
Regional fresh snowfall microbiology and chemistry are driven by geography in storm-tracked events, Colorado, USA
- Published
- Accepted
- Received
- Academic Editor
- Bruno Marino
- Subject Areas
- Ecosystem Science, Microbiology, Molecular Biology, Biosphere Interactions, Atmospheric Chemistry
- Keywords
- Aerosols, Aerosol chemistry, Microbial ecology, Remote sensing, Snow
- Copyright
- © 2018 Honeyman et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2018. Regional fresh snowfall microbiology and chemistry are driven by geography in storm-tracked events, Colorado, USA. PeerJ 6:e5961 https://doi.org/10.7717/peerj.5961
Abstract
Snowfall is a global phenomenon highly integrated with hydrology and ecology. Forays into studying bioaerosols and their dependence on aeolian movement are largely constrained to either precipitation-independent analyses or in silico models. Though snowpack and glacial microbiological studies have been conducted, little is known about the biological component of meteoric snow. Through culture-independent phylogenetic and geochemical analyses, we show that the geographical location at which snow precipitates determines snowfall’s geochemical and microbiological composition. Storm-tracking, furthermore, can be used as a valuable environmental indicator to trace down what factors are influencing bioaerosols. We estimate annual aeolian snowfall deposits of up to ∼10 kg of bacterial/archaeal biomass per hectare along our study area of the eastern Front Range in Colorado. The dominant kinds of microbiota captured in an analysis of seven snow events at two different locations, one urban, one rural, across the winter of 2016/2017 included phyla Proteobacteria, Bacteroidetes, Firmicutes, and Acidobacteria, though a multitude of different kinds of organisms were found in both. Taxonomically, Bacteroidetes were more abundant in Golden (urban plain) snow while Proteobacteria were more common in Sunshine (rural mountain) samples. Chemically, Golden snowfall was positively correlated with some metals and anions. The work also hints at better informing the “everything is everywhere” hypotheses of the microbial world and that atmospheric transport of microbiota is not only common, but is capable of disseminating vast amounts of microbiota of different physiologies and genetics that then affect ecosystems globally. Snowfall, we conclude, is a significant repository of microbiological material with strong implications for both ecosystem genetic flux and general bio-aerosol theory.
Introduction
Throughout temperate and polar regions of the world, snowfall is ubiquitous. Specifically, along the Front Range of eastern Colorado, the mean annual snowfall from 2010 to 2016 is reported as 248 cm in Boulder, Colorado (NOAA, 2017). Despite snow’s prevalence, little is known about the biological composition of this massive annual hydrological deposit; meteoric snow is an essential part of yearly moisture input in Boulder, Colorado given that it represents 43% of the total precipitation (by liquid water volume) from 2010 to 2016 (NOAA, 2017). Both snow and rain require an initiation surface for atmospheric water to condense into a droplet of water or ice particle, respectively. Typically, these are thought to be airborne particles of particulate matter, both organic and inorganic of various colloidal sizes (e.g., 0.5–8 μm) (Twomey & Squires, 1959; Nakaya, 2017). Bioaerosols, defined as particles of a biological nature released from both terrestrial and marine ecosystems into the receiving atmosphere, are considered to be capable of acting as initiation surfaces (Maki et al., 1974). Recently, bioaerosols have also been suggested as an understudied component of both atmospheric processes and biogeographical fate (Morris et al., 2011).
Bioaerosols are most famous for their potential detrimental effects upon human health from contaminated indoor or other built-environments (e.g., mold and fungal spores) (Garrett et al., 1998). However, even in a benign, typical, outdoor/atmospheric environment, bioaerosols are common and the literature reports source environments (Bowers et al., 2011), seasonal effects (Wright, Greene & Paulus, 1969; Bowers et al., 2012), and diurnal shifts (Tong & Lighthart, 1999) as factors in atmospheric bioaerosol composition. Furthermore, bioaerosols are known to be components of the estimated three Pg annual dust traffic around the globe (Griffin et al., 2001; Cakmur et al., 2006; Hallar et al., 2011). Work has approached the theory that bioaersols are important to climate as a whole (Morris, Leyronas & Nicot, 2014) by examining in silico models of microbiological dispersion in the atmosphere (Burrows et al., 2009). With respect to precipitation, the effects of rainfall additions to soil communities has already been shown to be of microbiological community significance at the soil/atmosphere interface (Gravuer & Eskelinen, 2017). Additionally, these works suggest that snowfall, in particular, is even more important in the deposition of some strains of ice-nucleating (IN) bacteria Pseudomonas syringae (also a plant pathogen) (Monteil, Bardin & Morris, 2014)—from which the man-made snow-making additive Snomax™ derives (Snomax, 2018). In vivo studies of both atmospheric (suspended as an aerosol) and hail (within the hailstone) microorganisms have shown them to be metabolically active (Sattler, Puxbaum & Psenner, 2001; Ariya et al., 2002; Amato et al., 2007a, 2007c; Temkiv et al., 2012), suggesting that the biomass in the environment from which snowfall derives is not of inconsequence and that microbiota can remain metabolically active throughout the rain/ice/snow nucleation process. Save for some work on liquid precipitation (Hiraoka et al., 2017), what microbiota within ice/snow look like when they contact soil and surface receiving waters remains unknown. Beyond the community structure of precipitation microbiota, it is especially unknown how these structures changes as a result of geography and atmospheric events.
Bioaerosol literature, in general, is best represented by reports of in silico bioaerosol movement, aerosol microbial composition and studies of canonical surface constituents such as glaciers and snowpack (Carpenter, Lin & Capone, 2000; Amato et al., 2007b; Liu et al., 2011; Harding et al., 2011; Carey et al., 2018). There exists little specific information, however, on the microbiology of snowfall precipitation. The biological composition of snowfall—a global meteorological event—should be well understood vis-à-vis magnitude and community structure, especially given that precipitation is key to uncovering atmospheric/surface interactions. An aid to such study is the preponderance of weather information available that tracks storm events in multiple-spectral analyses; these data further inform storm/biome/hydrology source locations.
To this end, we sampled fresh snowfall throughout the entirety of the 2016–2017 snow season (snow seasons are typically October–May) along the Front Range of eastern Colorado. Our investigations include disparate sampling sites (one rural mountain, and one urban plain) to help in the characterization of snowfall with respect to both sampling location—within the same storm—and direction of origin of the storm. We hypothesized that the biological content of fresh snowfall would be uniquely distinguishable with respect to sampling location and that storm tracking could provide novel insight into other factors that may affect biogeography. Here, we apply ecological investigative approaches together with remote sensing based atmospheric storm analyses to assess the magnitude of biological deposition, community structure, and abiotic solute associations in fresh snowfall.
Methods
Sample collection
Over the course of the 2016–2017 snow season, fresh snowfall samples were collected from two locations along the Front Range of eastern Colorado. Only storms with appreciable accumulation were sampled (≥12 cm) and these storms generally occurred over the course of either an entire night or entire day. One sampling location was a rural setting (Sunshine, CO; latitude 40°3′38.2422″, longitude −105°21′56.5596″, elevation 2,164 m) and the other more urban/suburban (Golden, CO; latitude 39°45′7.0704″, longitude −105°13′28.632″, elevation 1,730 m). While many roads and ample human traffic were near exact sample collection locations in Golden, CO, care was taken to avoid sampling where obvious road spray could occur or material from above could fall down. In Sunshine, CO, exact sample collection sites were distant from any roadways or other non-natural contaminant sources. Throughout the snowfall season, seven snowstorms were sampled. Three of the storms yielded snow at both locations, allowing paired sampling of the storm on the same day. Snow collections were conducted either the evening of a day storm, or the morning after a night storm. Sealed, unopened, Ziploc™ bags were used to remove the top ∼5–8 cm of accumulated snow at each sampling event. Typically, four one-gallon (3.8 L) bags of snow were collected per sampling event, with the bags contacting neither hands, nor ground beneath the fresh snowfall. When sampling a storm, either there was no prior ground accumulation, or snow was only sampled modestly from the top layer, leaving many inches between the sampling scoop and snowfall from a previous storm. Snow in sample bags was kept frozen with wet ice during transport, and at −20 °C during storage. Immediately prior to filtering, snow samples were thawed within their sealed bags via heated water (65 °C) over 10 min; under this thawing protocol melted snow water could not exceed 0 °C until all snow was melted, at which point the bags were removed from the heated water. Using a sterile 0.45 μm 500 mL Autofil PES Bottle Top vacuum filter cup with lid (Foxx Life Sciences, Salem, NH, USA), thawed snow samples were filtered. 0.45-μm filters were chosen to avoid plugging during filtration due to the bulky nature of particles collected (i.e., Fig. 1D). Filtrate was collected into autoclaved one L glass bottles. Filter papers were sectioned into quadrants, with three used as technical replicates for DNA extraction, and one used for imaging. All quadrants were frozen at −20 °C until further processing. As a control for the filtering process, one additional one-gallon bag of snow was collected on April 04, 2017 from Sunshine, autoclaved twice at 121 °C and 15 PSI for 30 min in a glass bottle, and then filtered and processed the same as other samples.

Figure 1: Filtered snow microscopy.
Phase contrast (A and B) and ESEM (C and D) imaging of one quadrant of the filter paper that was used for the snowstorm on January 04, 2017. (B) and (D) are the filter paper from filtered Golden snow while (A) and (C) show filtered material from Sunshine. All filter papers are rated to capture 0.45 μm, and greater, particles.{kind=link}
Microscopy
Filter paper quadrants from each sample were imaged on both a Hitachi TM-1000 (Hitachi High Technologies in America, Schaumburg, IL, USA) environmental scanning electron microscope equipped with a Bruker (Billerica, MA, USA) electron dispersive spectroscopy detector as well as an Olympus CX41 phase contrast microscope (Olympus Corporation, Center Valley, PA, USA) equipped with an Infinity 2 camera and Infinity Analyze software (Lumenera Corporation, Ottawa, ON, USA).
Storm tracking
Snow storms associated with sample collection were tracked with the NOAA ARL (Air Resource Laboratory) HYSPLIT Trajectory Model (Draxier & Hess, 1998; Stein et al., 2015). A trajectory ensemble was generated for each storm by creating a set of tracking vectors centered about the latitude and longitude of each sampling site. Models are backward trajectories and encapsulate storm tracking up to 24 h prior to the day of the snow storm event. Backward trajectories began at 500 m AGL (above ground level) from sampling sites.
Geochemistry
Filtrate from melted snow (0.45-μm pore size) was subsampled to two 15 mL aliquots for ion chromatography (IC; major anions) and inductively coupled plasma atomic emission spectrometry (ICP-AES; major cations) analysis. ICP-AES samples were acidified with three drops of trace metal grade 10% nitric acid. IC analysis was performed on a Dionex ICS-900 IC system running an AG14A-5 μm RFIC (3 × 30 mm) guard column and an AS14A-5 μm RFIC (3 × 150 mm) column, while ICP-AES was performed on a Perkin–Elmer 8300 ICP-AES.
DNA extraction
The ZymoBIOMICS DNA Mini Kit (Zymo Research, Irvine, CA, USA) was used according to manufacturer instructions for DNA extractions. Input into the extraction process was one quadrant of a 0.45-μm filter (quadrants described in “Sample collection”). For every set of extractions conducted, an extraction blank (a DNA extraction conducted with no sample input) was also processed. A single sample replicate from Golden taken on November 17, 2016 was removed from all downstream analyses due to microcentrifuge tube failure.
Quantitative PCR and DNA sequencing
To quantify the abundance of Bacteria and Archaea in the snow samples, LightCycler 480 SYBR Green I Master quantitative PCR (qPCR) mix (Roche, Indianapolis, IN, USA) was used in conjunction with 16S rRNA V4-5 region primers (Rudi et al., 1997; Engelbrektson et al., 2010). Genomic DNA (gDNA) from Escherichia coli strain JM109 was used as a standard from a Femto Bacterial Quantification Kit (Zymo Research, Irvine, CA, USA) to calibrate amplification curves; seven standards, in addition to a no-template (negative) control (NTC), ranged from 2 × 10−5 to 20 ng of DNA per reaction well. qPCR reaction volumes were 20 μL of 1× Master Mix, 0.2 μM 334F (CCA GAC TCC TAC GGG AGG CAG C), 0.2 μM 519R (GWA TTA CCG CGG CKG CTG), and 2 μL volume of template DNA. Amplification was conducted in technical triplicate with a LightCycler 480 II (Roche, Indianapolis, IN, USA). LightCycler amplification parameters were as follows: initial denaturation at 95 °C for 5 min (4.4 °C s−1), 40 cycles of 95 °C for 30 s (4.4 °C s−1) then 53 °C for 30 s (2.2 °C s−1) and 72 °C for 30 s (4.4 °C s−1), final extension of 72 °C for 5 min (4.4 °C s−1). At least one filter replicate from all samples amplified a minimum of two qPCR cycles before negative controls; all filter replicates were used for each sample in downstream analyses. (We are unable to include the December 7, 2016 Sunshine sample in DNA per volume calculations because we do not have data on the volume of melted water resulting from filtering four one-gallon (3.8 L) bags of snow.)
DNA sequencing was performed on an Illumina MiSeq (Illumina Inc., San Diego, CA, USA) at the Duke Center for Genomic and Computational Biology using V2 PE250 chemistry. Initial sample 16S/18S rRNA PCR amplification was performed in duplicate 25 μL reactions as follows: 1× QuantaBio 5PRIME HotMasterMix, 0.2 μM 515-Y Forward Primer (5′-GTA AAA CGA CGG CCA GT CCG TGY CAG CMG CCG CGG TAA-3′) where the M13 forward primer (underlined) is ligated to the small sub-unit RNA specific sequence via a “CC” spacer, 0.2 μM 926R (5′-CCG YCA ATT YMT TTR AGT TT-3′) reverse primer and template DNA. Reverse primers were as reported by Parada, Needham & Fuhrman (2016) while forward primers were adapted from Parada et al. with the addition of the M13 sequence, as done by Stamps et al. (2016). Primers from Parada, Needham & Fuhrman (2016) target all three domains of life. PCR was performed on a Techne TC-5000 with the following parameters: initial denaturation at 98 °C for 30 s, followed by 30 cycles of 98 °C for 10 s then 52 °C for 20 s and 72 °C for 10 s, with a final extension of 72 °C for 5 min and a 10 °C hold. A second, six cycle, PCR amplification step with the parameters used in the first amplification step was used to ligate barcodes adapted from Caporaso et al. (2012) to the M13 region of the forward primer (Stamps et al., 2016). PCR product cleanup was performed with 0.8× concentration of KAPA Pure Beads (Kapa Biosystems, Indianapolis, IN, USA) according to the manufacturer’s specifications.
Sequence analysis
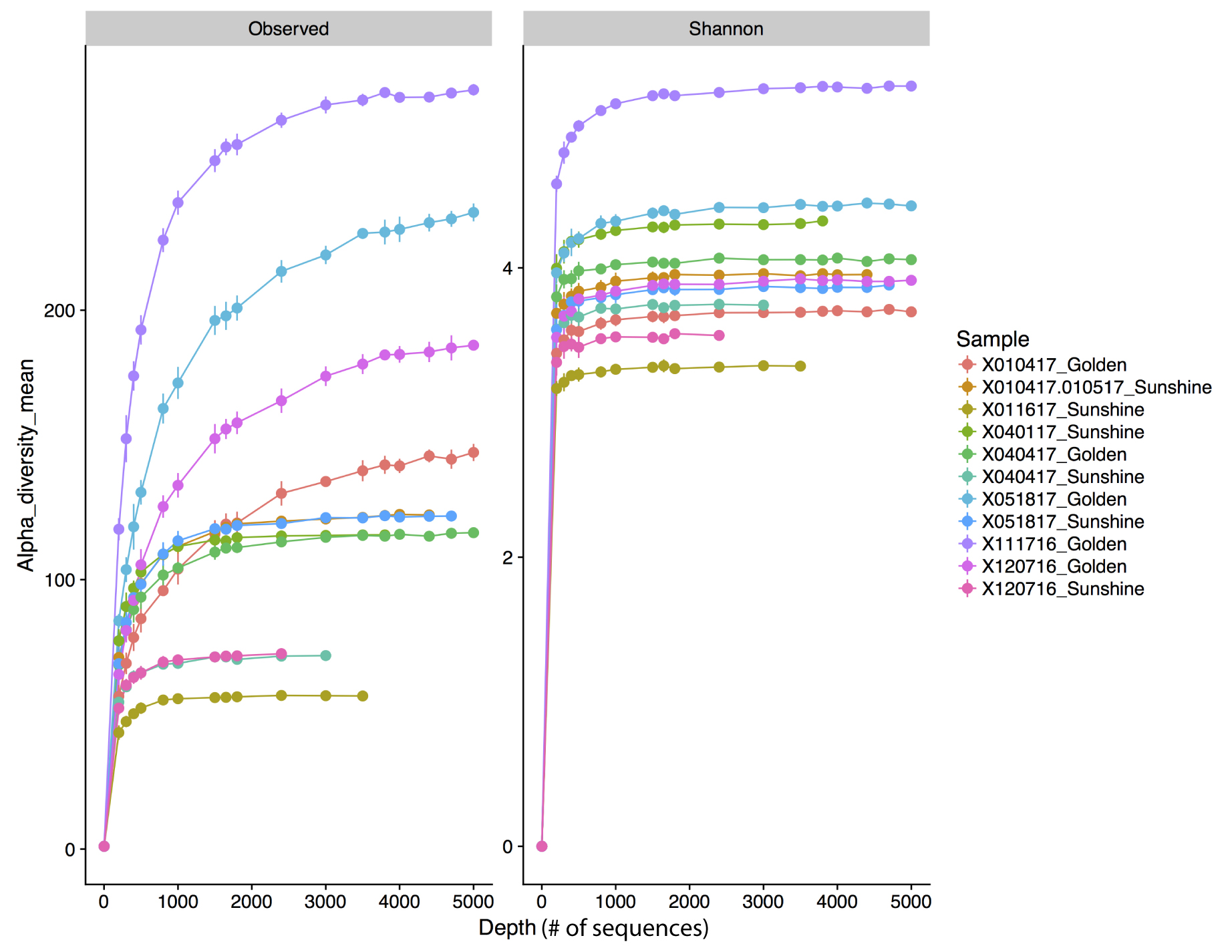
DADA2 (Callahan et al., 2016) was used to trim sequences, infer sample composition (via DADA2’s true sequence determination algorithm, Callahan et al., 2016), merge Illumina paired-end reads, construct a sequence table (simply a list of all “true” unique sequences called by DADA2), and remove chimeric sequences. In sum, final “true” unique sequences called by DADA2 are operational taxonomic units (OTUs) clustered at 100% similarity (Callahan et al., 2016). Initial trimming of initial, raw, sequences involved excising forward and reverse primer sequences; for example, 40 leading bases were removed from forward reads and 20 leading bases were removed from reverse reads, resulting in final lengths of 199 bases for forward reads and 231 bases for reverse reads. In total of 252,596 unique forward reads and 252,596 unique reverse reads were denoised to 146,797 and 152,739 “true” unique reads, respectively, via DADA2. We recover similar proportions of “true” unique sequences as the DADA2 demonstration pipeline of Callahan et al. Technical replicates from each sample were pooled into one object and analyzed together; these pooled samples will be referred to simply as “samples” from here on. Samples were trimmed to contain only bacterial and archaeal sequences, with chloroplast and mitochondrial sequences similarly excised. All samples were rarefied to a depth of 3,391 sequences; 3,391 was chosen because it allowed inclusion of all but one sample (December 07, 2016 Sunshine) while also retaining most of the sample diversity (Fig. S1). Downstream sequence analyses were run with multiple random subsampling sets and results were not found to change appreciably at our selected rarefaction level of 3,391 bacterial/archaeal sequences. For reproducibility, a set random start seed was used in the rarefaction process. Taxonomy assignments were called with a SILVA training file (version 128) through the DADA2 taxonomy assignment script. Phylogenetic trees were constructed with sequence alignment via Silva Incremental Aligner (v1.2.11; 90% complementarity) (Pruesse, Peplies & Glöckner, 2012) in the QIIME package (Caporaso et al., 2010). OTU tables, taxonomy tables, phylogenetic trees, and sample meta-data were compiled in the data processing phyloseq object presented by the R package “phyloseq” (McMurdie & Holmes, 2011).
Assessment of eukaryotic sequences was done via the same method as above, with the exception of merging forward and reverse Illumina reads. In a separate pipeline, all forward and reverse “true” unique reads were merged by concatenating the reads directly with a 10-Ns as the joiner. The 10-Ns serve to mark that a gap in 18S sequence exists between the forward and reverse reads; for example, while our amplicon primers (Parada, Needham & Fuhrman, 2016) amplify all three domains of life, the extended length of the 18S gene disallows overlapping of forward and reverse reads. The DADA2 taxonomy assignment script recognizes this 10-N linker and can perform taxonomy over it (Callahan et al., 2016). As in the bacterial/archaeal analysis, sequences from technical replicates were pooled to one sample. Bacterial and archaeal taxonomic assignments were removed from this dataset, leaving only 18S rRNA eukaryotic sequences. The eukaryotic sequence dataset was rarefied to 529 sequences; few eukaryotic sequences were returned in general, and rarefaction at 529 sequences therefore did not dramatically reduce the number of sequences analyzed. Like the bacterial and archaeal analysis, a set random start seed was used during rarefaction for reproducibility. Three samples were removed from the eukaryotic analysis because they were below the rarefaction threshold (two from Golden and one from Sunshine).
Results
Microscopy
Imaged filter quadrants from all samples revealed patterns that distinguish samples taken from Golden from those taken in Sunshine (Fig. 1). Substantially larger particles are captured by filtering snow from Golden than snow from Sunshine in the same storm; further, by the naked eye Golden filter papers were also markedly dirtier than their Sunshine counterparts (Photo S1). Any storm localized to Golden generally yielded more material than storms localized to Sunshine. A large number of morphologically diverse particles were collected from both locations; that is, sizes of captured matter range from just above the 0.45 μm threshold to 30 μm and greater. Cells are not visible within microscopy images, which was expected given the low concentrations of DNA recovered from filter papers.
Storm geochemistry
Ion chromatography and ICP-AES analyte results (Table S1)—where most analytes were within the zero to two ppm range—were compiled to generate a principal component analysis (PCA) (base R stats package) with individual samples as the object of ordination (Fig. 2). To reduce noise in the model, only analytes seen to have variation amongst samples were used in the ordination and these were: Cl−, NO2−, NO3−, SO42−, Ca2+ (315.887.R), K+ (766.490.R), Mg2+ (279.553.R and 285.213.R), Mnx (257.610.A), Na+ (589.592.R), S2− (180.669.A), Six (251.611.A), and Znx (213.857.A). Adjacent to the wavelengths in parentheses, “A” and “R” indicate either Axial or Radial viewing during measurement. Data were centered and scaled to unit variance. Normal ellipses (Fig. 2) show nominal clustering by sampling location. Furthermore, the arrows in Fig. 2 indicate a positive correlation of variables in the direction that they point. Except for Zn, Mn, and Si, all analyte variables correlate positively with snow collected in Golden. Principal Component 1 suggests a high chemical variance between samples collected in Golden relative to those collected in Sunshine. To assess the statistical differentiation of chemical data with respect to sampling location (independent of the PCA), a Euclidean distance matrix was constructed using the same samples and chemical data used in the chemical PCA analysis. An Adonis test was run on the Euclidean distance matrix to inspect statistical differences between Sunshine and Golden snowmelt chemistry; the two groups were found to be significantly different (R2 = 0.28, p = 0.002).
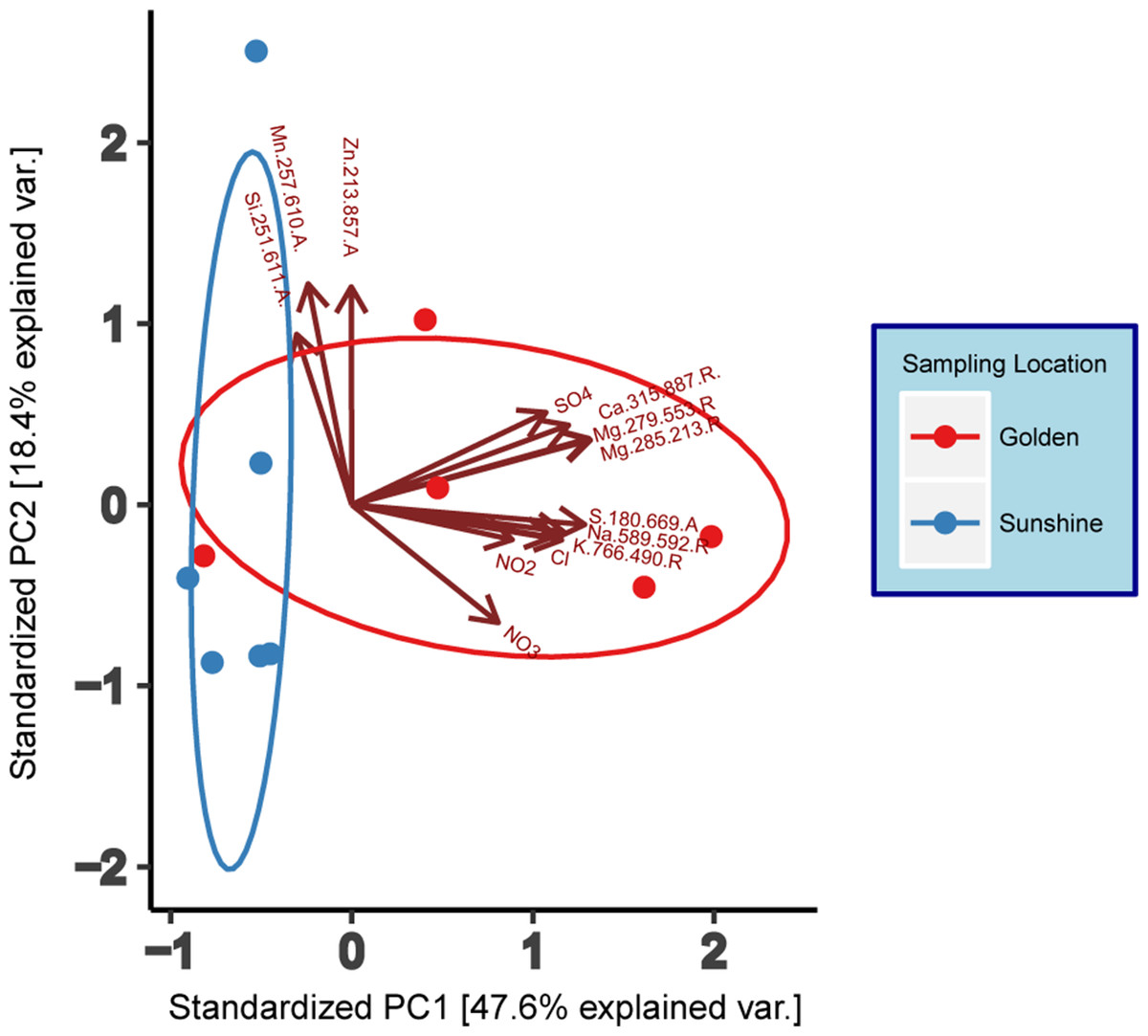
Figure 2: Principal component analysis (PCA) of geochemical data (IC/ICP-AES).
Data are grouped/colored by sampling location. Data have been centered and scaled to unit variance. Grouping ellipses are normal data ellipses constructed about data points from each sampling location.{kind=link}
Genomic yield and sample diversity
16S rRNA gene amplification via qPCR was used to estimate the amount of bacterial/archaeal gDNA extracted from each sample. DNA extracted per sample was normalized to the volume of filtrate that was yielded by the filtering process. Reported values determined by qPCR were in units of estimated nanograms of gDNA extracted per milliliter of snow filtered (Fig. 3). When possible, snow collected from the same storm in disparate locations are co-plotted and p-values from a student’s t-test reported (Fig. 3). The p-value was significant in one of the three comparisons conducted. However, snow collected from Golden generally yielded higher amounts of gDNA than snow collected from Sunshine in the same storm. Across all samples in our study, the average mass of bacterial/archaeal gDNA extracted per milliliter of snow-water filtered was 0.237 ng mL−1 (Fig. 3), which (using E. coli—∼5 fg gDNA cell−1—as a model), corresponds to a likely cell count of ∼4.7 × 104 cells mL−1 of snow melt.

Figure 3: DNA concentrations from snow.
Box plots of mean mass of gDNA extracted from replicate filter quadrants per milliliter of snow filtered. Error bars are standard errors, indicating technical variance. The dotted line represents the mean value across all samples and all snowstorms for the 2016–2017 snow season along the eastern Front Range in Colorado. Reported p-values are from a student’s t-test.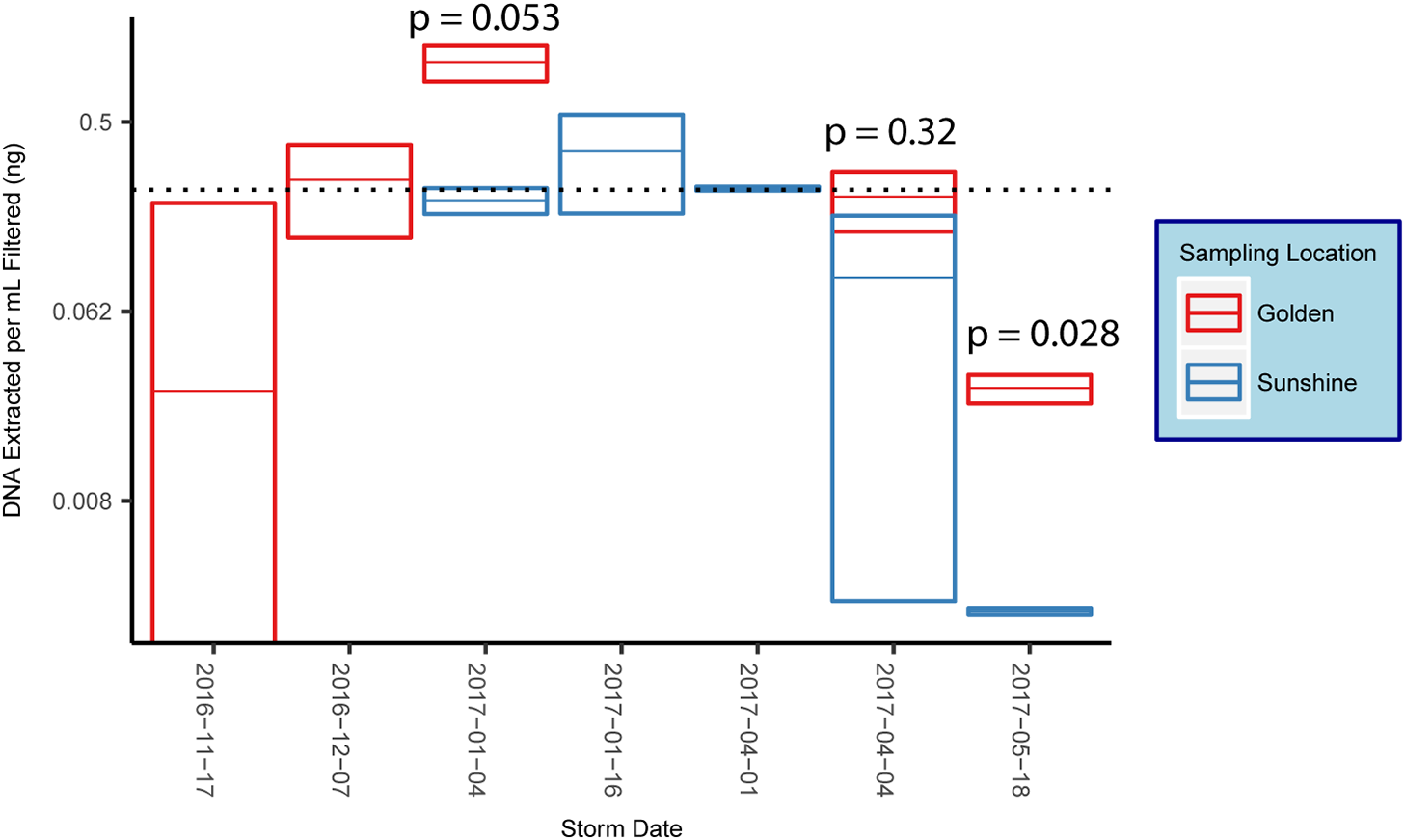{kind=link}
Post-rarefaction—to 3,391 bacterial/archaeal sequences, with one sample cut (December 07, 2016 from Sunshine) (Fig. S1)—bacterial/archaeal alpha diversities were estimated with the number of observed OTUs. The mean number of observed OTUs for Golden samples was 188.0 while the mean number seen in Sunshine was 98.4 (p = 0.032, Welch two sample t-test). While the alpha diversity of snow sampled in Golden is higher than Sunshine Canyon, the alpha diversities between different snow storm origins have insignificant p-values.
Storm tracking
NOAA HYSPLIT models were used to assess which direction the majority of storm travel vectors came from for each sampling event. Most storms were of a SW origin while two storms came from the NW and one storm was of a SE origin (a Colorado “upslope” storm). We verified from the HYSPLIT models that same-day samples from both geographic locations were in fact from the same snow storm and could be assigned the same direction of origin (Figs. S2 and S3).
Characterization of snow communities
A community ordination chart constructed from 16S rRNA data—organized by both sampling location and origin of storm—is presented; principal coordinate analysis (PCoA) suggests strong clustering by sampling location, as constructed by a weighted Unifrac distance matrix (Fig. 4) (Lozupone & Knight, 2005). An Adonis test was run on the dissimilarity matrix used for Fig. 4, and sampling locations were found to be distinct in grouping (R2 = 0.20, p = 0.033). Weighted Unifrac distance matrices were also tested by Adonis for true-differences in samples taken from different storm trajectories; no significance was detected. Snow filtering-process controls, DNA extraction controls, and no-template PCR controls amplified exponentially during qPCR a minimum of two cycles after at least one filter replicate from all samples, indicating that differences seen between samples are true biological differences. Filtering-process controls, furthermore, were ordinated against true samples and found to be distinct in clustering (control data are viewable as a relative abundance heatmap, Fig. S5).
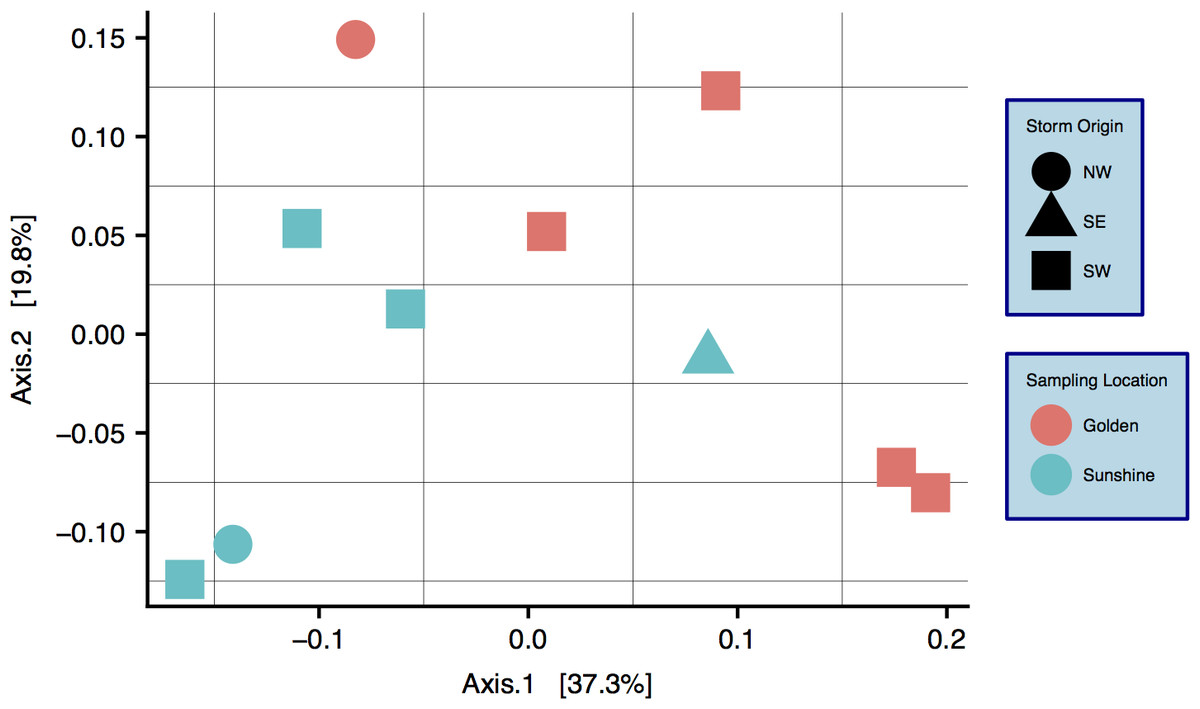
Figure 4: Principal coordinate analysis (PCoA) of weighted Unifrac distances between samples.
Colors are by sampling location and shapes are by origin of storm. Differences between samples with respect to sampling location are significant: R2 = 0.20, p = 0.033 (Adonis test).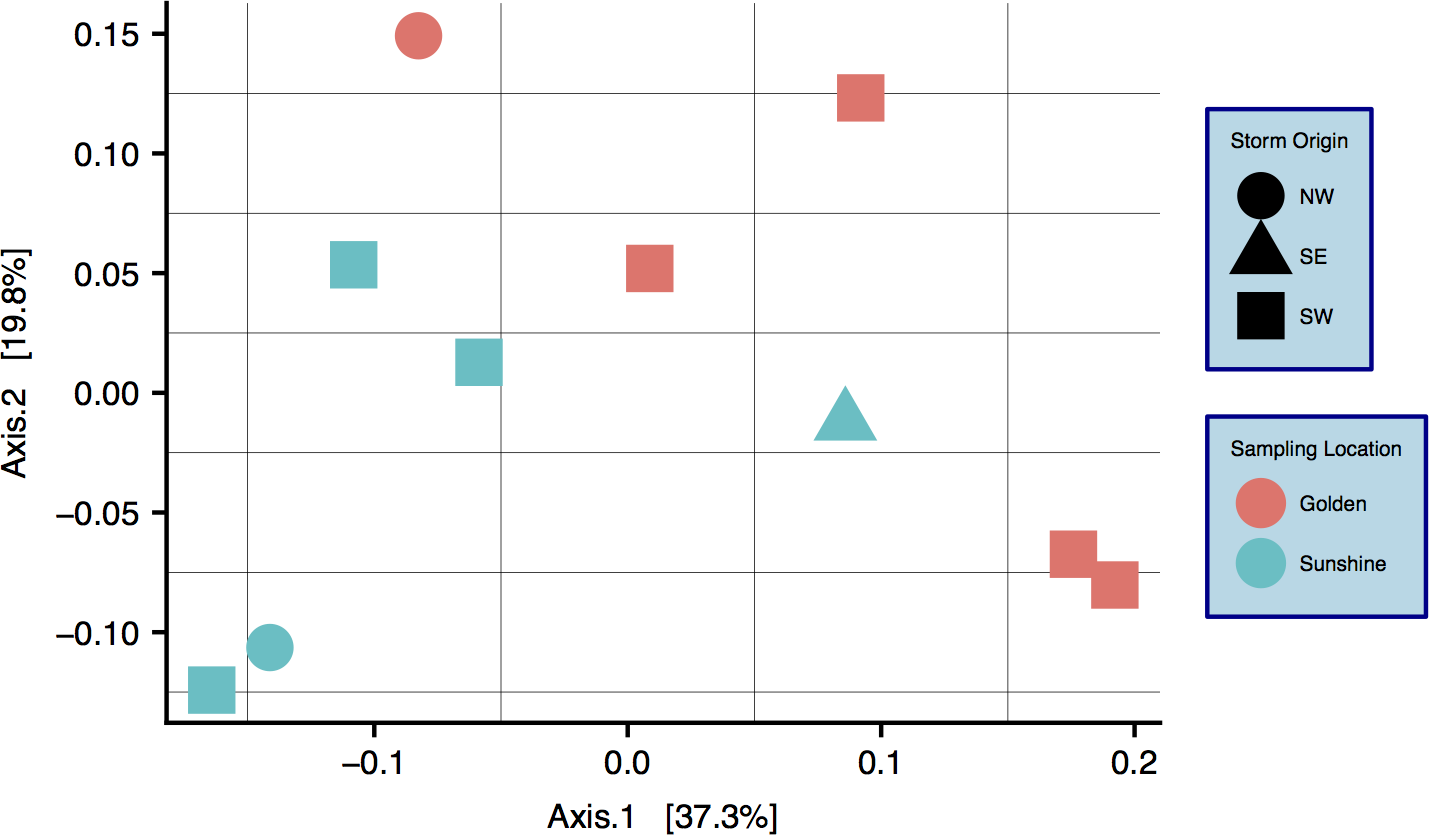{kind=link}
Snowstorms from both sampling locations display a wide range of bacterial/archaeal (Fig. S4A) and eukaryotic (Fig. S4B) taxa. At the phylum level, Bacteroidetes are most common in snow sampled from Golden while Proteobacteria are most abundant in Sunshine samples, this in a linear distance difference of only 36.4 km. At all taxonomic ranks, there are distinguishable differences in community composition between the two geographic locations. By use of SIMPER (vegan R package) (Oksanen et al., 2017), the taxa from each taxonomic rank most responsible for the Bray–Curtis distance between samples were determined. Plotted in descending order of contribution, we demonstrate how any taxonomic rank is sufficient to differentiate the two sampling locations (Fig. 5). The top-10 most mathematically influential genera in differentiating sample locations were pulled from the SIMPER analysis, and are shown in Table 1 along with their % contribution to the total difference. The abundances of these genera are examined from both sampling locations as well as the control from the filtering process to assess contamination; no contamination is suspected (Fig. S5). For each of the top 10 most influential genera (Table 1), the OTU that had the highest abundance in each genus bin was searched with MegaBLAST (Morgulis et al., 2008) for highly similar sequences within the 16S rRNA sequence database from NCBI. For each sequence searched by MegaBLAST, the most highly similar sequence with information on source was summarized: genera found more frequently in Golden were associated with soil, horse dung, airborne dust, hard water, and clinical isolates (Busse, 2003; Gallego, 2006; Kampfer, 2006; Muurholm et al., 2007; Smet et al., 2014); genera common to Sunshine are reported in swimming pool water, clinical material, cultivated land, and may be spore forming (An et al., 2007; Furuhata et al., 2013; Amend et al., 2015; Echahidi et al., 2015; Im et al., 2015). Though Adonis showed no significant difference between samples with different storm-origins via the weighted Unifrac distance, there are obvious taxonomic differences between storm trajectories (Fig. S6).

Figure 5: Taxonomic-rank contributions to geographic differences.
The y-axis shows cumulative contribution to the total Bray–Curtis distance between geographic locations. The x-axis indicates the top “X%” most influential taxa within each bin that contribute to Bray–Curtis differences between geographic locations (determined via SIMPER analysis). The dotted gray line indicates what curves would look like if no particular taxa contributed to differences more than others.{kind=link}
| Genus | % Contribution to distance | Location with higher abundance |
|---|---|---|
| Chryseobacterium | 8.3 | Golden |
| Acinetobacter | 5.2 | Golden |
| Unknown | 4.2 | Sunshine |
| Bacillus | 4.1 | Sunshine |
| Sphingomonas | 3.8 | Golden |
| Porphyrobacter | 2.7 | Sunshine |
| Flavisolibacter | 2.7 | Sunshine |
| Staphylococcus | 2.5 | Sunshine |
| Segetibacter | 2.3 | Sunshine |
| Pedobacter | 2.1 | Golden |
Note:
The top-10 most influential genera in the biological differentiation of snowfall between geographic locations. SIMPER was used to determine the influence of each genus on the total Bray–Curtis difference between Sunshine and Golden samples. A total of 279 genera were identifiable by SILVA in fresh snowfall.
Few eukaryotic sequences were recovered relative to the abundance of bacterial and archaeal sequences found in snowfall; prior to rarefaction, 6.2% of the total number of sequences recovered were of eukaryotic taxonomy. Of those eukaryotic sequences recovered and classified, the two fungal phyla Ascomycota and Basidiomycota were clearly most common. Similar to the results presented from bacterial and archaeal sequences, the two dominant eukaryotic phyla display differential relative abundance with respect to both sampling location and the origin of snowstorms (Figs. S4B and S5B).
Discussion
Snowfall is endemic to the seasonal cycle in both temperate and polar regions of the world. By contributing to aquifers, this form of precipitation is a critical component of both local and global hydrologic systems. Here, we have presented a diversified approach to understanding the biology of meteoric snow, leveraging atmospheric phenomena as a means to determine significant affecters of biogeography. By targeting fresh snow deposits at two geographic locations 36.4 km apart, we were able to simultaneously address geographic effects within a storm swath as well as inter-storm effects at either location. While just a subset of all of the storms could be sampled at both locations, our data set comprises the entirety of one winter season in Colorado. Though storms do not always precipitate in both Golden and Sunshine, we sampled every storm of opportunity with enough snow (e.g., ≥12 cm); thus, our study is as robust as the 2016–2017 winter allowed. In our investigation, we have targeted the magnitude and community composition of meteoric snow as important first-steps in uncovering the importance of these fresh deposits to biogeography and the hydrologic cycle. Concerning magnitude, our data show that an average of 0.237 ng of bacterial/archaeal gDNA can be recovered per milliliter of fresh snowfall (melted and filtered), which is a value unreported in the literature. Our yields of DNA from snowfall are similar to, or greater than, what other groups have reported from snowpack (Carpenter, Lin & Capone, 2000; Sattler, Puxbaum & Psenner, 2001; Amato et al., 2007b), but we suggest that the annual persistence of meteoric snow coupled with massive land coverage yields a substantial amount of microbiological input to surface ecosystems. These deposited microbiota also generate an influx of genetic material to receiving systems. The mean annual snowfall that occurred in Boulder, CO (NOAA, Boulder, CO, USA) during 2010–2016 was 248.2 cm (NOAA, 2017). This value, coupled with dimensional analysis, shows that given the mean bacterial/archaeal gDNA recovery that we report (0.237 ng mL−1 of snowmelt; ∼4.7 × 104 cells mL−1), a season-average conversion of snow volume to water volume (10:1, NOAA, Boulder, CO, USA) (NOAA, 2017), and a representative genome mass from E. coli (5 fg cell−1), there are large biological depositions from snow computed for small areas: ∼1 × 1014 bacterial/archaeal cells are deposited hectare−1 year−1. If one is to estimate the average mass of a bacterial/archaeal cell in our samples as 0.1 ng (a rough abundance-weighted average of the masses of bacterial/archaeal cells we identified taxonomically—including the large cyanobacteria) (Portillo et al., 2013), ∼10 kg of bacteria/archaea are deposited hectare−1 year−1. Though this annual deposition of cells is calculated via multiple variables with internal variance (especially when estimating average cell mass), it is concomitantly noted that what we are able to recover through a 0.45-μm filter is likely an underestimation of what biological material exists. Microbiota captured on a filter, additionally, does not account for additional biomass that may have lysed during the thawing of our snow samples prior to filtering and/or the organisms, for example, nano-archaeota and bacteria (as well as viruses; Reche et al., 2018) that pass through a 0.45-μm filter. Many eukaryotic sequences were also obtained from our samples. Though we do not have qPCR data on eukarya in fresh snow, this additional biomass (6.2% of all sequences)—known to be legitimate eukaryotic amplification by our primers (Parada, Needham & Fuhrman, 2016)—is likely to contribute substantially to the total biomass contained in snowfall. Thus, 10 kg of biomass deposited hectare−1 year−1 is likely an underestimate. In addition, this estimate ignores the mass of all abiotic particulate matter (Fig. 1) trafficked as part of the same snow event—a mass that is much more substantial than microbial elements alone and, similarly, is deposited perennially over large swaths of land.
Herein, we have chosen to use the total estimated biomass of annual snowfall over more traditional measures like copy numbers of 16S rRNA because we believe that it is a more tractable unit when assessing large-scale mass transport and deposition. It is our assessment that the importance of our work is best demonstrated by the surprising bio- load of meteoric snow (and its associated genetic bank)—and that whether total estimated cell count or total biomass is the unit of discussion (both of which we report) is tangential to the overall finding that microbiota and their genomes are a substantial component of fresh snowfall.
Since we show significant differences between snowfall communities with respect to geography (Fig. 4), we posit that snow depositions bear significant ecological consequences—especially given that we demonstrate the mass of any particular snow event to be non-trivial (Fig. 3). At all taxonomic ranks, we show that just a fraction of taxa are responsible for differentiating geographic locations (Fig. 5). To the point of “fingerprinting” snowstorms to evaluate how different depositions may be affecting an area ecologically, it is important to identify specific taxonomic groups that are responsible for separations on distance matrices and ordinations (Table 1). We can infer from Table 1 that, even at the genus taxonomic rank, specific taxa contribute heavily to geographic differences in fresh snowfall. Furthermore, these genera are not contamination (Fig. S5), indicating that real biological differences can be identified geographically in non-general terms. Of the influential genera (e.g., genera mathematically responsible for differentiation of geographies via SIMPER), sequences that are more abundant in Golden (searched by MegaBLAST—”Results”) are highly similar to some sequences that are associated with the human built environment/urban areas (i.e., horse dung and clinical isolates). Mathematically influential sequences from Sunshine, similarly, are highly similar to what is found in rural settings (genera isolated from cultivated land); one of the sequences more common in Sunshine is also highly similar to known spore-formers, suggesting that resilience to colder temperatures experienced in-transit to a higher elevation than Golden may have been beneficial to survival. Though we caution too much extrapolation from the presence of just a few genera, we think it is fair to suggest that demonstrated differences between Sunshine and Golden are the result of environmental/physical differences between the two geographic sites—and may implicate urban/rural lines in anthropogenic bioaerosol-sourcing. In a seasonal analysis of precipitation (predominately liquid, only one snow sample) in the Greater Tokyo Area, Japan, Hiraoka et al. (2017) report similar abundant phyla within their samples (e.g., Proteobacteria, Bacteroidetes, and Firmicutes—but more Actinobacteria than we report). Interestingly, Hiraoka et al. saw few differences between sampling sites relative to the geographic differences that we see. They also witness seasonal differences that are more obvious given the lesser influence of sampling location. In light of their work as compared to ours, it’s possible that the Greater Tokyo Area, Japan can be broadly classified as “urban,” which would minimize geographic effects in an already homogenized microbial population. Just as humans contribute to built-environment bioaerosols (Fan et al., 2017), it’s possible that the scope of anthropogenic bioaerosol effects should be extended to the atmosphere. Our control data, furthermore, strongly suggest that these differences are real, and not a product of contaminating genera found in either sample group (Fig. S5). Not only do our data show that different geographic regions cycle/receive distinct biology, but they also indicate that storm trajectories will be an essential metric to assess in future studies. Although we do not show demonstrable significance in the microbiological differences between storm trajectories, storm-track is still likely a contributing component of the variance between samples (Fig. S6). Even with strong evidence that geography drives differences in microbial communities, we note that the two axes from our PCoA represent less than 60% of the total variance seen between samples. Our investigation of storm-track influence on community composition is likely hindered by sample size; that is, amongst the 10 samples profiled, only three of them were not of a SW origin. Overall, our hypothesis that the biotic components of fresh snowfall are distinguishable by geography is confirmed. To the point of meteorological information as predictive data in future studies, storm tracks should not be ignored amongst the list of affecters of microbial community composition. With ongoing collection of snow from more storms and winters, storm tracks could be forensically investigated by an analysis of their surface-deposited microbiota in snows, as well as the ices that result from snows in/on permanent snow fields and glaciers.
Bowers et al. (2011) show that air mass microbiological features were likely derived from the land beneath. We extend this finding by showing that geography also appears to have community effects on snowfall deposition. We, however, further posit that biological ice-nucleation in the atmosphere (Christner et al., 2008b; Pandey et al., 2016) may be a selection event influential enough to differentiate microbial communities even more than air masses do at any given geography. Thus, snowfall provides definitive access to surface receiving systems whereas air masses may not be as capable of moving large amounts of material between the atmosphere/lithosphere/hydrosphere. Irrespective of known high-temperature IN bacteria like Pseudomonas genera, other bacterial communities may affect low-temperature cloud glaciation (Mortazavi, Hayes & Ariya, 2008). If we assume that microbiota deposited by snowfall were either directly part of the nucleation process—or indirectly accumulated along the way—then snow depositions could be just a subset of the total aerosol microbial population. Aerosol microbiota and cloud thermodynamics are clearly linked given that different cloud chemistries determine what bacterial species act as nucleation points, and whether snow forms at all (Borys, Hindman & DeMott, 1988; Rosenfeld, 2000). In light of our study, microbial communities should still be considered an important part of the total air mass that affects cloud formation potential and the precipitation nucleation process. Though it is known that high-temperature INs are ubiquitous in precipitation (Christner et al., 2008a), our work demonstrates that the vast majority of microbiota in fresh snowfall (with putative sizes ≥0.45 μm) are not of the high-temperature nucleating genera. More attention should be given to total bacterial communities in precipitation due to the magnitude of their abundance, potential for terrestrial impact, likely effects on cloud glaciation, and non-uniform patterns of deposition in snowstorm events (Fig. 4). We know that bacteria/archaea/eucarya can be viable in aerosols (Dybwad & Skogan, 2017), suggesting that the multitude of taxa that we find in snow may be contributing to atmospheric chemistry in situ around Earth. Given all of the bio-physical/chemical influences on the atmosphere, bio-precipitation should be considered just as complex and variable—and storm-track should be considered an essential component of this variance. Furthermore, it is important that urban/rural areas receive entirely different inputs in the same snowstorm—and especially so given the large mass of these annual deposits. This could have relevance to overall air quality and human health in such storm events.
Bio-aerosols are known components of human-associated dust particle traffic (Hallar et al., 2011), and dust has complicated snowmelt and ecosystem function (Painter et al., 2007; Neff et al., 2008). Our work shows that high annual flux of genetic material and biomass via snowstorms is non-homogenous. We can immediately suggest that human activity in urbanized areas could be a source of both the biological and geochemical differences witnessed in snow relative to rural mountain collection sites. Western regions of Colorado—the mountains—are less developed than the areas surrounding the greater Denver metropolitan area; that is, the population density of Jefferson County (Golden samples) is roughly 70% greater than Boulder County (Sunshine samples) (Colorado Department of Local Affairs, 2017). Nonetheless, some similarities exist between the microbiology we found in fresh snowfall and taxa found by Amato et al. (2007c) in the water phase of tropospheric clouds. Though several factors appear to influence the microbiological composition of snowstorms, a large contributor may be whether or not a certain bacterium is able to remain viable at low temperatures within a cloud, both low- and high- altitude. Community differences in snowfall between storm travel directions (Fig. S6)—though insignificant due to our small number of samples from atypical storm trajectories—could also suggest that material collected along the path of a storm is later deposited as snow.
Broad questions on the impact of snowfall-deposited microbiology on both public health and ecosystem function can be generated by the work we describe herein. With respect to public health, in light of our work we believe that snowfall (and meteoric deposition of any kind—e.g., rain, snow, ice, fog, and perhaps even general humidity) can be considered a large transporter of microbial biomass with a (to-date) not understood pathogenicity. In considering ecosystem function, the impact of some ∼10 kg of bacterial/archaeal biomass being deposited per hectare in a year of snowfall clearly must include effects on receiving soil, rock endolith and/or near-surface water ecosystems. This has impacts on ecological soil formation, maintenance and health of agricultural soils, and water quality in both fresh and marine ecosystems. As climate change continues to be a driver of large-scale environmental shifts, the intricacies of biological aerosol transport, and bio- cloud glaciation/snow nucleation are unlikely to escape disturbance.
The flux in genetic diversity brought about by fresh snowfall is in much need of greater study. The amount of gDNA deposited by snow per hectare of land suggests that gene flow, via known mechanisms of horizontal gene transfer (Thomas & Nielsen, 2005), is likely widely seeded by continual deposition from storm events. While our work does not specify the live/dead state of microbiological communities in fresh snow, these communities possess genetic banks irrespective of their activity. Mechanisms of horizontal gene transfer are dependent on live vs. dead cells, but it’s important to note that natural transformation can occur under either the live/dead state. Though we cannot specify any magnitude to which horizontal gene transfer occurs between live/live or live/dead pairs due to snow, natural transformation is indeed known to be possible (Thomas & Nielsen, 2005). Ecosystem in situ genetic diversity is thus likely to be in a state of higher flux than previously acknowledged, with receiving ecosystems likely more capable of responding to dynamic environmental conditions with updated “genetic banks,” literally always raining upon them. As we argue that the biomass within meteoric snow is ecologically impactful, we acknowledge that one may posit that what is deposited in snow would be just a fraction of the biomass already existing at the soil/hydrologic interface. We point out that meteoric snow would certainly be less consequential if it were uniformly distributed to all surface communities. However, microbiota within snow are highly heterogeneous (even within the same storm) and alternate genetic banks are deposited in different regions, some of which may be native to an area already—but many are likely to be non-local. Within oceanic systems, McDaniel et al. (2010) show that up to 47% of culturable bacteria are confirmed gene recipients by known mechanisms of horizontal gene transfer; if 1 year of snowfall biomass represents even 0.1% of the cells within the top one cm of receiving soil (assuming 1 × 109 cells cm−3), those cells would be in sufficient quantity to impart new genetic material on the host community. If surface communities demonstrated even a fraction of the horizontal gene transfer ability of oceanic communities, a substantial portion of that entire one cm layer (and more) would be the beneficiary of new genetic material—accelerating genome innovation (Jain, 2003). Bacteria/archaea genomic innovation and resiliency has largely been driven by horizontal gene transfer (Ochman, Lawrence & Groisman, 2000) and we expect that environmental systems comprised of these organisms are likely to depend upon this mechanism for survival. Since lateral gene transfer increases genomic diversity at rates much higher than in situ evolution alone (Ochman, Lawrence & Groisman, 2000), communities that receive higher fluxes of genetic material are likely to be more resilient than those that receive very little. We demonstrate in our investigation that geographic areas receive distinct biological input. This suggests that “genetic banks” received by surfaces during snow storms send different locales on alternate genetic uptake and evolutionary pathways. Genetic transport by snowfall (and rain/ice/humidity) disallow microbial communities at any given geography to remain isolated. In an Earth system increasingly affected by climate change, the ability of local microbial communities to adapt will become paramount; atmospheric microbial transfer and snow/rain/icing/humidity events should be considered essential components in delivering novel genetic material to geographic areas. The ability for soil/water receiving microbial systems to remain resilient will have demonstrable effects on downstream ecological pathways such as macroscopic life and the mediation of soil/water chemical equilibrium—including the management of contaminants. The “everything is everywhere” notion of microbial distribution across the globe can likely be better understood by the interaction of Earth’s compartments (lithosphere, hydrosphere, and atmosphere) via transport. On-going work with metagenomics, transcriptomics and single-cell genomics should better inform the surface ecosystem-altering effects of the genetic potential of storm delivered events.
We suggest that bio-meteorology is likely to have impacts far beyond the Colorado Front Range alone; everything that we describe here is globally relevant to the lithosphere/hydrosphere/atmosphere interface in tropical, temperate, and polar climates. Indeed, biology likely needs to be better incorporated into meteorology and meteorologic modeling. Disparate concepts ranging from ecological forest fire recovery to regional public health and pathogen transport are likely to be affected by the geochemical and biological depositions that we have described in snowfall (though these findings are likely also relevant to all meteoric waters including rain, fog, icing events, and humidity). Further, biometeorology could likely be better informed and made capable of public-health related predictability with further microbiome understanding of widespread and large-scale meterologic events.
Conclusions
Herein, we have determined that microbiota within fresh snowfall are ubiquitous and non-homogenous with respect to geography. The aqueous chemistry of fresh snowfall is, similarly, predictable by snowfall location. These deposited microbiota represent both enough mass and genetic diversity to affect receiving surface, rock- endolith, and hydrologic microbiological communities. The atmospheric transport of “genetic banks” via fresh snowfall—though our findings are also likely relevant to rain/icing/humidity events—should not be ignored in whole-Earth understanding of the microbial notion of “everything is everywhere.” Storm-tracks are a valuable tool for determining affecters of biogeography, and should be investigated further with ongoing work targeting microbial “fingerprints” of atmospheric events, benefitting both public- health related predictability of atmospheric/receiving system state as well as Earth ecology as a whole.
Supplemental Information
Sample rarefaction curves.
Rarefaction curves generated by rarefying bacterial/archaeal sequences at different levels with random OTU sub-sampling. Each curve and color represents a different sample. A blanket rarefaction value of 3,391 sequences was chosen for the bacterial and archaeal sequence dataset.
{kind=link}
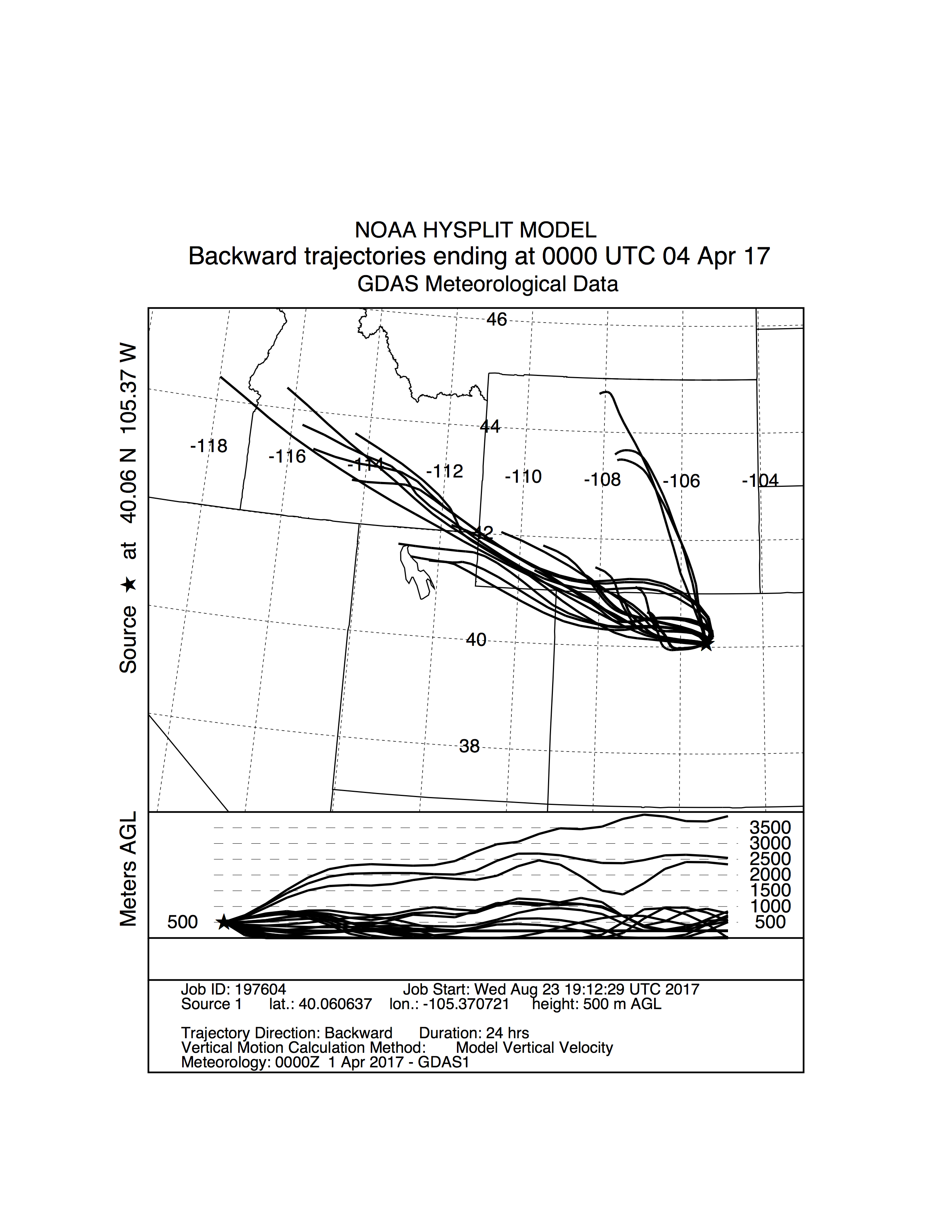
Storm trajectory from Sunshine on 04/04/17.
NOAA HYSPLIT storm trajectory model generated for the sample collection in Sunshine on 04/04/17. Streamlines are a medley of trajectory models distributed about the latitude and longitude of the sampling site. The backward trajectories encompass 24 hours of storm movement prior to arrival at the sampling location at an altitude of 500 m AGL (above ground level). This storm was classified as having a NW origin. See Fig. S3 for the Golden counterpart to this storm.
{kind=link}
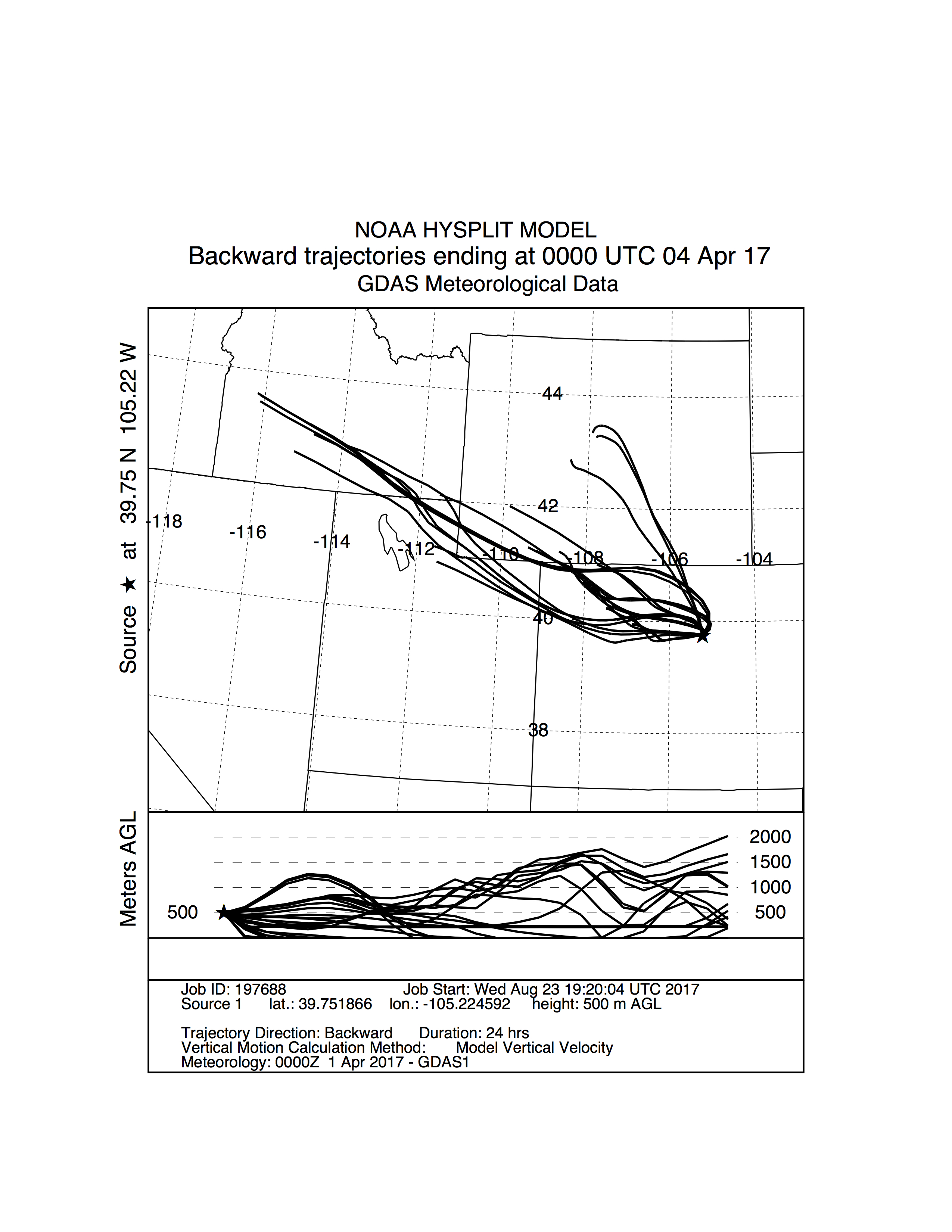
Storm trajectory from Golden on 04/04/17.
NOAA HYSPLIT storm trajectory model generated for the sample collection in Golden on 04/04/17. Streamlines are a medley of trajectory models distributed about the latitude and longitude of the sampling site. The backward trajectories encompass 24 hours of storm movement prior to arrival at the sampling location at an altitude of 500 m AGL (above ground level). This storm was classified as having a NW origin. See Fig. S2 for the Sunshine counterpart to this storm.
{kind=link}
Relative abundance heat map of snow microbiota, by Location.
Relative abundances (more red = higher relative abundance) of bacterial/archaeal (A) and eukaryotic (B) sequences recovered from snow samples pooled by Sampling Location. Class-level assignments are listed first on the y-axis for each taxa, followed by a semi-colon and its associated phylum. Taxonomy was assigned via the SILVA database by DADA2. These data have been rarefied.
{kind=link}
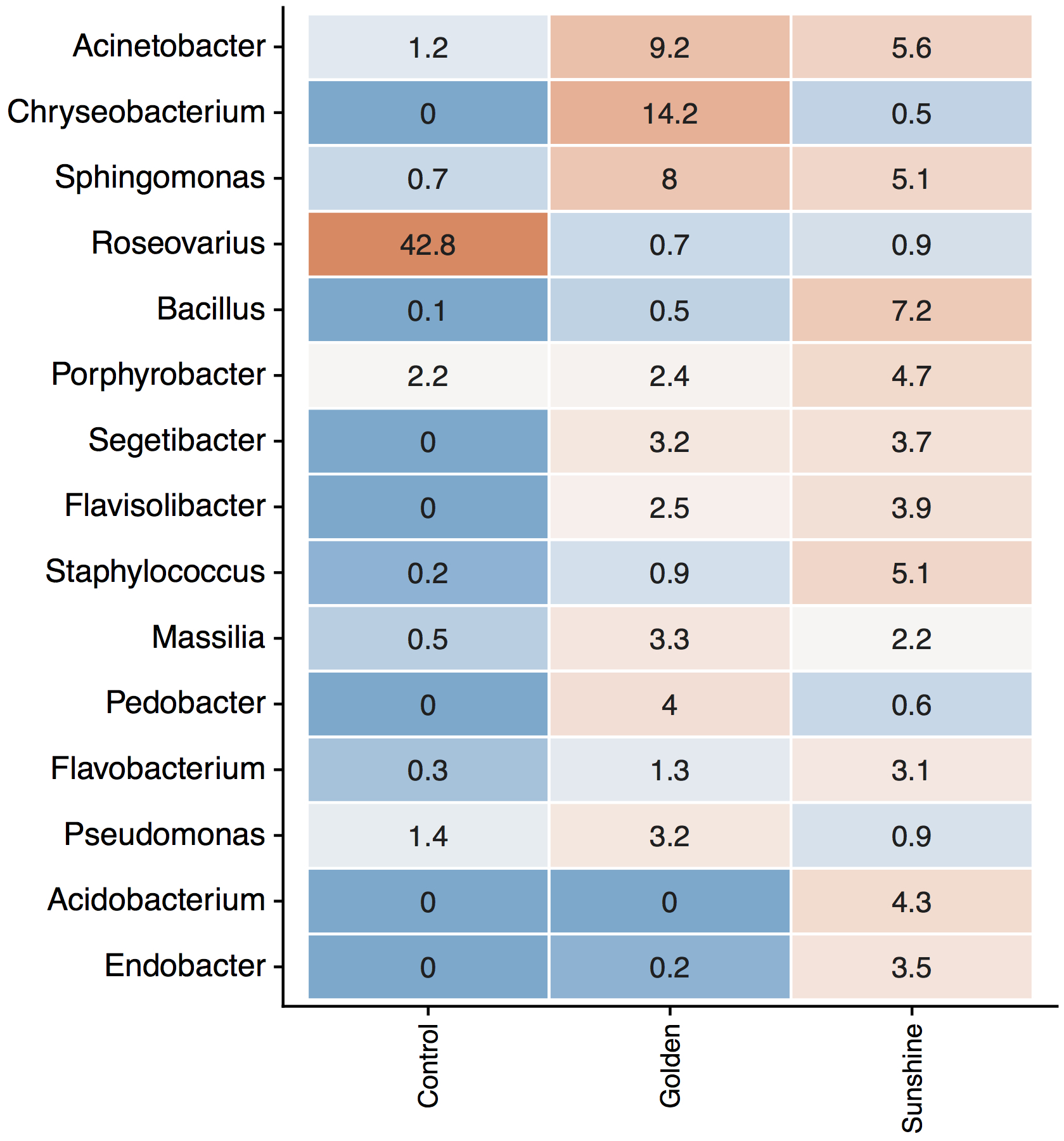
Genera relative abundances in snow, by Sampling Location vs. Control.
Demonstration that the most influential genera listed in Table 1 are not contamination. Numbers are relative abundances; more red means higher abundance. These data have been rarefied the same as all other analyzed samples.
{kind=link}
Relative abundance heat map of snow microbiota, by Storm Origin.
Relative abundances (more red = higher relative abundance) of bacterial/archaeal (A) and eukaryotic (B) sequences recovered from snow samples pooled by Storm Origin. Class-level assignments are listed first on the y-axis for each taxa, followed by a semi-colon and its associated phylum. Taxonomy was assigned via the SILVA database by DADA2. These data have been rarefied.
{kind=link}
Sunshine vs. Golden filter quadrants.
These two filter quadrants (0.45-μm pore size) collected snow from the same storm on 01/04/17. The top (cleaner) filter filtered snow from Sunshine; the bottom (dirtier) filter filtered snow from Golden.
{kind=link}
Raw IC/ICP-AES analyte data from melted and filtered snow.
IC and ICP-AES data are separated by boxes.