, Shaheen Sikandar18, Sean P. Spencer16, Lea Steffes17, Varun R. Subramaniam31, Aditi Swarup31, Michael Swift1, Kyle J. Travaglini3, Will Van Treuren16, Emily Trimm26, Stefan Veizades19,39, Sivakamasundari Vijayakumar18, Kim Chi Vo29, Sevahn K. Vorperian1,40, Wanxin Wang29, Hannah N.W. Weinstein38, Juliane Winkler41, Timothy T.H. Wu3, Jamie Xie38, Andrea R.Yung3, Yue Zhang3
Sequencing
Angela M. Detweiler2, Honey Mekonen2, Norma F. Neff2, Rene V. Sit2, Michelle Tan2, Jia Yan2
Histology
Gregory R. Bean15, Vivek Charu15, Erna Forgó15, Brock A. Martin15, Michael G. Ozawa15, Oscar Silva15, Serena Y. Tan15, Angus Toland15, Venkata N.P. Vemuri2
Data Analysis
Shaked Afik7, Kyle Awayan2, Rob Bierman3,6, Olga Borisovna Botvinnik2, Ashley Byrne2, Michelle Chen1, Roozbeh Dehghannasiri3,6, Angela M. Detweiler2, Adam Gayoso7, Alejandro A Granados2, Qiqing Li2, Gita Mahmoudabadi1, Aaron McGeever2, Antoine de Morree21,24, Julia Eve Olivieri3,6,42, Madeline Park2, Angela Oliveira Pisco2, Neha Ravikumar1, Julia Salzman3,6, Geoff Stanley1, Michael Swift1, Michelle Tan2, Weilun Tan2, Alexander J Tarashansky2, Rohan Vanheusden2, Sevahn K. Vorperian1,40, Peter Wang3,6, Sheng Wang2, Galen Xing2, Chenling Xu6, Nir Yosef2,6,7,8
Expert Cell Type Annotation
Marcela Alcántara-Hernández16, Jane Antony18, Charles K. F. Chan18,22, Charles A. Chang23, Alex Colville21,24, Sheela Crasta1,2, Rebecca Culver25, Les Dethlefsen43, Camille Ezran3, Astrid Gillich3, Yan Hang23,28, Po-Yi Ho16, Juan C. Irwin29, SoRi Jang3, Aaron M. Kershner18, William Kong18, Maya E Kumar17, Angera H. Kuo18, Rebecca Leylek16, Shixuan Liu3,44, Gabriel B. Loeb32, Wan-Jin Lu18, Jonathan S Maltzman45,46, Ross J. Metzger27,47, Antoine de Morree21,24, Patrick Neuhöfer3,35,36, Kimberly Perez16, Ragini Phansalkar26, Zhen Qi18, Poorvi Rao20, Hayley Raquer-McKay16, Koki Sasagawa19, Bronwyn Scott31, Rahul Sinha15,18,35, Hanbing Song38, Sean P. Spencer16, Aditi Swarup31, Michael Swift1, Kyle J. Travaglini3, Emily Trimm26, Stefan Veizades19,39, Sivakamasundari Vijayakumar18, Bruce Wang20, Wanxin Wang29, Juliane Winkler41, Jamie Xie38, Andrea R.Yung3
Tissue Expert Principal Investigators
Steven E. Artandi3,35,36, Philip A. Beachy18,23,48, Michael F. Clarke18, Linda C. Giudice29, Franklin W. Huang38,49, Kerwyn Casey Huang1,16, Juliana Idoyaga16, Seung K Kim23,28, Mark Krasnow3,4, Christin S. Kuo17, Patricia Nguyen19,39,46, Stephen R. Quake1,2,5, Thomas A. Rando21,24, Kristy Red-Horse26, Jeremy Reiter50, David A. Relman16,43,46, Justin L. Sonnenburg16, Bruce Wang20, Albert Wu31, Sean M. Wu19,39, Tony Wyss-Coray21,24
Affiliations
1Department of Bioengineering, Stanford University; Stanford, CA, USA.
2Chan Zuckerberg Biohub; San Francisco, CA, USA.
3Department of Biochemistry, Stanford University School of Medicine; Stanford, CA, USA.
4Howard Hughes Medical Institute; USA.
5Department of Applied Physics, Stanford University; Stanford, CA, USA.
6Department of Biomedical Data Science, Stanford University; Stanford, CA, USA.
7Center for Computational Biology, University of California Berkeley; Berkeley, CA, USA.
8Department of Electrical Engineering and Computer Sciences, University of California Berkeley; Berkeley, CA, USA.
9Ragon Institute of MGH, MIT and Harvard; Cambridge, MA, USA.
10Donor Network West; San Ramon, CA, USA.
11Department of Otolaryngology-Head and Neck Surgery, Stanford University School of Medicine; Stanford, California, USA.
12Department of Surgery, University of California San Francisco; San Francisco, CA, USA.
13Diabetes Center, University of California San Francisco; San Francisco, CA, USA.
14DCI Donor Services; Sacramento, CA, USA.
15Department of Pathology, Stanford University School of Medicine; Stanford, CA, USA.
16Department of Microbiology and Immunology, Stanford University School of Medicine; Stanford, CA, USA.
17Department of Pediatrics, Division of Pulmonary Medicine, Stanford University; Stanford, CA, USA.
18Institute for Stem Cell Biology and Regenerative Medicine, Stanford University School of Medicine; Stanford, CA, USA.
19Department of Medicine, Division of Cardiovascular Medicine, Stanford University; Stanford, CA, USA.
20Department of Medicine and Liver Center, University of California San Francisco; San Francisco, CA, USA.
21Department of Neurology and Neurological Sciences, Stanford University School of Medicine; Stanford, CA, USA.
22Department of Surgery - Plastic and Reconstructive Surgery, Stanford University School of Medicine; Stanford, CA, USA.
23Department of Developmental Biology, Stanford University School of Medicine, Stanford, CA, USA
24Paul F. Glenn Center for the Biology of Aging, Stanford University School of Medicine; Stanford, CA, USA.
25Department of Genetics, Stanford University School of Medicine; Stanford, CA, USA.
26Department of Biology, Stanford University; Stanford, CA, USA.
27Department of Pediatrics, Division of Cardiology, Stanford University School of Medicine; Stanford, CA, USA.
28Stanford Diabetes Research Center, Stanford University School of Medicine, Stanford, California
29Center for Gynecology and Reproductive Sciences, Department of Obstetrics, Gynecology and Reproductive Sciences, University of California San Francisco; San Francisco, CA, USA.
30Department of Critical Care Medicine, The First Affiliated Hospital of Shantou University Medical College; Shantou, China.
31Department of Ophthalmology, Stanford University School of Medicine; Stanford, CA, USA.
32Division of Nephrology, Department of Medicine, University of California San Francisco; San Francisco, CA, USA.
33Stanford University School of Medicine; Stanford, CA, USA.
34Mass Spectrometry Platform, Chan Zuckerberg Biohub; Stanford, CA, USA.
35Stanford Cancer Institute, Stanford University School of Medicine; Stanford, CA, USA. 36Department of Medicine, Division of Hematology, Stanford University School of Medicine, Stanford, CA, USA
37Department of Biochemistry and Biophysics, Cardiovascular Research Institute, University of California San Francisco; San Francisco, CA, USA.
38Division of Hematology and Oncology, Department of Medicine, Bakar Computational Health Sciences Institute, Institute for Human Genetics, University of California San Francisco; San Francisco, CA, USA.
39Stanford Cardiovascular Institute; Stanford CA, USA.
40Department of Chemical Engineering, Stanford University; Stanford, CA, USA.
41Department of Cell & Tissue Biology, University of California San Francisco; San Francisco, CA, USA.
42Institute for Computational and Mathematical Engineering, Stanford University; Stanford, CA, USA.
43Division of Infectious Diseases & Geographic Medicine, Department of Medicine, Stanford University School of Medicine; Stanford, CA, USA.
44Department of Chemical and Systems Biology, Stanford University School of Medicine, Stanford, CA, USA
45Division of Nephrology, Stanford University School of Medicine; Stanford, CA, USA.
46Veterans Affairs Palo Alto Health Care System; Palo Alto, CA, USA.
47Vera Moulton Wall Center for Pulmonary and Vascular Disease, Stanford University School of Medicine; Stanford, CA, USA.
48Department of Urology, Stanford University School of Medicine, Stanford, CA, USA
49Division of Hematology/Oncology, Department of Medicine, San Francisco Veterans Affairs Health Care System, San Francisco, CA, USA.
50Department of Biochemistry, University of California San Francisco; San Francisco, CA, USA.
Supplementary Material
Materials and Methods
Tables S1 to S9
References (51-84)
Resources
Data portal for Tabula Sapiens (18)
Acknowledgements
We express our gratitude and thanks to donor WEM and his family, as well as to all of the anonymous organ and tissue donors and their families for giving both the gift of life and the gift of knowledge by their generous donations. We also thank Donor Network West for their cooperation in this project, S. Schmid for a close reading of the manuscript, and B. Tojo for the original artwork in Figure 1. This project has been made possible in part by grant number 2019-203354 from the Chan Zuckerberg Initiative DAF, an advised fund of Silicon Valley Community Foundation, and by support from the Chan Zuckerberg Biohub. The data portal for this publication is available at (18).
References:




