





Abstract
MYB transcription factor genes play important roles in many developmental processes and in various defence responses of plants. Two Arabidopsis R2R3-type MYB genes, AtMYB59 and AtMYB48, were found to undergo similar alternative splicing. Both genes have four distinctively spliced transcripts that encode either MYB-related proteins or R2R3-MYB proteins. An extensive BLAST search of the GenBank database resulted in finding and cloning two rice homologues, both of which were also found to share a similar alternative splicing pattern. In a semi-quantitative study, the expression of one splice variant of AtMYB59 was found to be differentially regulated in treatments with different phytohormones and stresses. GFP fusion protein analysis revealed that both of the two predicted nuclear localization signals (NLSs) in the R3 domain are required for localizing to the nucleus. Promoter–GUS analysis in transgenic plants showed that 5′-UTR is sufficient for the translation initiation of type 3 transcripts (encoding R2R3-MYB proteins), but not for type 2 transcripts (encoding MYB-related proteins). Moreover, a new type of non-canonical intron, with the same nucleotide repeats at the 5′ and 3′ splice sites, was identified. Thirty-eight Arabidopsis and rice genes were found to have this type of non-canonical intron, most of which undergo alternative splicing. These data suggest that this subgroup of transcription factor genes may be involved in multiple biological processes and may be transcriptionally regulated by alternative splicing.
Introduction
Alternative splicing of pre-mRNAs is one of the most complex cellular processes in eukaryotes and accounts for a large proportion of proteomic complexity (Lorkovic et al., 2000; Reddy, 2001; Kazan, 2003). The combinatorial joining of exons by alternative splicing is an elegant mechanism that most eukaryotes use to generate several distinct proteins from a single transcript. It has been estimated that about 40% of all human genes have alternatively spliced forms (Hanke et al., 1999; Brett et al., 2000). However, as of November 2004, only 394 plant genes, including 263 in Arabidopsis and 11 in rice, have been found to be alternatively spliced (Plant Alternative Splicing Database, http://pasdb.genomics.org.cn/index.jsp). Only 15 genes, such as the genes encoding Rubisco activase (Rca), MADS-box genes, ascorbate peroxidase, and starch-branching enzyme (SBE), have been found to be alternatively spliced in more than one plant species (Zhou et al., 2003; Plant Alternative Splicing Database, http://pasdb.genomics.org.cn/index.jsp). Furthermore, although data from both animals and plants suggest tissue-specific and temporal regulation of alternative splicing (Brown and Simpson, 1998; Reddy, 2001), the mechanisms that regulate alternative splicing in plants remain unknown.
MYB proteins are transcription factors with a MYB domain that contains one to three imperfect repeats of 51–53 amino acid residues (Stracke et al., 2001; Chen et al., 2006). Animal genomes encode relatively few MYB proteins (Rosinski and Atchley, 1998), while plant genomes encode a large number of MYB proteins which play important roles in many developmental processes and in various defence responses (Stracke et al., 2001; Chen et al., 2006). In animal cells, MYB genes undergo alternative splicing. Different splice forms of c-myb RNAs occur in normal and tumour mouse cells (Shen-Ong, 1987). The primary transcript of B-myb, a highly conserved member of the MYB transcription factor family, is also alternatively spliced (Horstmann et al., 2000). Two plant MYB genes, maize P and rice myb7, were reported to undergo alternative splicing. P was found to have two transcripts alternatively spliced at the 3′ ends in maize, while myb7 was found in both spliced and unspliced forms in rice, the ratio of which increased with anoxia in roots (Grotewold et al., 1991; Magaraggia et al., 1997).
Higher eukaryotes have two classes of nuclear pre-mRNA introns: U2 introns, the more abundant class spliced by U2-type spliceosomes, and U12 introns, the less abundant class (<0.4% of all introns) processed by U12-type spliceosomes (Hall and Padgett, 1994; Wu and Krainer, 1996; Sharp and Burge, 1997; Burge et al., 1998; Lewandowska et al., 2004). An analysis of over 53 000 confirmed human introns has shown that 98.12% use the canonical GT–AG dinucleotides, whereas only 0.76% use the GC–AG dinucleotides (International Human Genome Sequencing Consortium, 2001). Although the first U12 introns described had AT–AC terminal dinucleotides, further characterization has shown that most U12-type introns contain GT–AG dinucleotides, while few contain other non-canonical terminal dinucleotides such as AT–AA, AT–AG, AT–AT, GT–AT, or GT–GG (Burge et al., 1998; Levine and Durbin, 2001; Zhu and Brendel, 2003; Lewandowska et al., 2004). In Arabidopsis, a recent computational search identified 165 U12-type introns and several alternative splicing events (Zhu and Brendel, 2003).
In this paper, it is reported that a subgroup of MYB genes from both Arabidopsis and rice undergoes conserved alternative splicing. This alternative splicing results in three (rice) or four (Arabidopsis) distinctively spliced transcripts for each gene, producing either MYB-related or R2R3-MYB proteins. This is the first report that a single MYB gene encodes two types of MYB proteins. At the same time, a new type of non-canonical intron, with the same nucleotide repeats at the 5′ and 3′ splice sites, is reported. The subcellular localization of each putative MYB protein was systematically investigated and two nuclear localization signals (NLSs) were confirmed in the R3 repeat.
Materials and methods
Plant material and growth conditions
Arabidopsis ecotype Columbia grown on soil at 24 °C was used. Mature leaves, stems, inflorescences, and roots were harvested from flowering plants at 4–6 weeks. Siliques were collected later. The plant materials were treated and grown under the following conditions. A liquid culture system was adopted. 100 surface-sterilized seeds were germinated in 40 ml of MS liquid medium containing 1% sucrose in a 100 ml flask. The seedlings were grown for 2 weeks with a 16/8 h light/dark photoperiod. The plant materials were collected 8 h after the addition of either ABA, GA3, JA, kinetin, or SA to 100 μM final concentration, or IAA to 10 μM final concentration, or 4 h after the addition of ethephon to 1 mM final concentration. Arabidopsis calli were cultivated on MS plates containing 3% sucrose under a 16 h light photoperiod or 8 h complete darkness (dark). Stress treatments involved seedlings being collected 6 h and 4 h after the addition of CdCl2 to 100 μM final concentration and NaCl to 300 mM final concentration, respectively.
The Oryza sativa ssp. japonica cultivar Zhonghua 11 was used. Rice seeds were immersed in water for 4 d and then transferred to soil and grown for 1 month in the greenhouse.
RNA extraction and cDNA synthesis
Total RNAs were isolated from leaves, roots, siliques, inflorescences, and stems of 4–6-week-old Arabidopsis plants, and from seedlings that were subjected to the treatments described above, using RNeasy Mini Kit (Qiagen, Valencia, CA) according to the manufacturer's instructions. First-strand cDNAs were synthesized using the Superscript II RNase H–Reverse Transcriptase Kit (Invitrogen, Carlsbad, CA) according to the manufacturer's instructions, and then used as the templates for RT-PCR amplification.
Rice RNA isolation and cDNA synthesis were carried out with the same protocols described above.
Cloning of cDNAs and semi-quantitative RT-PCR
One pair of specific primers was designed for each gene, to amplify the fragments of interest in Arabidopsis and rice by RT-PCR with Ex Taq DNA polymerase (Takara): AtMYB59_fw: 5′-ATG AAA CTT GTG CAA GAA GAA-3′; AtMYB59_rev: 5′-CTA AAG GCG ACC ACT ACC ATG-3′; AtMYB48_fw: 5′-ATG ATG CAA GAG GAG GGA AAC-3′; AtMYB48_rev: 5′-TTA ACC TGA CGA CCA TGG TGA-3′; AK111626_fw: 5′-ACA ACG TTA GCA TTG CAA CAT-3′; AK111626_rev: 5′-ATA TCT TGA TGT ATG GCT TTA-3′; AK107214_fw: 5′-GCA ACA CTG TCA TCA TAT ACT-3′; and AK107214_rev: 5′-GGT AAC CTA GTC CAA TAT ATT-3′.
cDNAs reverse-transcribed from the mixture of mRNAs isolated from Arabidopsis plants as mentioned above, and from the mRNAs isolated from 5-week-old rice seedlings were used as the templates for PCR amplification for the different transcripts of the four genes listed above. PCR was performed for 35 cycles, each with 94 °C for 50 s, 60 °C for 50 s, and 72 °C for 2 min. The amplified DNA fragments were purified using the QIAquick PCR Purification Kit (Qiagen, Valencia, CA) and cloned with the pGEM-T Easy Vector System (Promega, Madison, WI). Fifty independent clones were screened by PCR for the different length of the inserts and five clones for each of the different insert lengths were sequenced for sequence confirmation.
The expression pattern of each gene was analysed by RT-PCR using the following primers: AtMYB48_fw: 5′-ATG ATG CAA GAG GAG GGA AAC-3′; AtMYB48_rev: 5′-TTA ACC TGA CGA CCA TGG TGA-3′; AtMYB59_fw1: 5′-ATG AAA CTT GTG CAA GAA GAA-3′; AtMYB59_rev1: 5′-CCT GCA ACT CTT TCC TGT TCT-3′; AtMYB59_fw2: 5′-GGG CGG TCT TTG GAA AGG ACC-3′; and AtMYB59_rev2: 5′-CTA AAG GCG ACC ACT ACC ATG-3′.
For AtMYB48, differently spliced transcripts were amplified in one PCR reaction with the primers AtMYB48_fw and AtMYB48_rev. For AtMYB59, two amplification reactions were carried out, respectively, one with the primers AtMYB59_fw2 and AtMYB59_rev2 to amplify AtMYB59-1 (expected size 643 bp), and the other with AtMYB59_fw1 and AtMYB59_rev1 to amplify AtMYB59-2 (expected size 182 bp) and AtMYB59-3 (expected size 150 bp). The AtMYB59-4 transcript (expected size 258 bp) did not actually form a clear single band by the primers AtMYB59_fw1 and AtMY59_rev2, possibly due to its extremely low abundance. But, theoretically, with the primers AtMYB59_fw1 and AtMYB59_rev1, AtMYB59-4 could be amplified as a same-sized fragment as that of AtMYB59-3, thus AtMYB59-4 and AtMYB59-3 share the same amplified fragment in the RT-PCR.
BLAST and phylogenetic analyses
BLAST search against GenBank nr database (http://www.ncbi.nlm.nih.gov/BLAST/) was conducted. PHYLIP package (Felsenstein, 1989) was used to construct phylogenetic trees with the parsimony method.
GFP fusion protein analysis
The shuttle vector pRTL2-GFP has been described before (Yi et al., 2002). Primers were designed to obtain each full-length ORF sequence by PCR amplification using a high-fidelity DNA polymerase (Pyrobest polymerase, Takara). The primers used were as follows: AtMYB59-1_fw: 5′-CAC AGA TCT ATG ACT CCA CAA GAA GAG CG-3′; AtMYB59-2_fw: 5′-CAC AGA TCT ATG GGA TTT TGT AGC GAA AG-3′; AtMYB59-3(-4)_fw: 5′-CAC AGA TCT ATG AAA CTT GTG CAA GAA GA-3′; AtMYB59_rev: 5′-GCG TCT AGA CTA AAG GCG ACC ACT ACC ATG-3′; AtMYB48-1_fw: 5′-CAC AGA TCT ATG ACG CCT CAA GAA GAG CG-3′; AtMYB48-2_fw: 5′-CAC AGA TCT ATG GAC AGA ACA GGA AGA CA-3′; AtMYB48-3_fw: 5′-CAC AGA TCT ATG ATG CAA GAG GAG GGA AA-3′; and AtMYB48_rev: 5′-GCG TCT AGA CTA ACC TGA CGA CCA TGG TGA TC-3′.
The underlined nucleotides correspond to BglII and XbaI restriction sites, respectively. The sequenced pGEM-T plasmids were used as templates for each PCR reaction. The purified PCR fragments were cut with BglII and XbaI, and cloned into pRTL2-GFP, to produce fusion proteins adjacent to the C-terminus of the Aequora victoria GFP. The constructs for fusion protein production were verified by sequencing. The constructs (5 μg of plasmid DNA per assay) were bombarded into the single-layer onion epidermal cells using the Biolistic PDS-1000/He Particle Delivery System (Bio-Rad) according to the manufacturer's instructions. After the bombardment, the plates were incubated at room temperature for 48 h before observation. The onion cells were observed with an Olympus BX51 microscope. Images were processed for printing using Adobe Photoshop software.
Promoter–reporter gene fusion and GUS activity analysis
The promoter regions of AtMYB59-2, AtMY59-3, AtMYB48-2, and AtMYB48-3 were amplified from Arabidopsis genomic DNA by PCR using the following primers: AtMYB59-GUS-F: 5′-TAA GGA TCC AGA CGT TTA GGG GAT AAG-3′; AtMYB59-2-GUS-R: 5′-TCT CTG CAG ACC TTC AAA CCT GAA ACT-3′; AtMYB59-3-GUS-R: 5′-CCA CTG CAG TTT ACG GTA TTC TTC TTG-3′; AtMYB48-GUS-F: 5′-GTC GGA TCC CGC ACC ACG GGC T-3′; AtMYB48-2-GUS-R: 5′-ACC CTG CAG ATG TCT TCC TGT TCT GTC-3′; AtMYB48-3-GUS-R: 5′-TTT CTG CAG TCC CTC CTC TTG CAT CAT-3′.
The underlined nucleotides correspond to BamHI and PstI restriction sites, respectively. The amplified fragments were cloned into pCAMBIA 1381 (CAMBIA, Canberra, Australia), respectively, and transformed into Arabidopsis. The transgenic plants were examined for the GUS activity as described (Jefferson et al., 1987).
Results
AtMYB59 and AtMYB48 undergo similar alternative splicing
Two MYB transcription factor genes, AtMYB59 and AtMYB48 which were classified into the R2R3-MYB family (Stracke et al., 2001), share 74.2% nucleotide sequence identity in their coding region (Fig. 1A, B) and resulted from a relatively recent duplication event (see supplementary Table 4 in Chen et al., 2006). Four different transcripts that resulted from alternative splicing were confirmed by two independent PCR amplifications for AtMYB59 (Fig. 1C) in an attempt to clone the full-length ORFs of all the MYB transcription factor genes in Arabidopsis (Chen et al., 2006). PCR amplification to screen for possible alternative splicing in its homologue gene, AtMYB48, were conducted, and four distinctively spliced transcripts were also obtained for AtMYB48 (Fig. 1C; see supplementary Fig. 1 at JXB online).
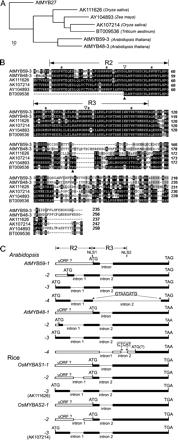
(A) Dendrogram of a subgroup of MYB protein sequences from monocots and dicots: AK111626, AK107214, AY104893, BT009536, AtMYB59-3, and AtMYB48-3. For construction of the tree, 98 amino acid residues (shown in B) were used so as to include the wheat protein sequence which lacks the N-terminal region. The matrix of sequence similarities was calculated with the CLUSTAL program from the CLUSTAL W package (Thompson et al., 1994), and the phylogenetic tree was constructed with the parsimony method using the PHYLIP package (Felsenstein, 1989), with a bootstrap of 100 samples. Branch lengths are indicated by the scale at the bottom left. (B) Sequence alignment of the proteins shown in (A). Identical amino acids are shaded in black, conserved changes in grey. The two MYB domain repeats (R2 and R3) are indicated with sets of arrows, and the critical tryptophan residues are designated with dots. The two intron positions (conserved in Arabidopsis and rice genes) are indicated with open triangles. The black triangles indicate the N- and C-terminals of a 98 amino acid region used to construct the phylogenetic tree (shown in A). Numbers on the right indicate amino acid positions (from the translation start codon). (C) Schematic representation of the differently spliced transcripts of AtMYB59, AtMYB48, OsMYBAS1, and OsMYBAS2. Exons are shown as boxes while introns are shown as lines. The putative open reading frames are indicated by black boxes, and the start codon (ATG) and the stop codons (TAG, TAA, and TGA) of each gene are shown. The nucleotide repeats of the non-canonical introns are shown by asterisks and the repeated sequences are shown in the upper boxes. The two MYB domain repeats (R2 and R3) are indicated with sets of arrows. The location of the two putative NLSs is indicated with arrows.
Analysis of the spliced transcripts of these two genes indicated that they underwent alternative splicing in a similar pattern, therefore, the four transcripts of each gene could be designated into four different groups (Fig. 1C; see supplementary Fig. 1 at JXB online): type 1 is the longest transcript, with the first intron unspliced; type 2, with the first intron spliced, encodes a MYB-related protein with a single MYB repeat translating from the second ATG. Note that the 5′ splice sites of the first intron of the type 2 transcript are different in AtMYB59 and AtMYB48. Type 3, with the first intron spliced, encodes a typical R2R3-MYB protein. The 5′ splice site of the first intron of the type 3 transcripts is conserved in AtMYB59 and AtMYB48. The second intron in all of the above three types of transcripts is spliced, and the splice sites are highly conserved; and type 4 has the least sequence similarity between AtMYB59 and AtMYB48. The only similarity that was found is that each has a non-canonical intron with a nucleotide repeat at both splice sites (Fig. 1C). In the screening for the clones with different transcript inserts, it was found that the ratio of type 1, 2, and 3 transcripts were approximately 4:1:1. The type 4 transcript (AtMYB59-4 and AtMYB48-4), however, has an extremely low abundance, only one clone of the type 4 transcript for each gene was obtained in Arabidopsis.
The ORFs were predicted for the transcripts that were cloned by using ORF Finder software (http://www.ncbi.nlm.nih.gov/gorf/gorf.html), and the longest ORF for each transcript was adopted as the putative ORF (Table 1), which was consistent with the available annotation in Genbank (e.g. NM_180894 for AtMYB59-1, NM_180895 for AtMYB59-2, NM_125370 for AtMYB59-3). Although an ORF (90 aa) was predicted close to the 3′ end of the AtMYB48-4 transcript (Fig. 1C), this transcript was unlikely to code for a protein. The reasons are as follows: the four upstream ORFs existing in the long leader region (516 bp) of this transcript would strongly repress translation of the downstream ORF (Wang and Wessler, 1998; Bailey-Serres, 1999; Locatelli et al., 2002; Wiese et al., 2004); and it has been shown that the transcripts with long, AUG-burdened leader sequences were incapable of supporting protein synthesis (Lee et al., 2000; Kozak, 2002; Larsen et al., 2002)
Information of the alternatively spliced transcripts of AtMYB59, AtMYB48, OsMYBAS1, and OsMYBAS2
Gene name | Accession number | mRNA lengtha (bp) | Predicted CDS length (bp) | Predicted protein length (aa) |
|---|---|---|---|---|
| AtMYB59-1 | DQ075252 | 819 | 513 | 170 |
| AtMYB59-2 | DQ075253 | 740 | 645 | 214 |
| AtMYB59-3 | AY519641 | 708 | 708 | 235 |
| AtMYB59-4 | DQ075254 | 258 | 258 | 85 |
| AtMYB48-1 | DQ075255 | 841 | 579 | 192 |
| AtMYB48-2 | DQ075256 | 713 | 681 | 226 |
| AtMYB48-3 | AY519594 | 771 | 771 | 256 |
| AtMYB48-4 | DQ075257 | 789 | – | – |
| OsMYBAS1-1 | DQ075258 | 839 | 519 | 172 |
| OsMYBAS1-2 | DQ075259 | 742 | 519 | 172 |
| OsMYBAS1-3 | DQ075260 | 714 | 714 | 237 |
| OsMYBAS2-1 | DQ075261 | 857 | 534 | 177 |
| OsMYBAS2-2 | DQ075262 | 758 | 534 | 177 |
| OsMYBAS2-3 | DQ075263 | 729 | 729 | 242 |
Gene name | Accession number | mRNA lengtha (bp) | Predicted CDS length (bp) | Predicted protein length (aa) |
|---|---|---|---|---|
| AtMYB59-1 | DQ075252 | 819 | 513 | 170 |
| AtMYB59-2 | DQ075253 | 740 | 645 | 214 |
| AtMYB59-3 | AY519641 | 708 | 708 | 235 |
| AtMYB59-4 | DQ075254 | 258 | 258 | 85 |
| AtMYB48-1 | DQ075255 | 841 | 579 | 192 |
| AtMYB48-2 | DQ075256 | 713 | 681 | 226 |
| AtMYB48-3 | AY519594 | 771 | 771 | 256 |
| AtMYB48-4 | DQ075257 | 789 | – | – |
| OsMYBAS1-1 | DQ075258 | 839 | 519 | 172 |
| OsMYBAS1-2 | DQ075259 | 742 | 519 | 172 |
| OsMYBAS1-3 | DQ075260 | 714 | 714 | 237 |
| OsMYBAS2-1 | DQ075261 | 857 | 534 | 177 |
| OsMYBAS2-2 | DQ075262 | 758 | 534 | 177 |
| OsMYBAS2-3 | DQ075263 | 729 | 729 | 242 |
Partial mRNA, see Materials and methods and Results sections for the details.
Information of the alternatively spliced transcripts of AtMYB59, AtMYB48, OsMYBAS1, and OsMYBAS2
Gene name | Accession number | mRNA lengtha (bp) | Predicted CDS length (bp) | Predicted protein length (aa) |
|---|---|---|---|---|
| AtMYB59-1 | DQ075252 | 819 | 513 | 170 |
| AtMYB59-2 | DQ075253 | 740 | 645 | 214 |
| AtMYB59-3 | AY519641 | 708 | 708 | 235 |
| AtMYB59-4 | DQ075254 | 258 | 258 | 85 |
| AtMYB48-1 | DQ075255 | 841 | 579 | 192 |
| AtMYB48-2 | DQ075256 | 713 | 681 | 226 |
| AtMYB48-3 | AY519594 | 771 | 771 | 256 |
| AtMYB48-4 | DQ075257 | 789 | – | – |
| OsMYBAS1-1 | DQ075258 | 839 | 519 | 172 |
| OsMYBAS1-2 | DQ075259 | 742 | 519 | 172 |
| OsMYBAS1-3 | DQ075260 | 714 | 714 | 237 |
| OsMYBAS2-1 | DQ075261 | 857 | 534 | 177 |
| OsMYBAS2-2 | DQ075262 | 758 | 534 | 177 |
| OsMYBAS2-3 | DQ075263 | 729 | 729 | 242 |
Gene name | Accession number | mRNA lengtha (bp) | Predicted CDS length (bp) | Predicted protein length (aa) |
|---|---|---|---|---|
| AtMYB59-1 | DQ075252 | 819 | 513 | 170 |
| AtMYB59-2 | DQ075253 | 740 | 645 | 214 |
| AtMYB59-3 | AY519641 | 708 | 708 | 235 |
| AtMYB59-4 | DQ075254 | 258 | 258 | 85 |
| AtMYB48-1 | DQ075255 | 841 | 579 | 192 |
| AtMYB48-2 | DQ075256 | 713 | 681 | 226 |
| AtMYB48-3 | AY519594 | 771 | 771 | 256 |
| AtMYB48-4 | DQ075257 | 789 | – | – |
| OsMYBAS1-1 | DQ075258 | 839 | 519 | 172 |
| OsMYBAS1-2 | DQ075259 | 742 | 519 | 172 |
| OsMYBAS1-3 | DQ075260 | 714 | 714 | 237 |
| OsMYBAS2-1 | DQ075261 | 857 | 534 | 177 |
| OsMYBAS2-2 | DQ075262 | 758 | 534 | 177 |
| OsMYBAS2-3 | DQ075263 | 729 | 729 | 242 |
Partial mRNA, see Materials and methods and Results sections for the details.
Interestingly, except for the AtMYB59-4, all other ORFs encode proteins that differ only in the MYB domains. The AtMYB59-4 transcript encodes a protein with the R2 repeat and the C-terminal region. This is the first report that a MYB gene encodes MYB proteins with both single repeat and two adjacent repeats of the MYB domain (Fig. 1C).
The conserved alternative splicing pattern is found in two rice homologous genes
In an extensive BLAST search of GenBank, four homologous genes of AtMYB59 and AtMYB48 were found in monocots (Fig. 1A, B). These homologous genes are: AK111626 (Oryza sativa), AK107214 (Oryza sativa), AY104893 (Zea mays), and BT009536 (Triticum aestivum). It was found that BT009536 from wheat is a partial cDNA, and apparently a type 1 transcript. The other three cDNAs, two from rice and one from maize, are type 3 transcripts.
To investigate whether these two rice homologous genes undergo similar alternative splicing, two pairs of primers were designed to amplify the corresponding cDNA fragments by RT–PCR. Several transcripts of these two genes were successfully amplified, cloned, and sequenced and were designated OsMYBAS1 (Oryza sativaMYBalternative splicing 1, corresponding to AK111626) and OsMYBAS2 (corresponding to AK107214; Fig. 1C). The sequences of these transcripts were searched against the rice genome and it was found that these transcripts were mapped onto the same genomic location as AK111626 or AK107214 (data not shown). From the sequences, both OsMYBAS1 and OsMYBAS2 have three distinctively spliced transcripts, corresponding to AtMYB59 type 1, 2, and 3 transcripts, respectively (Fig. 1C; see supplementry Fig. 1 at JXB online; Table 1). All nucleotide sequence data have been deposited in GenBank (see Table 1 for the accession numbers).
The fact that BT009536 of wheat is a type 1 transcript and AY104893 of maize is a type 3 transcript suggests that this alternative splicing pattern may exist in many plant species. This alternative splicing pattern, which may have occurred before the divergence of monocots and dicots, was conserved in this subgroup of genes during evolution. A previous study on the MYB genes of Arabidopsis and rice indicated that the exon–intron structure was conserved among subgroups (Jiang et al., 2004). These results demonstrated that besides the conserved exon–intron structure, the alternative splicing pattern may also be conserved in some subgroups of MYB genes in both monocotyledonous (rice) and dicotyledonous (Arabidopsis) plants, although its biological significance is unknown yet.
A new type of non-canonical intron, with the same nucleotide repeats at two ends of the splice sites, is found in the type 4 transcripts and in the transcripts of some other genes with alternative splicing
Non-canonical introns were observed in both AtMYB59-4 and AtMYB48-4 transcripts. Short repeats were found, GTAAGATG for AtMYB59-4 and CTCAT for AtMYB48-4, at both ends of the non-canonical introns. Interestingly, a non-canonical intron flanked by a short nucleotide repeat has been reported for FCA, a gene controlling flowering time in Arabidopsis (Macknight et al., 1997). FCA had four distinctively spliced transcripts. Transcript δ, representing approximately 10% of FCA transcripts, was alternatively spliced at intron 13 which was flanked by two 6 bp repeated sequences, CTGCAG (Macknight et al., 1997).
After an extensive search of the Arabidopsis genome database and referring to the list of Arabidopsis genes that have non-consensus splice sites identified by The Institute for Genomic Research (TIGR) (http://www.tigr.org/tdb/e2k1/ath1/Arabidopsis_nonconsensus_splice_sites.shtml), it was found that 30 genes in the TIGR list had non-consensus splice sites, and five other newly-found Arabidopsis genes were added to the list (Table 2). Together with AtMYB59 and AtMYB48, as well as the rice aquaporin gene OsPIP1-3 that was cloned in another study (unpublished data), 38 genes with non-canonical introns were listed in Table 2. All non-canonical introns are neither U2- nor U12-type. Some of these genes have already been demonstrated to undergo alternative splicing. These data suggested that there is a new type of non-canonical intron existing in plants, different from the well-characterized U2 and U12 introns.
Summary of 38 genes from Arabidopsis and rice that have non-canonical introns
Gene code | No. of transcriptsa | No. of non-canonical intronsb | Nucleotide repeatsb | Description | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Thirty genes in the TIGR listc | ||||||||||
| GA–AGd | At2g41150 | 2 | 1 | CAG | Expressed protein | |||||
| At1g62200 | 1 | 1 | G | Oligopeptide transporter, putative | ||||||
| At1g21750 | 2 | 1 | AGACAG | Protein disulphide isomerase, putative | ||||||
| At1g69020 | 1 | 2 | CAGG (1)e, AGG(1) | Prolyl oligopeptidase family protein | ||||||
| At3g10350 | 1 | 1 | AGG | Putative ATPase | ||||||
| At3g08900 | 1 | 1 | CAGG | Reversibly glycosylated polypeptide-3 | ||||||
| At4g27500 | 1 | 1 | AGGA | Expressed protein | ||||||
| At5g20960 | 2 | 1 | AGGAA | Aldehyde oxidase 1 | ||||||
| AT–AG | At3g50550 | 2 | 1 | GATGATGATGATGA | Expressed protein | |||||
| At1g54040 | 2 | 1 | AG | Kelch repeat-containing protein | ||||||
| At1g33290 | 2 | 1 | ATTGG | Sporulation protein-related | ||||||
| At4g18010 | 2 | 1 | GAAGAG | Inositol polyphosphate 5-phosphatase II | ||||||
| At3g63400 | 2 | 1 | GATG | Cyclophylin-like protein | ||||||
| GT–TG | At1g09970 | 2 | 1 | G | Leucine-rich repeat transmembrane protein kinase, putative | |||||
| At1g72550 | 2 | 1 | G | tRNA synthetase β subunit family protein | ||||||
| At4g34050 | 2 | 1 | GTTG | Caffeoyl-CoA 3-O-methyltransferase, putative | ||||||
| At5g19090 | 2 | 1 | TGGTGGTGG | Heavy-metal-associated domain-containing protein | ||||||
| GT–GG | At1g04590 | 2 | 1 | GGTT | Expressed protein | |||||
| At1g23480 | 2 | 1 | GG | Glycosyl transferase family 2 protein | ||||||
| At1g37150 | 4 | 3 | G (1), GG (2) | Holocarboxylase synthetase 2 | ||||||
| At5g13540 | 2 | 1 | GGTTGG | Expressed protein | ||||||
| AG–AG | At1g60000 | 2 | 1 | GGAAGA | 29 kDa ribonucleoprotein, chloroplast, putative | |||||
| GT–AT | At1g79670 | 2 | 1 | GTTGT | Wall-associated kinase, putative | |||||
| At3g18520 | 2 | 1 | GT | Histone deacetylase family protein | ||||||
| At5g50200 | 3 | 1 | CATG | Expressed protein | ||||||
| At3g51860 | 1 | 1 | T | Cation exchanger, putative | ||||||
| At5g20250 | 2 | 1 | Not found | Raffinose synthase family protein | ||||||
| GT–AC | At4g28520 | 3 | 1 | TGACGT | 12S seed storage protein, putative | |||||
| GT–CG | At4g39260 | 4 | 3 | GGAGGCGGTGGTGG (1), ACGG (1), GCGG (1) | Glycine-rich RNA-binding protein 8 | |||||
| At3g55030 | 1 | 1 | G | Phosphatidylglycerol-phosphate synthase, putative | ||||||
| Five genes that are not in the TIGR list but have non-canonical introns and undergo alternative splicinga | ||||||||||
| At2g18460 | 2 | 3 | T (1), not found (2) | Expressed protein | ||||||
| At2g34390 | 2 | 1 | GA | Major intrinsic family protein | ||||||
| At4g16280 | 4 | 1 | CTGCAG | Flowering time control protein (FCA) | ||||||
| At4g18330 | 2 | 1 | GG | Eukaryotic translation initiation factor 2 subunit 3, putative | ||||||
| At5g05657 | 2 | 2 | T (1), not found (1) | Harpin-induced family protein | ||||||
| Two Arabidopsis and one rice non-canonical introns that have been identified | ||||||||||
| Arabidopsis | At3g46130 | 4 | 1 | CTCAT | Myb family transcription factor (MYB48) | |||||
| At5g59780 | 4 | 1 | GTAAGATG | Myb family transcription factor (MYB59) | ||||||
| Rice | OsPIP1-3 | 2 | 1 | CATC | Rice aquaporin PIP family protein | |||||
Gene code | No. of transcriptsa | No. of non-canonical intronsb | Nucleotide repeatsb | Description | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Thirty genes in the TIGR listc | ||||||||||
| GA–AGd | At2g41150 | 2 | 1 | CAG | Expressed protein | |||||
| At1g62200 | 1 | 1 | G | Oligopeptide transporter, putative | ||||||
| At1g21750 | 2 | 1 | AGACAG | Protein disulphide isomerase, putative | ||||||
| At1g69020 | 1 | 2 | CAGG (1)e, AGG(1) | Prolyl oligopeptidase family protein | ||||||
| At3g10350 | 1 | 1 | AGG | Putative ATPase | ||||||
| At3g08900 | 1 | 1 | CAGG | Reversibly glycosylated polypeptide-3 | ||||||
| At4g27500 | 1 | 1 | AGGA | Expressed protein | ||||||
| At5g20960 | 2 | 1 | AGGAA | Aldehyde oxidase 1 | ||||||
| AT–AG | At3g50550 | 2 | 1 | GATGATGATGATGA | Expressed protein | |||||
| At1g54040 | 2 | 1 | AG | Kelch repeat-containing protein | ||||||
| At1g33290 | 2 | 1 | ATTGG | Sporulation protein-related | ||||||
| At4g18010 | 2 | 1 | GAAGAG | Inositol polyphosphate 5-phosphatase II | ||||||
| At3g63400 | 2 | 1 | GATG | Cyclophylin-like protein | ||||||
| GT–TG | At1g09970 | 2 | 1 | G | Leucine-rich repeat transmembrane protein kinase, putative | |||||
| At1g72550 | 2 | 1 | G | tRNA synthetase β subunit family protein | ||||||
| At4g34050 | 2 | 1 | GTTG | Caffeoyl-CoA 3-O-methyltransferase, putative | ||||||
| At5g19090 | 2 | 1 | TGGTGGTGG | Heavy-metal-associated domain-containing protein | ||||||
| GT–GG | At1g04590 | 2 | 1 | GGTT | Expressed protein | |||||
| At1g23480 | 2 | 1 | GG | Glycosyl transferase family 2 protein | ||||||
| At1g37150 | 4 | 3 | G (1), GG (2) | Holocarboxylase synthetase 2 | ||||||
| At5g13540 | 2 | 1 | GGTTGG | Expressed protein | ||||||
| AG–AG | At1g60000 | 2 | 1 | GGAAGA | 29 kDa ribonucleoprotein, chloroplast, putative | |||||
| GT–AT | At1g79670 | 2 | 1 | GTTGT | Wall-associated kinase, putative | |||||
| At3g18520 | 2 | 1 | GT | Histone deacetylase family protein | ||||||
| At5g50200 | 3 | 1 | CATG | Expressed protein | ||||||
| At3g51860 | 1 | 1 | T | Cation exchanger, putative | ||||||
| At5g20250 | 2 | 1 | Not found | Raffinose synthase family protein | ||||||
| GT–AC | At4g28520 | 3 | 1 | TGACGT | 12S seed storage protein, putative | |||||
| GT–CG | At4g39260 | 4 | 3 | GGAGGCGGTGGTGG (1), ACGG (1), GCGG (1) | Glycine-rich RNA-binding protein 8 | |||||
| At3g55030 | 1 | 1 | G | Phosphatidylglycerol-phosphate synthase, putative | ||||||
| Five genes that are not in the TIGR list but have non-canonical introns and undergo alternative splicinga | ||||||||||
| At2g18460 | 2 | 3 | T (1), not found (2) | Expressed protein | ||||||
| At2g34390 | 2 | 1 | GA | Major intrinsic family protein | ||||||
| At4g16280 | 4 | 1 | CTGCAG | Flowering time control protein (FCA) | ||||||
| At4g18330 | 2 | 1 | GG | Eukaryotic translation initiation factor 2 subunit 3, putative | ||||||
| At5g05657 | 2 | 2 | T (1), not found (1) | Harpin-induced family protein | ||||||
| Two Arabidopsis and one rice non-canonical introns that have been identified | ||||||||||
| Arabidopsis | At3g46130 | 4 | 1 | CTCAT | Myb family transcription factor (MYB48) | |||||
| At5g59780 | 4 | 1 | GTAAGATG | Myb family transcription factor (MYB59) | ||||||
| Rice | OsPIP1-3 | 2 | 1 | CATC | Rice aquaporin PIP family protein | |||||
Searched and acquired from NCBI web site: (http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?CMD=search&DB=gene).
Analysed by the authors.
Gene list is available on TIGR: (http://www.tigr.org/tdb/e2k1/ath1/Arabidopsis_nonconsensus_splice_sites.shtml). AT–AC and AT–AT introns, which belong to the U12-type introns, are deleted in this table. Three other genes in the TIGR list were also deleted: At1g05135, annotated as a pseudo gene; At5g23720 and At4g35920, no non-canonical intron has been found in them.
Dinucleotides in this table indicate the predicted 5′ and 3′ intron splice sites (in the TIGR list).
The number in the brackets indicates the number of the non-canonical intron with that kind of nucleotide repeat. This indication only appears if a gene has more than one non-canonical intron.
Summary of 38 genes from Arabidopsis and rice that have non-canonical introns
Gene code | No. of transcriptsa | No. of non-canonical intronsb | Nucleotide repeatsb | Description | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Thirty genes in the TIGR listc | ||||||||||
| GA–AGd | At2g41150 | 2 | 1 | CAG | Expressed protein | |||||
| At1g62200 | 1 | 1 | G | Oligopeptide transporter, putative | ||||||
| At1g21750 | 2 | 1 | AGACAG | Protein disulphide isomerase, putative | ||||||
| At1g69020 | 1 | 2 | CAGG (1)e, AGG(1) | Prolyl oligopeptidase family protein | ||||||
| At3g10350 | 1 | 1 | AGG | Putative ATPase | ||||||
| At3g08900 | 1 | 1 | CAGG | Reversibly glycosylated polypeptide-3 | ||||||
| At4g27500 | 1 | 1 | AGGA | Expressed protein | ||||||
| At5g20960 | 2 | 1 | AGGAA | Aldehyde oxidase 1 | ||||||
| AT–AG | At3g50550 | 2 | 1 | GATGATGATGATGA | Expressed protein | |||||
| At1g54040 | 2 | 1 | AG | Kelch repeat-containing protein | ||||||
| At1g33290 | 2 | 1 | ATTGG | Sporulation protein-related | ||||||
| At4g18010 | 2 | 1 | GAAGAG | Inositol polyphosphate 5-phosphatase II | ||||||
| At3g63400 | 2 | 1 | GATG | Cyclophylin-like protein | ||||||
| GT–TG | At1g09970 | 2 | 1 | G | Leucine-rich repeat transmembrane protein kinase, putative | |||||
| At1g72550 | 2 | 1 | G | tRNA synthetase β subunit family protein | ||||||
| At4g34050 | 2 | 1 | GTTG | Caffeoyl-CoA 3-O-methyltransferase, putative | ||||||
| At5g19090 | 2 | 1 | TGGTGGTGG | Heavy-metal-associated domain-containing protein | ||||||
| GT–GG | At1g04590 | 2 | 1 | GGTT | Expressed protein | |||||
| At1g23480 | 2 | 1 | GG | Glycosyl transferase family 2 protein | ||||||
| At1g37150 | 4 | 3 | G (1), GG (2) | Holocarboxylase synthetase 2 | ||||||
| At5g13540 | 2 | 1 | GGTTGG | Expressed protein | ||||||
| AG–AG | At1g60000 | 2 | 1 | GGAAGA | 29 kDa ribonucleoprotein, chloroplast, putative | |||||
| GT–AT | At1g79670 | 2 | 1 | GTTGT | Wall-associated kinase, putative | |||||
| At3g18520 | 2 | 1 | GT | Histone deacetylase family protein | ||||||
| At5g50200 | 3 | 1 | CATG | Expressed protein | ||||||
| At3g51860 | 1 | 1 | T | Cation exchanger, putative | ||||||
| At5g20250 | 2 | 1 | Not found | Raffinose synthase family protein | ||||||
| GT–AC | At4g28520 | 3 | 1 | TGACGT | 12S seed storage protein, putative | |||||
| GT–CG | At4g39260 | 4 | 3 | GGAGGCGGTGGTGG (1), ACGG (1), GCGG (1) | Glycine-rich RNA-binding protein 8 | |||||
| At3g55030 | 1 | 1 | G | Phosphatidylglycerol-phosphate synthase, putative | ||||||
| Five genes that are not in the TIGR list but have non-canonical introns and undergo alternative splicinga | ||||||||||
| At2g18460 | 2 | 3 | T (1), not found (2) | Expressed protein | ||||||
| At2g34390 | 2 | 1 | GA | Major intrinsic family protein | ||||||
| At4g16280 | 4 | 1 | CTGCAG | Flowering time control protein (FCA) | ||||||
| At4g18330 | 2 | 1 | GG | Eukaryotic translation initiation factor 2 subunit 3, putative | ||||||
| At5g05657 | 2 | 2 | T (1), not found (1) | Harpin-induced family protein | ||||||
| Two Arabidopsis and one rice non-canonical introns that have been identified | ||||||||||
| Arabidopsis | At3g46130 | 4 | 1 | CTCAT | Myb family transcription factor (MYB48) | |||||
| At5g59780 | 4 | 1 | GTAAGATG | Myb family transcription factor (MYB59) | ||||||
| Rice | OsPIP1-3 | 2 | 1 | CATC | Rice aquaporin PIP family protein | |||||
Gene code | No. of transcriptsa | No. of non-canonical intronsb | Nucleotide repeatsb | Description | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Thirty genes in the TIGR listc | ||||||||||
| GA–AGd | At2g41150 | 2 | 1 | CAG | Expressed protein | |||||
| At1g62200 | 1 | 1 | G | Oligopeptide transporter, putative | ||||||
| At1g21750 | 2 | 1 | AGACAG | Protein disulphide isomerase, putative | ||||||
| At1g69020 | 1 | 2 | CAGG (1)e, AGG(1) | Prolyl oligopeptidase family protein | ||||||
| At3g10350 | 1 | 1 | AGG | Putative ATPase | ||||||
| At3g08900 | 1 | 1 | CAGG | Reversibly glycosylated polypeptide-3 | ||||||
| At4g27500 | 1 | 1 | AGGA | Expressed protein | ||||||
| At5g20960 | 2 | 1 | AGGAA | Aldehyde oxidase 1 | ||||||
| AT–AG | At3g50550 | 2 | 1 | GATGATGATGATGA | Expressed protein | |||||
| At1g54040 | 2 | 1 | AG | Kelch repeat-containing protein | ||||||
| At1g33290 | 2 | 1 | ATTGG | Sporulation protein-related | ||||||
| At4g18010 | 2 | 1 | GAAGAG | Inositol polyphosphate 5-phosphatase II | ||||||
| At3g63400 | 2 | 1 | GATG | Cyclophylin-like protein | ||||||
| GT–TG | At1g09970 | 2 | 1 | G | Leucine-rich repeat transmembrane protein kinase, putative | |||||
| At1g72550 | 2 | 1 | G | tRNA synthetase β subunit family protein | ||||||
| At4g34050 | 2 | 1 | GTTG | Caffeoyl-CoA 3-O-methyltransferase, putative | ||||||
| At5g19090 | 2 | 1 | TGGTGGTGG | Heavy-metal-associated domain-containing protein | ||||||
| GT–GG | At1g04590 | 2 | 1 | GGTT | Expressed protein | |||||
| At1g23480 | 2 | 1 | GG | Glycosyl transferase family 2 protein | ||||||
| At1g37150 | 4 | 3 | G (1), GG (2) | Holocarboxylase synthetase 2 | ||||||
| At5g13540 | 2 | 1 | GGTTGG | Expressed protein | ||||||
| AG–AG | At1g60000 | 2 | 1 | GGAAGA | 29 kDa ribonucleoprotein, chloroplast, putative | |||||
| GT–AT | At1g79670 | 2 | 1 | GTTGT | Wall-associated kinase, putative | |||||
| At3g18520 | 2 | 1 | GT | Histone deacetylase family protein | ||||||
| At5g50200 | 3 | 1 | CATG | Expressed protein | ||||||
| At3g51860 | 1 | 1 | T | Cation exchanger, putative | ||||||
| At5g20250 | 2 | 1 | Not found | Raffinose synthase family protein | ||||||
| GT–AC | At4g28520 | 3 | 1 | TGACGT | 12S seed storage protein, putative | |||||
| GT–CG | At4g39260 | 4 | 3 | GGAGGCGGTGGTGG (1), ACGG (1), GCGG (1) | Glycine-rich RNA-binding protein 8 | |||||
| At3g55030 | 1 | 1 | G | Phosphatidylglycerol-phosphate synthase, putative | ||||||
| Five genes that are not in the TIGR list but have non-canonical introns and undergo alternative splicinga | ||||||||||
| At2g18460 | 2 | 3 | T (1), not found (2) | Expressed protein | ||||||
| At2g34390 | 2 | 1 | GA | Major intrinsic family protein | ||||||
| At4g16280 | 4 | 1 | CTGCAG | Flowering time control protein (FCA) | ||||||
| At4g18330 | 2 | 1 | GG | Eukaryotic translation initiation factor 2 subunit 3, putative | ||||||
| At5g05657 | 2 | 2 | T (1), not found (1) | Harpin-induced family protein | ||||||
| Two Arabidopsis and one rice non-canonical introns that have been identified | ||||||||||
| Arabidopsis | At3g46130 | 4 | 1 | CTCAT | Myb family transcription factor (MYB48) | |||||
| At5g59780 | 4 | 1 | GTAAGATG | Myb family transcription factor (MYB59) | ||||||
| Rice | OsPIP1-3 | 2 | 1 | CATC | Rice aquaporin PIP family protein | |||||
Searched and acquired from NCBI web site: (http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?CMD=search&DB=gene).
Analysed by the authors.
Gene list is available on TIGR: (http://www.tigr.org/tdb/e2k1/ath1/Arabidopsis_nonconsensus_splice_sites.shtml). AT–AC and AT–AT introns, which belong to the U12-type introns, are deleted in this table. Three other genes in the TIGR list were also deleted: At1g05135, annotated as a pseudo gene; At5g23720 and At4g35920, no non-canonical intron has been found in them.
Dinucleotides in this table indicate the predicted 5′ and 3′ intron splice sites (in the TIGR list).
The number in the brackets indicates the number of the non-canonical intron with that kind of nucleotide repeat. This indication only appears if a gene has more than one non-canonical intron.
Among these 38 genes, one (At5g20250) was found to have no nucleotide repeats. Two (At2g18460 and At5g05657) have more than one non-canonical intron, but only one intron with a 1 bp repeat (Table 2). The remaining 35 genes with non-canonical introns have nucleotide repeats of 1–14 bp on both ends of the splice sites (Table 2). No sequence similarity was observed among the repeats, and no conserved splice sites or branch point regions were found for these non-canonical introns. One interesting example is At4g39260, which has three non-canonical introns, each flanked by a distinct repeat.
These repeat-containing non-canonical introns may be involved in a new splicing mechanism, possibly a recombination-like splicing mechanism. Since only five out of 38 genes were found to have more than one non-canonical intron, it is possible that this type of intron is not as common as the U2- or U12-type in plants. The fact that 31 of these 38 genes undergo alternative splicing may suggest a possible correlation between non-canonical introns and alternative splicing.
Expression patterns of different splice variants
To characterize the expression patterns of different splice variants of AtMYB59 and AtMYB48, the expression profiles of the transcripts were examined in different organs with transcript-specific primers. The results indicated that both AtMYB59 and AtMYB48 were mainly expressed in leaves and seedlings, whereas the expression level was relatively low in roots and stems, and even lower in inflorescences (Fig. 2A). This result is consistent with that of reverse northern dot-blot by Chen et al. (2006). Interestingly, the different splice variants of AtMYB59 and AtMYB48 were expressed in different organ-specific patterns. For example, AtMYB59-1 and AtMYB59-2 expressed in roots, leaves, and seedlings, while the expression of AtMYB59-3 and -4 was only detected in seedlings (Fig. 2A). All four transcript variants of AtMYB48 could be detected in leaves, but not always in other organs, for example, AtMYB48-2, the shortest transcript, was only detected in leaves (Fig. 2A). Notably, the type 1 transcript is the most abundant transcript in all tissues examined, which is consistent with its highest frequency in the cloning experiment. The biological relevance of the organ-specific expression of these two genes is not yet understood.
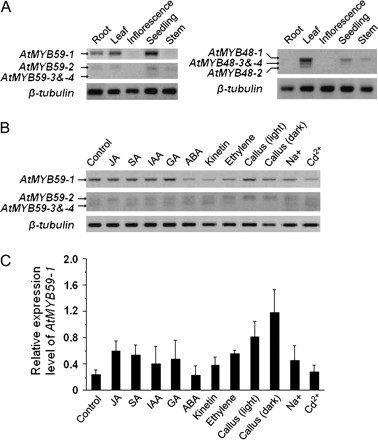
RT-PCR analysis. (A) Expression pattern analysis of alternatively spliced transcripts of AtMYB59 and AtMYB48. On the basis of the sequence alignment, a special amplification strategy was adopted to amplify AtMYB59 transcripts in different sizes using two pairs of specifically designed primers (see Materials and methods section for the details). (B) Effects of different phytohormone and stress treatments on the expression pattern of AtMYB59. In both (A) and (B), PCR amplifications were carried out for 35 cycles. (C) Semi-quantitative RT-PCR analysis of effects of different phytohormone and stress treatments on AtMYB59-1 expression level. PCR amplification was carried out for 26 cycles, and repeated independently for three times. The AtMYB59-1 transcript signals were normalized against that for β-tubulin. The error bars indicate standard deviations.
To study the expression of these MYB genes further, RT–PCR was performed to examine the expression patterns of the different splice variants of AtMYB59 in phytohormone and stress treatments. The results showed that the expression of AtMYB59-3 and AtMYB59-4 was not detectable in the JA treatment, or in calli cultured under light or dark conditions (Fig. 2B). By contrast, the expression of AtMYB59-1 was found to be elevated in nearly all treatments except ABA and Cd2+ (Fig. 2C). For example, the expression of AtMYB59-1 increased more than 2-fold when treated with JA, SA, GA, and ethylene, and up to 6-fold in calli cultured under light or dark conditions (Fig. 2C). These results suggest that AtMYB59 may play a role in multiple signalling pathways.
Both nuclear localization signals (NLSs) in the R3 repeat are required for nuclear localization
Two basic amino acid regions, KRGK and RKKAQEKKR, were found to be highly conserved in this subgroup of MYB genes, and might serve as bipartite nuclear localization signals (NLSs; Fig. 3), which is often found in plant transcription factors (Hardtke and Berleth, 1998; Carrasco et al., 2003). The differently spliced transcripts provide a good system to clarify the function of NLSs in the subcellular localization of the MYB proteins from differently spliced transcripts. GFP fusion protein constructs were generated for seven ORFs of AtMYB59 and AtMYB48, with each full-length coding sequence fused to the GFP gene and bombarded into onion epidermal cells. It was found, that while the expression of GFP was evident in both the nucleus and cytoplasm in the control experiments (Fig. 4H), all type 2 and type 3 transcript-encoded proteins (harbouring both NLS1 and NLS2), i.e. MYB proteins with single and two adjacent MYB repeats, respectively, were clearly localized in the nucleus (Fig. 4B, C, F, G). Type 1 transcript-encoded proteins (harbouring NLS2), however, were only partially localized in the nucleus (Fig. 4A, E). AtMYB59-4 (harbouring NLS1), a small protein of 85 amino acid residues, was also partially localized in the nucleus (Fig. 4D). It is worth noting that the type 1, 2, and 3 transcript-encoded fusion proteins of AtMYB59 share similar subcellular localization patterns with those of AtMYB48, confirming the reliability of the experiments. These results suggest that, although located separately in the N-terminal and C-terminal regions of the R3 repeat, both of the basic NLSs are required for nuclear localization of AtMYB59 and AtMYB48. The amino acid residues in R3 repeats were examined further among all the Arabidopsis R2R3 MYB transcription factors (Stracke et al., 2001), and found that the consensus sequences corresponding to the predicted NLS regions in the R3 repeats of MYB proteins in this study were rich in basic amino acid residues and conserved in almost all of the other Arabidopsis R2R3-MYB proteins (Fig. 3), suggesting that these sites might be NLSs in most Arabidopsis R2R3-MYB proteins and play important roles in the nuclear localization.

Two regions in the R3 domain are rich in basic amino acids. The consensus sequence was from Stracke et al. (2001). The 1st amino acid indicates the amino acid with the highest percentage appearing at the respective position. The 2nd amino acid has a lower percentage. The critical tryptophan residues are designated with dots. Two gaps near the second tryptophan residue were introduced to show the maximal identity to the R2 domain (Stracke et al., 2001). Two regions corresponding to the predicted NLSs of AtMYB59 and AtMYB48 are boxed.
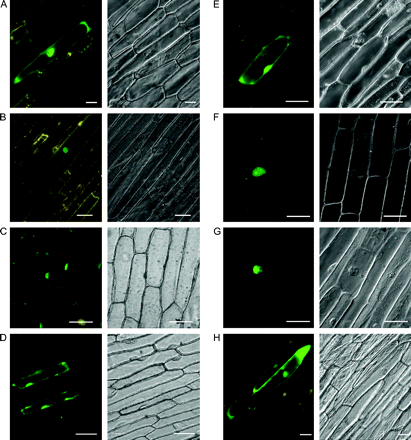
Subcellular localization in onion epidermal cells of each putative protein encoded by AtMYB59 and AtMYB48. Each image was inspected by both a fluorescence microscope (image shown as the left panel) and a differential-interference-contrast microscope (image shown as the right panel). (A) AtMYB59-1, (B) AtMYB59-2, (C) AtMYB59-3, (D) AtMYB59-4, (E) AtMYB48-1, (F) AtMYB48-2, (G) AtMYB48-3, (H) Control cells expressing GFP alone. Bars indicate 50 μm.
5′-UTR is sufficient for the translation of AtMYB59-3 and AtMYB48-3 transcripts
To determine the role of 5′ untranslated regions (5′-UTRs) in the initiation of translation of type 2 and type 3 proteins further, the promoter regions of AtMYB59 (2078 bp) and AtMYB48 (1880 bp) were fused to the β-glucuronidase (GUS) gene with different translational start sites (Fig. 5). Both AtMYB59-2 and AtMYB48-2 use the second AUG to initiate translation, while the first AUG remains in their leader sequence region (Fig. 5). However, AtMYB59-1 and AtMYB48-1 were not included in this translation initiation test, because the leader sequences upstream their ORFs contain the complete sequence of the first intron which could be alternatively spliced into the type 1, 2, or 3 transcripts in Arabidopsis.
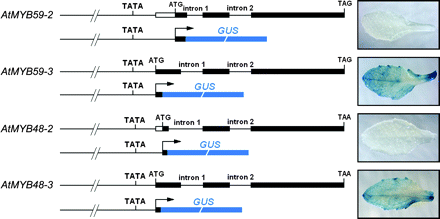
Schematic representation of the four promoter–GUS fusion constructs. For each construct, the upper portion indicates the exon–intron structure of each transcript in the Arabidopsis genome, and the lower portion shows the structure of each promoter–GUS fusion construct. The arrows indicate the translational start sites of each GUS open reading frame. Note that AtMYB59-2 and AtMYB48-2 have two AUG triplets upstream of the GUS coding sequence, and the second AUG was fused to the GUS open reading frame. Fifteen to 33 base pairs immediately downstream of the initiator AUG were kept for each construct, so as to contain the complete initiator AUG context.
Histochemical analysis of transgenic plants showed that no GUS activity was detected in type 2 construct-transformed plants (Fig. 5). However, in transgenic plants harbouring type 3 constructs, GUS activity was detected in most tissues including seedlings, mature leaves, flowers, siliques, and stems (Fig. 5; only the leaf results are shown). This result indicates that the 5’-UTR is sufficient to initiate the translation of type 3 transcripts, but is not sufficient to initiate the translation of type 2 transcripts.
Discussion
Alternative splicing is one of the most complex cellular processes in eukaryotes. Only a small number of alternative splicing events have been reported in plants. In this study, it is reported that two R2R3-MYB genes, Arabidopsis AtMYB59 and AtMYB48, and their rice homologues (OsMYBAS1 and OsMYBAS2), undergo a similar pattern of alternative splicing, producing four differently spliced transcripts in Arabidopsis and three in rice. Although more than 50 clones were sequenced, the type 4 transcript was not detected in rice; the reason for this remains unknown. Since the AtMYB48-4 transcript is unlikely to encode a protein, the biological relevance of this type of transcript remains to be determined.
The spliceosomal system adopted to remove an intron is not dependent on the sequence of the terminal dinucleotide, i.e. the U12-dependent splicing system can splice introns with /GU and AG/ termini, which were thought to be spliced by the U2-dependent splicing system (Dietrich et al., 1997). The finding of these new non-canonical introns that are neither U2- nor U12-types raises new questions: what is the relationship between the non-canonical introns and the typical introns, and can the non-canonical introns be removed by the U2- or U12-dependent splicing system? This study's sequence analysis revealed that these non-canonical introns contain neither the known conserved 5′ and 3′ splice sites nor branch point sequences, but short repeats. These repeats have different lengths and show no sequence similarity between one another. These data suggest that the splicing of these non-canonical introns may be involved in a mechanism other than a U2- or U12-dependent mechanism, but is similar to recombination, and that those repeats may play a special role in this mechanism. The fact that these repeat-flanking non-canonical introns are found in both dicotyledonous and monocotyledonous plants suggests that some new splicing mechanism might exist ubiquitously in plants. It reflects the complexity of the splicing mechanisms in higher plants.
According to the first-AUG rule, the small (40S) ribosomal subunit enters at the 5′ end of the mRNA, migrates along the mRNA strand, and stops when the first AUG codon is encountered (Kozak, 2002). However, two ancillary mechanisms, i.e. re-initiation and context-dependent leaky scanning, can circumvent the first-AUG rule, making downstream AUG codons accessible (Kozak, 2002). Context-dependent leaky scanning is a mechanism that some 40S ribosomal subunits bypass the first AUG codon depending on the sequences flanking it, and initiate at the second or, rarely, even the third AUG; while the re-initiation mechanism involves the translation of upstream ORFs (uORFs) before the translation of downstream main ORF (mORF; Kozak, 1999, 2002). In this study, it was found that, except for the type 3 and AtMYB59-4 transcripts, all the other initiation AUG codons of the putative proteins are located downstream the first AUGs (Fig. 1C). Therefore, selective translation mechanisms must be adopted for the translation of a certain putative ORF. It is speculated that a context-dependent leaky scanning mechanism might be adopted in the translation of the type 2 transcripts in Arabidopsis, due to the lack of uORF in their leader sequences, while a reinitiation mechanism be adopted in the translation of all type 1 transcripts and type 2 transcripts in rice, for the presence of uORFs in the leader sequences upstream their mORFs.
Previous studies have demonstrated that uORFs regulate mRNA translation and repress the translation of the downstream mORFs (Wang and Wessler, 1998; Bailey-Serres, 1999; Locatelli et al., 2002; Wiese et al., 2004). Recent analysis of 5′-UTRs of plant genes has demonstrated that about 20% of 5′-UTRs contain AUG triplets, and in some cases, these AUG triplets are associated with uORFs (Kochetov et al., 2002). The fact that short ORFs are found in the leader sequences of all type 1 transcripts and type 2 transcripts in rice suggests that a uORF-regulating-mechanism may also be involved in the translational regulation, which needs to be further elucidated.
Through alternative splicing, AtMYB59 and AtMYB48 will be able to encode MYB proteins with one or two MYB repeats, which are known to bind DNA. The putative type 1, 2, and 3 MYB proteins encoded by AtMYB59 and AtMYB48 differ only in their MYB repeats. Therefore, these three types of MYB proteins may have binding affinities to different target genes. In Arabidopsis, both type 2 and 3 proteins, but not the type 1 protein, are exclusively localized in the nucleus, and share the same activation domains as the type 1 protein. It will be interesting to study whether the difference in subcellular localization correlates with the function of these proteins. By contrast, the type 1 and 2 transcripts of rice encode the same MYB proteins, the biological importance of which also remains to be determined.
Histochemical analysis showed that the 5′-UTR is sufficient to initiate the translation of type 3 transcripts, but not type 2 transcripts. It is possible that the translation of type 2 transcripts requires the 3′-UTR, or the full-length mRNA, and may even require more translation factors and more complex mechanisms to skip the first initiator AUG. Elucidation of the mechanism behind the alternative splicing of MYB genes will not only provide information on gene evolution in monocots and dicots, but also facilitate our understanding of the regulation of MYB transcription factor genes in development.
This study was supported by National Natural Science Foundation of China (GN 30370093) and National Special Projects for R&D of Transgenic Plants (J99-A-001). We thank Professor Meihua Liu (Peking University) for her valuable suggestions on the project, and Ms Li Zhang for her technical assistance.
References
Bailey-Serres J.
Brett D, Hanke J, Lehmann G, Haase S, Delbruck S, Krueger S, Reich J, Bork P.
Brown JW, Simpson CG.
Burge CB, Padgett RA, Sharp PA.
Carrasco JL, Ancillo G, Mayda E, Vera P.
Chen Y, Yang X, He K, et al.
Dietrich RC, Incorvaia R, Padgett RA.
Grotewold E, Athma P, Peterson T.
Hall SL, Padgett RA.
Hanke J, Brett D, Zastrow I, Aydin A, Delbruck S, Lehmann G, Luft F, Reich J, Bork P.
Hardtke CS, Berleth T.
Horstmann S, Ferrari S, Klempnauer KH.
International Human Genome Sequencing Consortium.
Jefferson RA, Kavanagh TA, Bevan MW.
Jiang C, Gu X, Peterson T.
Kazan K.
Kochetov AV, Syrnik OA, Rogozin IB, Glazko GV, Komarova ML, Shumnyi VK.
Kozak M.
Larsen LK, Amri EZ, Mandrup S, Pacot C, Kristiansen K.
Lee TH, Kim SJ, Kang SW, Lee KK, Rhee SG, Yu DY.
Levine A, Durbin R.
Lewandowska D, Simpson CG, Clark GP, Jennings NS, Barciszewska-Pacak M, Lin CF, Makalowski W, Brown JW, Jarmolowski A.
Locatelli F, Magnani E, Vighi C, Lanzanova C, Coraggio I.
Lorkovic ZJ, Wieczorek Kirk DA, Lambermon MH, Filipowicz W.
Macknight R, Bancroft I, Page T, et al.
Magaraggia F, Solinas G, Valle G, Giovinazzo G, Coraggio I.
Rosinski JA, Atchley WR.
Shen-Ong GL.
Stracke R, Werber M, Weisshaar B.
Thompson JD, Higgins DG, Gibson TJ.
Wang L, Wessler SR.
Wiese A, Elzinga N, Wobbes B, Smeekens S.
Wu Q, Krainer AR.
Yi L, Qu LJ, Chang S, Su Y, Gu H, Chen Z.
Zhou Y, Zhou C, Ye L, Dong J, Xu H, Cai L, Zhang L, Wei L.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments