

Abstract
Non-coding RNAs (ncRNA), a significant part of the increasingly popular ‘dark matter’ of the human genome1, have gained substantial attention due to their involvement in animal development and human disorders such as cardiovascular diseases and cancer2. Although many different types of regulatory ncRNAs have been discovered over the last 25 years, microRNAs (miRNAs) are unique within these as they are the only class of ncRNAs with individual genes sequentially conserved across the animal kingdom3. Because of the conserved roles miRNAs play in establishing robustness of gene regulatory networks across Metazoa4, it is important that homologous miRNAs in different species are correctly identified, annotated, and named using consistent criteria5 against the backdrop of numerous other types of coding and non-coding RNA fragments6.
Unlike miRBase7, which has developed organically through community-wide submissions, and thus does not use consistent annotation or nomenclature criteria6, MirGeneDB2.0 (http://mirgenedb.org), a manually curated open source miRNA gene database, contains high quality annotations of 7,785 bona fide and consistently named miRNAs from 32 species representing major metazoan groups (including many invertebrate and vertebrate model organisms). The number of miRNAs conforming to the annotation criteria is almost four times higher than in miRBase (~2000 for the miRBase ‘high confidence’ set7), and can be considered free of false positives. For the expansion of the previous version, we used more than 250 publicly available sequencing datasets (for a total of 4.2 billion reads) derived from at least one representative dataset for each organism (such as whole organisms, organs, tissues or cell-types), which allowed for a consistent and uniform annotation of microRNAomes for each species (Supplementary File, “file_info”; Supplementary Methods)8. Existing MirGeneDB.org miRNA complements for human, mouse, chicken and zebrafish were expanded from our initial effort by 65, 49, 28 and 100 genes, respectively (Supplementary File, table), and annotation-accuracy was further improved using available Cap Analysis of Gene Expression (CAGE) data when available (Supplementary File, “CAGE”)9.
Because miRBase has become increasingly heterogeneous with respect to the number of bona fide miRNAs relative to other types of non-coding RNAs, it has considerable variation in the number of miRNAs for closely related groups (Supplementary File, graph miRBase). However, in MirGeneDB, congruent miRNA complements in terms of total miRNA genes and miRNA families were observed in related groups, such as the Vertebrates and arthropods3,10 (Figure 1). Big differences between miRBase and MirGeneDB2.0 can be observed because miRBase has on the one hand a much larger number of annotated sequences for some of the 23 taxa shared with MirGeneDB2.0 including human, mouse, and chicken, accounting for 4,243 false positives, and on the other hand it lacks 22% of all MirGeneDB2.0 genes, accounting for 1,180 false negatives (Figure 2, Supplementary File, “overview”). Finally, 31% of the remaining 4,275 miRNAs are incompletely annotated in miRBase, whereas in MirGeneDB2.0 each miRNA has both arms annotated, with a clear distinction made between sequenced reads and predicted reads for each miRNA entry with predictions derived from both considerations of secondary structure and expressed orthologues in other taxa.
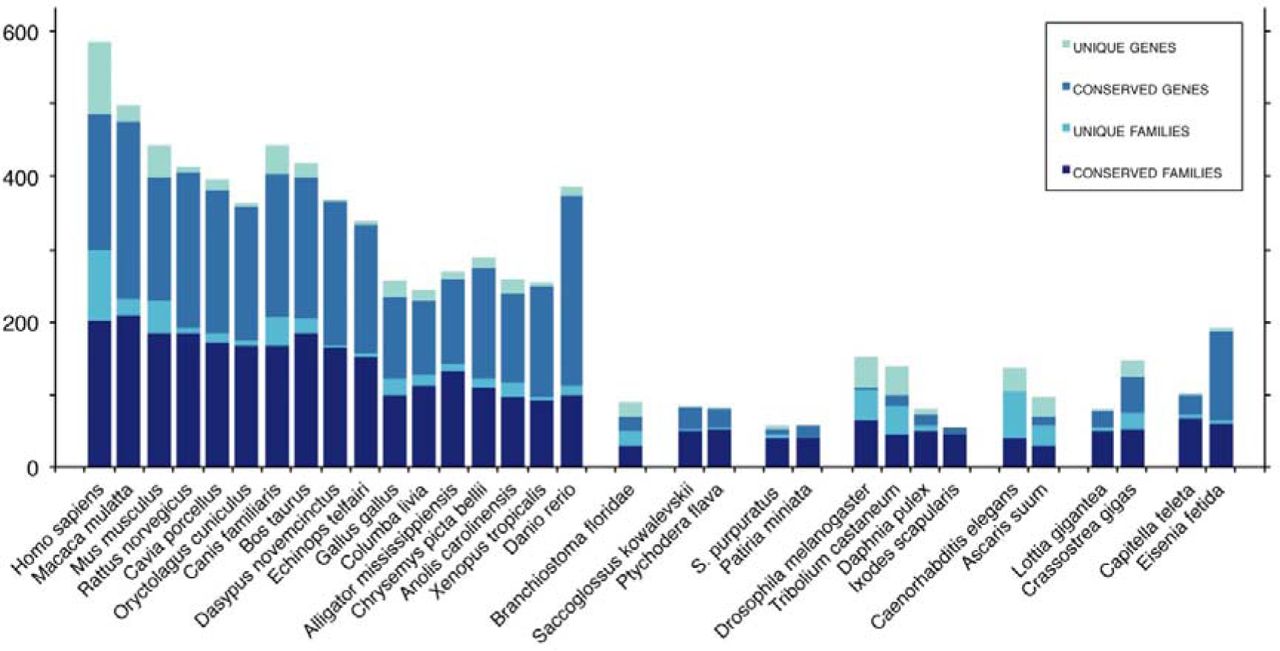
High consistency of conserved miRNA gene and family numbers in closely related groups in MirGeneDB2.0 can be observed for groups with more than two representatives. High variation in gene-numbers for Danio and Eisenia (double asterisks) are explainable by genome-duplication events within that particular monophyletic group (vertebrates and annelids, respectively), while high numbers of unique /novel genes and families in Homo, Mus, Canis, Drosophila, Tribolium and Caenorhabditis might be explainable by the significantly higher number of studies and/or the relatively higher number of absolute small RNA reads on these organisms (single asterisks).

High number of incorrect and missing miRNA annotations in miRBase as compared to MirGeneDB. A comparison of the microRNA complements of 23 organisms shared between miRBase and MirGeneDB revealed that only 4,275 of the 8,531 entries in miRBase are shared with MirGeneDB (green). An additional 4,243 miRBase entries represent false positives (red), miRNAs found in miRBase that do not satisfy standard annotation criteria, whereas 1,180 MirGeneDB entries represent false negatives (blue), miRNAs that are present in these taxa that are not currently annotated in miRBase.
The expanded web-interface of MirGeneDB2.0 allows browsing, searching and downloading of miRNA-complements for each organism. Annotations are downloadable as fasta, gff, or bed-files containing distinct sub-annotations for all miRNA components such as precursor (pre), mature, loop, co-mature or star sequences. Unlike miRBase, seed sequences are also identified, and can be searched independently from the rest of the mature sequence. In addition, we included 30-nucleotide flanking regions on both arms for each precursor transcript to generate an extended precursor transcript, which again is downloadable.
MirGeneDB2.0 employs an internally consistent nomenclature system where genes of common descent are assigned the same miRNA family name, allowing for the easy recognition of both orthologues in other species, and paralogues within the same species. This nomenclature system allows for an accurate reconstruction of ancestral miRNA repertoires – both at the family level and at the gene level – that is now provided in MirGeneDB2.0 for all nodes leading to the 32 terminal taxa considered, which allows users to easily assess both gains and losses of miRNA genes through time. However, in order to not increase confusion about the naming of miRNA genes, we continue to provide commonly used miRBase names – if available – in our “Browse” section of MirGeneDB2.0 (i.e. http://mirgenedb.org/browse/hsa).
Gene-pages for each miRNA gene contain names, orthologues & paralogues, downloadable sequences, structure, and a range of other previously available information including genomic coordinates (i.e. http://mirgenedb.org/show/hsa/Let-7-P1). New features in MirGeneDB2.0 include accurate information on 3’ non-templated uridylations, which characterize an important sub-group of miRNAs; information of the presence or absence of the recently discovered sequential motifs (UG, UGUG, CNNC); and the visualization of at least one expression dataset for each gene in each organism. Further, read-pages are also provided for each gene (i.e. http://mirgenedb.org/static/graph/hsa/results/Hsa-Let-7-P1.html), which show an overview of read-stacks on the corresponding extended precursor sequence of each gene-page. They contain detailed representation of templated and non-templated reads for individual datasets for each gene including reports on miRNA isoforms and downloadable read-mappings.
The establishment of this carefully curated data base of miRNA genes, supplementing existing databases including miRBase, allows for a stable and robust foundation for miRNA studies, in particular studies that rely on cross-species comparisons to explore the roles miRNAs play in development and disease, as well as the evolution of miRNAs (and animals) themselves.
Note: Supplementary Methods and Supplementary files are available in the online version of the paper.
Author contributions
BF and KJP conceived MirGeneDB2.0, compiled miRNA complements for all organisms. DD created read-pages and heatmaps. MJ set up the framework and database. MH processed sRNA sequencing data, AM processed and analyzed CAGE data. EHøye created scripts for mature/star annotation. EHovig and KF provided infrastructure and all authors read and commented on the manuscript.
Competing financial interests
The authors declare no competing financial interests.

The distribution of CAGE tags around the 3’ end of pre-miRNAs annotated in MirGeneDB for a) human and b) zebrafish shows a clear peak for CAGE tags 1 nt downstream (i.e. the +1 nt) of the pre-miRNA 3’ ends as described before26,27.
Acknowledgments
We thank Victor Ambros, David Bartel, Marc Friedländer, Marc Halushka, Andreas Keller, Gianvito Urgese for discussions, Georgios Magklaras for IT support. B.F. has been supported by the South-Eastern Norway Regional Health Authority (Grant No. 2014041). AM has been supported by the Norwegian Research Council, Helse Sør-Øst, and the University of Oslo through the Centre for Molecular Medicine Norway (NCMM), which is part of the Nordic European Molecular Biology Laboratory partnership for Molecular Medicine. K.J.P. was supported by NASA-Ames.
Footnotes
e-mail: BastianFromm{at}gmail.com or Kevin.J.Peterson{at}dartmouth.edu





{kind=link}
{kind=link}
{kind=link}