

Abstract
Complexity of life forms on Earth has increased tremendously, primarily driven by subsequent evolutionary transitions in individuality, a mechanism in which units formerly being capable of independent replication combine to form higher-level evolutionary units. Although this process has been likened to the recursive combination of pre-adapted subsolutions in the framework of learning theory, no general mathematical formalization of this analogy has been provided yet. Here we show, building on former results connecting replicator dynamics and Bayesian update, that (i) evolution of a hierarchical population under multilevel selection is equivalent to Bayesian inference in hierarchical Bayesian models, and (ii) evolutionary transitions in individuality, driven by synergistic fitness interactions, is equivalent to learning the structure of hierarchical models via Bayesian model comparison. These correspondences support a learning theory oriented narrative of evolutionary complexification: the complexity and depth of the hierarchical structure of individuality mirrors the amount and complexity of data that has been integrated about the environment through the course of evolutionary history.
1 Introduction
On Earth, life has undergone immense complexification [1, 2]. The evolutionary path from the first self-replicating molecules to structured societies of multicellular organisms has been paved with exceptional milestones: units that were capable of independent replication have combined to form a higher-level unit of replication [3, 4, 5]. Such evolutionary transitions in individuality opened the door to the vast increase of complexity via hierarchical aggregation of pre-adapted subunits. Paradigmatic examples include the transition of replicating molecules to protocells, the endosymbiosis of mitochondria and plastids by eucaryotic cells and the appearance of multicellular organisms and eusociality. Interestingly, it is possible to identify common evolutionary mechanisms that possibly led to these unique but analogous events [6, 7, 8, 9]. A crucial preliminary condition is the alignment of interests: in order to undergo an evolutionary transition in individuality, organisms must exhibit extreme form of cooperation, originating from genetic relatedness and/or synergistic fitness interactions [4]. However, the story does not end here: something must maintain the alignment of interests subsequent to the transition, too. At that point, the fate of the organism depends on selective forces at multiple levels that might be in conflict with each other. Incorporating the effects of multilevel selection is, therefore, a crucial element of understanding evolutionary transitions in individuality [10].
These theoretical considerations above delineate conditions under which a transition might occur and a possibly different set of conditions which help to maintain the integrity of units that have already undergone transition. However, these considerations alone cannot offer a predictive theory of complexification as they do not address the question of how necessary these environmental and ecological conditions are. An alternative, supplementary approach that circumvents these difficulties is to investigate whether mathematical theories of adaptation and learning can provide further insights about the general scheme of evolutionary transitions in individuality. In this paper, we argue that they do. We first provide a mapping between multilevel selection modeled by discrete-time replicator dynamics and Bayesian inference in belief networks (i.e., directed graphical models), which shows that the underlying mathematical structures are isomorphic. The two key ingredients are (i) the already known equivalence between univariate Bayesian update and single-level replicator dynamics [11, 12] and (ii) a possible correspondence between properties of a hierarchical population composition and multivariate probability theory. We then show that this isomorphism allows for a natural interpretation of evolutionary transitions in individuality as learning the structure [13, 14] of the belief network. Indeed, following adaptive paths on the fitness landscape over possible hierarchical population compositions is equivalent to a well-known method used for selecting the optimal model structure in the Bayesian paradigm, namely, Bayesian model comparison. This suggests that complexification of life via successive evolutionary transitions in individuality is analogous to the complexification of optimal model structure as more (or more complex) data about the environment is available.
Relating the dynamics of evolutionary complexification to hierarchical probabilis tic generative models complements recent efforts of searching for algorithmic analogies between emergent evolutionary phenomena and neural network based learning models [15, 16]. These include correspondences between evolutionary-ecological dynamics and autoassociative networks [17] and also linking the evolution of developmental organization to learning in artificial neural networks [18]. As such connectionist models account for how global self-organizing learning behavior might emerge from simple local rules (e.g., weight updates), our approach aims at providing a common global framework for modeling both evolutionary and learning dynamics.
In the following, we provide a brief introduction to the elementary building blocks of our arguments: Bayesian update and replicator dynamics. Bayesian update [19] fits a probability distribution P(I) of hypotheses I = I1,…,Im to the data e. It does so by integrating prior knowledge about the probability P(Ii) of hypothesis Ii with the likelihood that the actual data e = e(t) is being generated by hypothesis Ii, given by P(e(t)|Ii). Mathematically, the fitted distribution P(Ii|e(t)), called the posterior, is simply proportional to both the prior P(Ii) and the likelihood P(e(t)|Ii):

On the other hand, the discrete replicator equation [20] that accounts for the change in relative abundance f (Ii) of types of replicating individuals Ii in the population driven by their fitness values w(li), reads as

As first noted by Harper [11] and Shalizi [12], equations (1) and (2) are equivalent, with the following identified quantities. The relative abundance f (Ii; t) of type Ii at time t corresponds to the prior probability P(Ii); the relative abundance f (Ii; t + 1) at time t +1 is corresponding to the posterior probability P(Ii|e(t)); the fitness w(Ii; t) of type Ii at time t is corresponding to the likelihood P(e(t)|Ii); and the average fitness Σi w(Ii; t) f (Ii; t) is corresponding to the normalizing factor Σi P(e(t)|Ii)P(Ii) called the model evidence.
Building on this observation, a natural question to ask is if this mathematical equivalence is only an apparent similarity due to the simplicity of both models, or it is a consequence of a deeper structural analogy between evolutionary and learning dynamics. We propose two conceptually new avenues along which this equivalence can be generalized. First, we identify concepts of hierarchical evolutionary processes with concepts of (i) multivariate probability theory, (ii) Bayesian inference in hierarchical models and (iii) conditional independence relations between variables in such models. Building on this theoretical bridge, we then investigate the dynamics of learning the structure (as opposed to parameter fitting in a fixed model) of hierarchical Bayesian models and the Darwinian evolution of multilevel populations, concluding that following adaptive evolutionary paths on the landscape of hierarchical populations naturally maps to optimizing the structure of hierarchical Bayesian models via Bayesian model comparison.
2 Results
In order to generalize the algebraic equivalence between discrete-time replicator dynamics and Bayesian update (1) to multilevel selection scenarios, multivariate distributions have to be involved. In general, a multivariate distribution P(x1,…, xk) over k variables, each taking m possible values, can be encoded by mk — 1 independent parameters, which is exponential in the number of variables. Apart from practical considerations such as the possible infeasibility of computing marginal and conditional distributions, sampling and storing such general distributions, a crucial theoretical limitation is that fitting data by a model with such a sizable parameter space would result in overfitting, unless the training dataset is itself comparably large [21].
A way to overcome such obstacles is to explicitly abandon indirect dependencies between variables by using structured probabilistic models, such as belief networks (called also Bayesian networks or directed graphical models) [22, 23]. Indeed, belief networks simplify joint distribution over multiple variables by specifying conditional independence relations corresponding to indirect (as opposed to direct) dependencies between variables.
In the following, we build up an algebraic isomorphism between discrete-time multilevel replicator dynamics and iterated Bayesian inference in belief networks on a step-by-step basis. The key identified quantities are summarized in Table 1.
Composition: mapping properties of multilevel populations to multivariate probability theory. A multilevel population is regarded as a hierarchical containment structure of types: Individual types Ii might be part of collectives  which themselves might be part of higher-level collectives
which themselves might be part of higher-level collectives  , and so on, as illustrated in Figure 1. Note that collectives at any level might possess heritable information (henceforth referred to as their identity); collectives of the same (hierarchical) composition might very well have different identities. This makes this framework flexible enough to incorporate qualitatively different stages of evolutionary interdependence between organisms, leading eventually to a transition in individuality: (i) selection in which individuals enjoy the synergistic effect of belonging to a collective, but the collectives themselves do not possess any heritable information; (ii) selection in which collectives possess their own heritable information but also the individuals in them might replicate at different rates; (iii) and selection in which individuals have already lost their ability to replicate independently, therefore, their fitness is totally determined by the collective they belong to. As Michod and Nedelcu write on p. 61 of Ref. [24], “group fitness is, initially, taken to be the average of the lower-level individual fitnesses; but as the evolutionary transition proceeds, group fitness becomes decoupled from the fitness of its lower-level components”. This, as we shall see, is exactly what our model accounts for mathematically, incorporating also the effect of stochastically varying environment.
, and so on, as illustrated in Figure 1. Note that collectives at any level might possess heritable information (henceforth referred to as their identity); collectives of the same (hierarchical) composition might very well have different identities. This makes this framework flexible enough to incorporate qualitatively different stages of evolutionary interdependence between organisms, leading eventually to a transition in individuality: (i) selection in which individuals enjoy the synergistic effect of belonging to a collective, but the collectives themselves do not possess any heritable information; (ii) selection in which collectives possess their own heritable information but also the individuals in them might replicate at different rates; (iii) and selection in which individuals have already lost their ability to replicate independently, therefore, their fitness is totally determined by the collective they belong to. As Michod and Nedelcu write on p. 61 of Ref. [24], “group fitness is, initially, taken to be the average of the lower-level individual fitnesses; but as the evolutionary transition proceeds, group fitness becomes decoupled from the fitness of its lower-level components”. This, as we shall see, is exactly what our model accounts for mathematically, incorporating also the effect of stochastically varying environment.
A key assumption that enables the machinery of multivariate probability theory to work is that abundance of collectives is measured in terms of abundance of individuals they contain. Indeed, by identifying the abundance of individuals of type Ii,  , that are part of collectives of type
, that are part of collectives of type  that are themselves part of collectives of type
that are themselves part of collectives of type  , etc., with the joint probabilities
, etc., with the joint probabilities  , two important additional identification follows:
, two important additional identification follows:
marginal distributions, such as
 translate to the abundance distribution of types at the corresponding level (here, C1), (any I in in any C2 in …)
translate to the abundance distribution of types at the corresponding level (here, C1), (any I in in any C2 in …)conditional distributions, e.g.,
translate either to composition of collectives or membership distribution of individuals (or lower level collectives), (Ii in any C1).






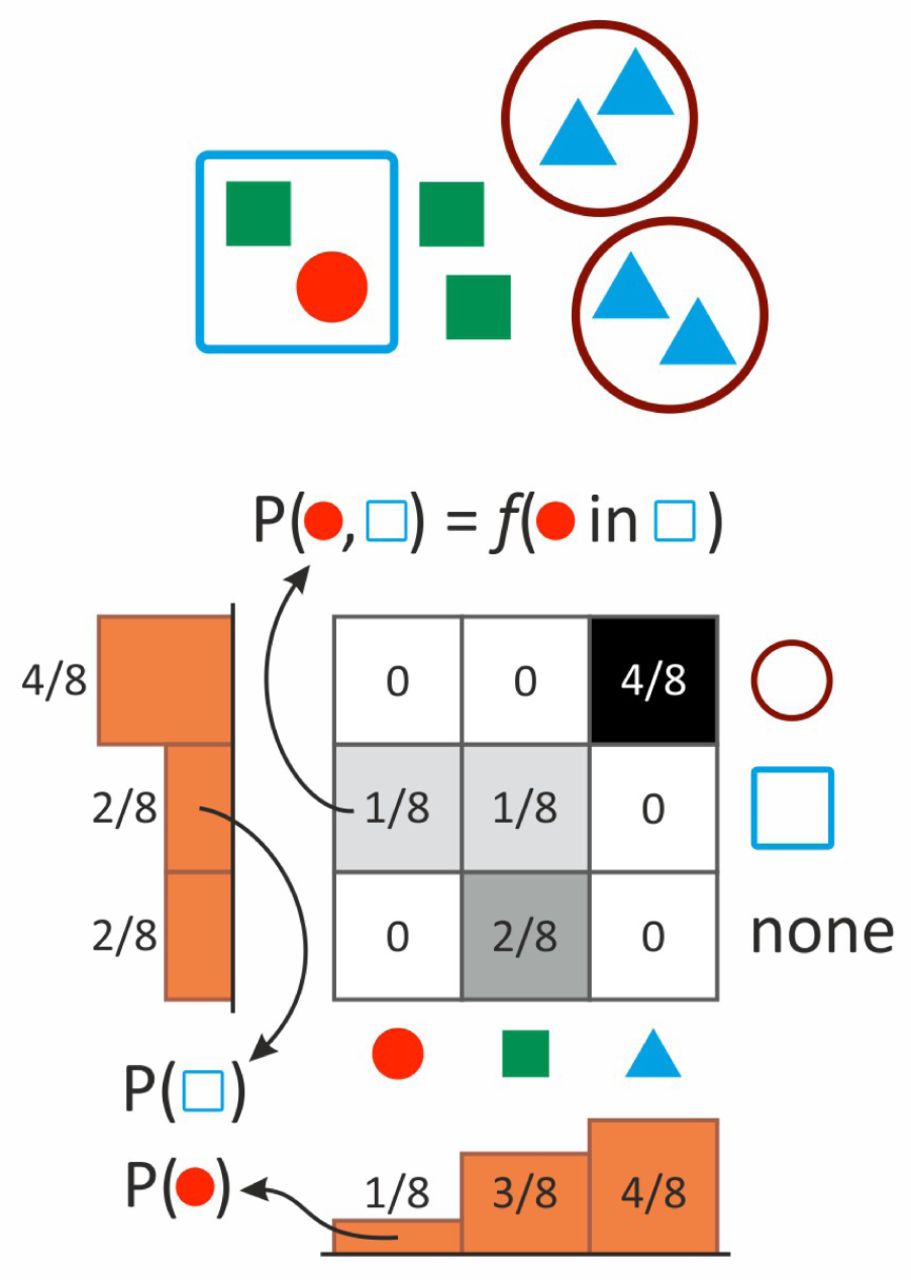
These computations are illustrated by a toy example in Figure 2.

Evolution of multilevel population as inference in Bayesian belief network. The stochastic environment e governs the evolutionary dynamics of multilevel population composition  . This is, in turn, equivalent to successive Bayesian inference of hidden variables I, C1 and C2 based on the observation of current the environmental parameters e. Since these environmental parameters are sampled and observed multiple times (i.e., at every timestep t = 1, 2, 3 …), the corresponding node of the belief network is conventionally placed on a plate. Also note that the deletion of links between nodes of the belief network is corresponding to conditional independence relations between variables in the Bayesian setting and to specific structural properties of selection and population composition in the evolutionary setting; see text for details.
. This is, in turn, equivalent to successive Bayesian inference of hidden variables I, C1 and C2 based on the observation of current the environmental parameters e. Since these environmental parameters are sampled and observed multiple times (i.e., at every timestep t = 1, 2, 3 …), the corresponding node of the belief network is conventionally placed on a plate. Also note that the deletion of links between nodes of the belief network is corresponding to conditional independence relations between variables in the Bayesian setting and to specific structural properties of selection and population composition in the evolutionary setting; see text for details.

Two-level population encoded as a bivariate probability distribution. Joint probabilities represent the relative abundance of different individuals in different collectives. Conditional distributions depict the composition of collectives (rows) or the membership distribution of individuals (columns). Marginals, illustrated by the onedimensional histograms, represent the abundance distribution of types at the individual level (horizontal) or at the level of collectives (vertical histogram).
Identified quantities of evolution and learning
Dynamics: multilevel replicator dynamics as inference in Bayesian belief networks. Just like in the single-level case, the environmental parameters e(t), t = 1, 2, 3,… are assumed to be sampled from an unknown generative process; the successive observation of them drives the successive update of population composition. As discussed earlier, however, multilevel population structures can be mapped to multivariate probability distributions, forming multiple latent variables to be updated upon the observation of e.
Formally, just as prior probabilities over multiple hypotheses  are updated to posterior probabilities
are updated to posterior probabilities  based on the likelihood,
based on the likelihood,  , in the same way, multilevel population composition at time t,
, in the same way, multilevel population composition at time t,  is updated to the composition at t + 1 based on fitnesses
is updated to the composition at t + 1 based on fitnesses  . The critical conceptual identification here is therefore of (i) the likelihood of the hypothesis parametrized by
. The critical conceptual identification here is therefore of (i) the likelihood of the hypothesis parametrized by  and of (ii) the fitness of those individuals Ii that belong to those collectives
and of (ii) the fitness of those individuals Ii that belong to those collectives  that belong to
that belong to  , etc. The normalization factor that ensures that (i) the multivariate distribution is normalized (the model evidence
, etc. The normalization factor that ensures that (i) the multivariate distribution is normalized (the model evidence  or that (ii) abundances are always measured relative to the total abundance of individuals (the average fitness
or that (ii) abundances are always measured relative to the total abundance of individuals (the average fitness  , is conceptually irrelevant here as they do not change the ratio of probabilities or abundances. Their equivalence will, however, play a critical role in relating evolution of individuality and structure learning of belief networks.
, is conceptually irrelevant here as they do not change the ratio of probabilities or abundances. Their equivalence will, however, play a critical role in relating evolution of individuality and structure learning of belief networks.
In order to demonstrate how simple calculations are performed in this framework and also to elucidate how fitnesses are determined, here we calculate the fitness of collective  , which has been identified with
, which has been identified with  . Using simple relations of probability theory,
. Using simple relations of probability theory,  . Translating this back to the language of evolution tells us that the fitness of
. Translating this back to the language of evolution tells us that the fitness of  is simply the average fitness of individuals it contains, as anticipated earlier.
is simply the average fitness of individuals it contains, as anticipated earlier.
Structure: mapping structural properties of multilevel selection to the structure of Bayesian belief network. Structured probabilistic models are useful because they concisely summarize direct and indirect dependencies between multiple variables. Specifically, Bayesian belief networks depict multivariate distributions, such as P(e, I, C1, C2), as a directed network, with the variables corresponding to the nodes and conditioning one variable on another corresponds to a directed link between the two. Since P (e, I, C1,C2) can always be written as P (e|I, C1, C2) P (I |C1, C2) P (C1|C2) P (C2) in terms of conditional probabilities, the corresponding belief network is the one illustrated in Figure 1. The route to simplify the structure of the distribution and correspondingly, the structure (i.e., connectivity) of the belief network is through conditional independence relations. Conditional independence relations, such as
 correspond to the deletion of connections; (3), for example, corresponds to the deletion of the connection between variables e and I, shown in red in Figure 1, and it describes the conditional independence of the observed variable e and a latent variable, I. What does this independence relation mean in evolutionary terms? As it logically follows from the previous identifications, it specifies that the units at level I are frozen in an evolutionary sense: their fitness is completely determined by the collective they belong to. There is a second, qualitatively different type of conditional independence relations: those between two latent variables, corresponding to two levels of the population. For example, P (I |C1,C2) = P (I |C1), corresponding to the deletion of the blue link in Figure 1, is interpreted as the following: the composition of any collective at level C1 is independent of what higher-level collective (at level C2) it belongs to. Such simplifications in hierarchical population composition allows for the step-by-step modular combination of units to higher-level units, re-using existing sub-solutions over and over again.
correspond to the deletion of connections; (3), for example, corresponds to the deletion of the connection between variables e and I, shown in red in Figure 1, and it describes the conditional independence of the observed variable e and a latent variable, I. What does this independence relation mean in evolutionary terms? As it logically follows from the previous identifications, it specifies that the units at level I are frozen in an evolutionary sense: their fitness is completely determined by the collective they belong to. There is a second, qualitatively different type of conditional independence relations: those between two latent variables, corresponding to two levels of the population. For example, P (I |C1,C2) = P (I |C1), corresponding to the deletion of the blue link in Figure 1, is interpreted as the following: the composition of any collective at level C1 is independent of what higher-level collective (at level C2) it belongs to. Such simplifications in hierarchical population composition allows for the step-by-step modular combination of units to higher-level units, re-using existing sub-solutions over and over again.
Structural dynamics: evolutionary transitions in individuality as Bayesian structure learning. It has been shown above that Bayesian inference in belief networks can be interpreted as Darwinian evolutionary dynamics of multilevel populations, driven by the "observation" of the actual environment e(t). What fits the environment is the hierarchical distribution of individuals (i.e., lowest level replicators) to collectives. However, the number of levels and the existing types within each level, along with the assumptions of hierarchical containment dependencies (i.e., conditional independence relations) has to be a priori specified. In this sense, fitting the environment by such a pre-defined structure via successive Bayesian updates has limited adaptation abilities. In particular, it is unable to adjust the complexity of the model to be in accordance with that of the environment, an inevitable property to avoid under- or overfitting.
In order to enlarge the space of possible models and therefore fit the environment better, one might allow the model structure to adapt as well. More complex models, however, will always fit any data better, and accordingly, adapting the model structure naively might result in overfitting, i.e., the inability of the model to account for never-seen data, corresponding to possible future environments. Organisms with too complicated hierarchical containment structures (and other adaptive parameters that are not modeled explicitly here) would go extinct in any varying environment. In order to remedy this situation, one has to take into consideration not only how good the best parameter combination fits the data, but also how hard it is to find such a parameter-combination. A systematic way of doing so is known as Bayesian model comparison, a well-known method in machine learning and Bayesian modeling. Mathematically, Bayesian model comparison simply ranks models (here, belief networks) according to their average ability to fit the data, referred to as the evidence E(M) of model M:

The first term in the sum describes the likelihood of the current parameters (i.e., their ability to fit the data), whereas the second term weights these likelihoods according to the prior probabilities of the parameters.
How evolution, on the other hand, limits the number of to-be-fitted parameters in any organism to reinforce evolvability is an intriguing phenomenon. Here we show that in our minimal framework, selection naturally accounts for model complexity: model evidence corresponds to the average fitness w of individuals, determined by their hierarchical grouping to higher-level replicators. Indeed, interpreting 4 in evolutionary terms gives
 in which the first term in the sum corresponds to fitnesses of individuals according to what collectives they belong to, and the second terms weights these fitnesses according to the abundance of such hierarchical arrangements. It implies that not only the evolution of the composition of multilevel population, but also the evolution of the structure of the multilevel population can be interpreted both in Darwinian and Bayesian terms: adaptive trajectories in the fitness landscape over population structures translate to adaptive trajectories of model evidence over belief networks. Note that the word structure here is borrowed from learning theory for consistency and it does not refer to structured populations in population ecology.
in which the first term in the sum corresponds to fitnesses of individuals according to what collectives they belong to, and the second terms weights these fitnesses according to the abundance of such hierarchical arrangements. It implies that not only the evolution of the composition of multilevel population, but also the evolution of the structure of the multilevel population can be interpreted both in Darwinian and Bayesian terms: adaptive trajectories in the fitness landscape over population structures translate to adaptive trajectories of model evidence over belief networks. Note that the word structure here is borrowed from learning theory for consistency and it does not refer to structured populations in population ecology.
Let us now turn specifically to the Bayesian interpretation of the evolution of individuality. Transitions in individuality, an evolutionary process in which lower-level units that were previously capable of independent replication form a higher-level evolutionary unit, correspond to a specific type transitions in the Bayesian model structure: either a new node is added to the top of the network (in case there was no such population level at all earlier), or a new value is added to any of the existing variables (in case the new evolutionary unit is formed at an already existing level). In each case, most of the belief network, including its parameters, remains the same, except the part that is participating in the transition. This part, however, always involves only those values (corresponding to types) of those variables (corresponding to levels) that are participating in the transition. If average fitness of these types is larger by grouping them together, they undergo a transition in individuality. Although this is a general description of transitions disregarding many details, the correspondence with Bayesian model comparison is remarkable.
Having defined our model framework mathematically, we now review its relation to multilevel selection and transition theory in more detail. Multilevel selection is conceptually characterized into two types, dubbed multilevel selection 1 and 2, both assuming that collectives form in a population of replicators, which themselves affect selection of lower level units [25, 10, 6]. In case of multilevel selection 1 (MLS1), only temporary collectives form that periodically disappear to revert to an unstructured population of lower level units (transient compartmentation) [26, 27]. Multilevel selection 2 (MLS2) on the other hand involves collectives that last and reproduce indefinitely, hence being bona fide evolutionary units [28], see also [29]). Only if collectives are evolutionary units can they inherit information stably (i.e., being informational replicators, [30]), thus the step toward a major evolutionary transition is MLS2. Note, that MLS1 can be understood as kin selection for most of the cases (cf. [28]), and might not even be a necessary prerequisite for MLS2 to evolve. In general, compartmentalization itself (transient or not) is not a sufficient property for a system to be a true evolutionary unit (cf. [31, 32]).

Evolutionary transitions as Bayesian structure learning. Initially, a singlelevel population I fits the environment e via replicator dynamics, or equivalently, via successive Bayesian update. Then, a new collective (the square) emerges at a new level C1, represented as a new node in the Bayesian belief network. Then, another new collective emerges at level C1 (the circles), therefore, the variable C1 is renamed to C1 as its possible values now include the circle as well. Finally, new collectives emerge at an even higher level (the rectangle and the ellipse at level C2), and correspondingly, a new node is added to the network again. Note that the evolution of parameters (i.e., population composition in a fixed structure) is not illustrated here for simplicity.
Our framework allows for parameterization of collective fitnesses such that they only depend on the collective’s composition, therefore corresponding to multilevel selection 2. The model is capable of handling MLS1 if, at each timestep, individuals are randomly reassorted among higher level collectives; incorporating this in the presented framework here is left for future work. Here we focus on the step from MLS2 toward a major transition: when collectives evolve to inherit information above their own composition. In our model this corresponds to the case when a property of the collective appears, possibly assigning different identities to collectives having identical composition. Such an identity-providing piece of information is understood as an emergent property of the collective that does not depend on the composition of lower level particles. If this is granted, higher level units can evolve on their own, somewhat independent of their compositions. In biological context, any such property corresponds to epigenetically inherited information that is not coded by genes.
Let us conclude this section with some general remarks. First, in order to perform explicit calculations, the fitness of each type at each level, i.e.,  , has to be specified. A natural way to do so is to pre-define a family of basis functions (e.g., Gaussians) on the space of possible environments e, parametrized by a set of parameters (e.g., the mean and covariance of the Gaussian). Then, each type at each level is assigned one member of the family through its parameters. What determines the fitness of a given type at time t then is the value of the basis function assigned to that type at e(t). The advantage of such parametrization is threefold. First, it open the possibility of modeling inter-type (i.e., microevolutionary) adaptation by making the parameters adaptive. Second, genetic relatedness, a crucial determining factor of evolutionary transitions, can be incorporated by coupling the parameters of types that have the similar containment structure. Third, normalization of such basis functions over the space of possible environments provides a natural way of accounting for adaptive trade-offs (i.e., the inability of a single organism to adapt to multiple substantially different environments at the same time). Here we do not enter into further details; investigating the relation between basis function types, adaptation algorithms and generative models of the environment P(e) is the subject of future work.
, has to be specified. A natural way to do so is to pre-define a family of basis functions (e.g., Gaussians) on the space of possible environments e, parametrized by a set of parameters (e.g., the mean and covariance of the Gaussian). Then, each type at each level is assigned one member of the family through its parameters. What determines the fitness of a given type at time t then is the value of the basis function assigned to that type at e(t). The advantage of such parametrization is threefold. First, it open the possibility of modeling inter-type (i.e., microevolutionary) adaptation by making the parameters adaptive. Second, genetic relatedness, a crucial determining factor of evolutionary transitions, can be incorporated by coupling the parameters of types that have the similar containment structure. Third, normalization of such basis functions over the space of possible environments provides a natural way of accounting for adaptive trade-offs (i.e., the inability of a single organism to adapt to multiple substantially different environments at the same time). Here we do not enter into further details; investigating the relation between basis function types, adaptation algorithms and generative models of the environment P(e) is the subject of future work.
3 Discussion
In this paper we introduced a mapping between concepts of hierarchical Bayesian models and concepts of Darwinian evolution, providing a learning theory based interpretation of complexification of life through evolutionary transitions of individuality. The backbone of this interpretation is the fact that measuring the abundance and the composition of any type at any level can be naturally mapped to performing marginalization and computing conditional probabilities, respectively, of multivariate discrete probability distributions. Another key ingredient is that the stochastic environment determines the fitness of both individuals and collectives in a multilevel selection process. These two pillars are united by the already known algebraic equivalence between Bayesian update and discrete replicator dynamics. Accordingly, the learning theory narrative of multilevel selection is as follows: as the environment e is successively observed, the distribution over the latent variables I, C1, C2, …, corresponding to the hierarchical population composition, is successively updated according to Bayes’ rule.
Having identified this analogy, one might ask how the structure of the belief network (i.e., not just the parameters of a fixed network) itself evolves. In learning theory, different structures can be scored according to their model evidence, giving rise to Bayesian model comparison, which accounts not only for how good a given solution is, but also for how unlikely it is to find such a good solution in the parameter space. Consequently, this procedure optimizes the trade-off between complexity and goodness of fit, hence dubbed as automatic Occam’s razor. The evolution of belief network structure, in the context of Bayesian learning theory, is therefore driven by comparing model evidences of different structures. Interestingly, Bayesian model comparison fits neatly to our multilevel evolutionary dynamics interpretation: model evidence turns out to be equivalent to the average fitness of individuals, i.e., of the lowest level replicating units. This allows for a learning-theory based view of evolutionary transitions in individuality: units aggregate to form a higher-level replicating unit if their average fitness increases by doing so; this is mathematically equivalent to performing Bayesian model comparison between the different belief network structures.
This procedure of simultaneous data acquisition, fitting, and structure learning is far from unique to our proposed model framework; apart from its extensive use in machine learning algorithms, it is conjectured to govern classified-as-intelligent systems such as the conceptual development in children and also our collective understanding of the world in terms of scientific concepts, both relying on the extraordinary generalization abilities from sparse and noisy data [33, 34]. We argue, based on the mathematical equivalence presented in this paper, that in order to devise seemingly-engeneered complex organisms, evolution, on Earth or anywhere, utilized comparable hierarchical learning mechanisms as we humans do to make sense of the world around us.
Acknowledgements
The authors thank Ádám Radványi, András Szilágyi, András Hubai and Szabolcs Szá-madó for their insightful comments on the manuscript. This research was funded by the grant ’Theory and solutions in the light of evolution’ (GINOP-2.3.2-15-2016-00057).





{kind=link}
{kind=link}
{kind=link}