

Abstract
The asynchronous timing of replication of different chromosome domains is essential for eukaryotic genome stability, but the mechanisms establishing replication timing programs remain incompletely understood. Drosophila SNF2-related factor SUUR imparts under- replication (UR) of late-replicating intercalary heterochromatin (IH) domains in polytene chromosomes1. SUUR negatively regulates DNA replication fork progression across IH; however, its mechanism of action remains obscure2, 3. Here we developed a novel method termed MS-Enabled Rapid protein Complex Identification (MERCI) to isolate a stable stoichiometric native complex SUMM4 that comprises SUUR and a chromatin boundary protein Mod(Mdg4)- 67.24, 5. In vitro, Mod(Mdg4) stimulates the ATPase activity of SUUR, although neither SUUR nor SUMM4 can remodel nucleosomes. Mod(Mdg4)-67.2 and SUUR distribution patterns in vivo partially overlap, and Mod(Mdg4) is required for a normal spatiotemporal distribution of SUUR in chromosomes. SUUR and Mod(Mdg4)-67.2 mediate insulator activities of the gypsy mobile element that disrupt enhancer-promoter interactions and establish euchromatin- heterochromatin barriers in the genome. Furthermore, mutations of SuUR or mod(mdg4) reverse the locus-specific UR. These findings reveal that DNA replication can be delayed by a chromatin barrier and thus, uncover a critical role for architectural proteins in replication timing control. They also provide a biochemical link between ATP-dependent motor factors and the activity of insulators in regulation of gene expression and chromatin partitioning.
Main
Replication of metazoan genomes occurs according to a highly coordinated spatiotemporal program, where discrete chromosomal regions replicate at distinct times during S phase of the cell cycle6. In general, the replication program follows the spatial organization of the genome in Megabase-long constant timing regions interspersed by timing transition regions7. The spatiotemporal replication program was noted to exhibit correlations with the genetic activity, epigenetic marks and features of 3D genome architecture. Yet the mechanisms for these correlations remain obscure. It has been speculated that the structural features of DNA, epigenetic regulation of chromatin and sub-nuclear localization of chromosome domains can coordinately impart the asynchronous, locus-specific replication of the genome7. Interestingly, the timing of firing for any individual origin of replication is established during G1 before pre- replicative complexes (pre-RC) are assembled and licensed at origins8.
Most larval tissues of Drosophila melanogaster grow via G-S endoreplication cycles that duplicate DNA without cell division resulting in polyploidy9. In some polyploid tissues like the salivary gland, all of the >1,000 duplicated DNA molecules align in register along their lengths to form giant polytene chromosomes10. Importantly, large genomic domains corresponding to the latest replicated regions of dividing cells, specifically pericentric (PH) and intercalary (IH) heterochromatin, occasionally fail to complete endoreplication resulting in under-replication (UR). As a rule, in both dividing and endoreplicating cells, these regions are devoid of discernable sites for binding the Origin of Replication Complex (ORC) and thus, their replication must rely on forks progressing from external distal origins11. Although cell cycle programs are drastically dissimilar between endoreplicating and mitotically dividing cells, they share biochemically identical DNA replication machinery9. Consequently, UR provides a facile readout for late-S phase replication initiation and fork progression, which play a central role in establishing the DNA replication timing program.
The Suppressor of UR (SuUR) gene is essential for polytene chromosome UR in IH and PH1. It encodes a protein (SUUR) containing a helicase domain with a homology to that of the SNF2/SWI2 family. Its contribution to regulation of DNA replication remains enigmatic, although it has been shown that the occupancy of ORC is not increased in SuUR mutant UR regions11. Rather than inhibiting the pre-RC assembly or origin firing, SUUR negatively regulates the rate of replication2 by an unknown mechanism. It has been proposed3 that the retardation of replisome by SUUR takes place via simultaneous physical association with the components of the fork (e.g., CDC45 and PCNA)12 and repressive chromatin proteins, such as HP1a13. The deceleration of SUUR-bound replication forks was also invoked as an explanation for the apparent role of SUUR in the establishment of epigenetic marking of IH3.
Identification of SUMM4, the native form of SUUR in Drosophila embryos
To determine how SUUR functions in replication control we sought to identify the native complex in which it acts. Previous attempts to characterize the native form of SUUR by co-IP or tag-affinity purification of ectopically expressed protein gave rise to multiple putative binding partners2, 12–14. However, evaluating whether any of these proteins are present in a native SUUR complex is problematic because of the low abundance of SUUR, which is difficult to detect by immunoblotting of native material. It also precludes its purification by conventional chromatography. Therefore, we developed a novel biochemical approach that relies on partial purification by multi-step FPLC and shotgun proteomics of chromatographic fractions by quantitative LCMS (Fig. 1a). We term this technology MERCI for MS-enabled Rapid protein complex Identification (see Methods).

a, Schematic of FPLC purification of the native form of SUUR using MERCI approach. ILR, ion library obtained by IDA of recombinant FLAG-SUUR; IL1-5, ion libraries obtained by IDA of FPLC fractions from chromatographic steps 1-5. KPi, potassium phosphate, pH 7.6. b, Recombinant FLAG-SUUR expressed in Sf9 cells. Identities of eight most prominent bands were determined by mass- spectroscopy. p130 and p65 correspond to full-length and C-terminally truncated FLAG-SUUR, respectively (red arrows). Other bands represent common Sf9-specific contaminants purified by FLAG chromatography (blue dashed lines), cf purified EGG-F (green arrow). Molecular mass marker bands are indicated (kDa). c, SWATH quantitation profiles of SUUR fractionation across individual FPLC steps. Ion libraries used for SWATH quantitation are shown at the bottom. Z- scores across indicated column fractions are plotted; error bars, standard deviations (N=3). Gray rectangles, fraction ranges used for the next FPLC step; in Superdex 200 step, black arrows, expected peaks of globular proteins with indicated molecular masses in kDa. d, SWATH quantitation profiles of SUUR (red) and Mod(Mdg4) (cyan) fractionation across five FPLC steps. IL5 ion library was used for SWATH quantification. e, Pearson correlation of fractionation profiles for individual 132 proteins to that of SUUR, sorted from largest to smallest. Red box, the graph portion shown in (f). f, Top ten candidate proteins with the highest Pearson correlation to SUUR. Red dashed line, trend line extrapolated by polynomial regression (n = 5) from the bottom 130 proteins. g, Western blot analyses of Superdex 200 fractions with SUUR and ModT antibodies. Molecular mass markers are shown on the left (kDa). h, Co-IP experiments. SUUR (red arrowhead) co-purifies from nuclear extracts with Mod(Mdg4)-67.2 (cyan arrowheads) but not HP1a (green arrowhead). Anti-XNP co-IPs HP1a but not SUUR of Mod(Mdg4)-67.2. Asterisks, IgG heavy and light chains detected due to antibody cross-reactivity. Mod(Mdg4)- 67.2(FL) antibody recognizes all splice forms of Mod(Mdg4).
The depth of proteomic quantification is limited by the range of peptides identified in the information-dependent acquisition (IDA), dubbed “ion library” (IL). Unfortunately, SUUR- specific peptides could not be found in ion libraries obtained from acquisitions of either crude nuclear extracts from embryos or the collection of fractions from the first, phosphocellulose step (IL1, Extended Data Fig. E1a, Supplementary Table S1). Thus, to quantify SUUR in phosphocellulose fractions, we augmented IL1 with the ion library obtained by acquisition of recombinant FLAG-SUUR (ILR, Figs. 1a, b) expressed in the baculovirus system. In ion libraries from all subsequent chromatographic steps, peptides derived from native SUUR were detected (Extended Data Fig. E1a, Supplementary Table S1) and used for quantification of the cognate data-independent acquisitions (DIA/SWATH) (Fig. 1c). Quantification of SWATH data measures only the relative (to the reference protein) amounts of SUUR across chromatographic fractions. To measure absolute levels of SUUR, a semi-quantitative approach can be used by building a titration curve from SWATH acquisitions of known amounts of recombinant SUUR (Extended Data Figs. E1b, c). In this manner, we estimated the amount of SUUR in the nuclear extract (∼140 pg in 25 µg total protein, Extended Data Fig. E1c) and in individual fractions from all chromatographic steps (Extended Data Fig. E1d). Although in five FPLC steps we achieved >3,000-fold purification of SUUR, it remained only ∼2% pure (Extended Data Fig. E1e). A progressive loss of material precludes further purification (300 ng of SUUR out of a total 16 µg protein). Thus, the putative SUUR complex cannot be purified to an apparent homogeneity from a substantial amount of starting material (∼1 kg Drosophila embryos, equivalent to 2.5 g protein) by conventional chromatography.
The final aspect of the MERCI algorithm calls for re-quantification of all FPLC fraction SWATH acquisitions with an ion library from the last step (IL5), which is enriched for peptides derived from SUUR and co-purifying polypeptides (Fig. 1b) and includes only 140 proteins (Extended Data Fig. E1a, Supplementary Table S1). In this fashion, under-represented polypeptides (including SUUR and, potentially, subunits of a putative SUUR complex) that may not be IDA-detectable in earlier steps will not evade quantification. Purification profiles of proteins that could be quantified in all five FPLC steps (132) were then artificially stitched together into 83-point arrays of Z-scores (Fig. 1d, Supplementary Table S2). These profiles were analyzed for Pearson correlation with that of SUUR and ranked down from the highest Pearson coefficient, PCC (Fig. 1e). Whereas the PCC numbers for the bottom 130 proteins lay on a smooth curve, the top two proteins, SUUR itself (PCC = 1.000) and Mod(Mdg4) (PCC = 0.939) fell above the extrapolated (by polynomial regression) curve (Fig. 1f) and were thus distinct from the rest of proteins. Consistently, SUUR and Mod(Mdg4) exhibited nearly identical purification profiles in all five FPLC steps (Fig. 1d), unlike the next two top-scoring proteins, EGG (PCC = 0.881) and CG6700 (PCC = 0.874) (Extended Data Figs. E1f, g). Also, HP1a (PCC = 0.503), which had been previously hypothesized to form a stable complex with SUUR13 did not co-purify with SUUR in any of the FPLC steps (Extended Data Fig. E1h).
Mod(Mdg4) is a BTB/POZ domain protein that functions as an adaptor for architectural proteins that promote various aspects of genome organization4, 5. It is expressed as 26 distinct polypeptides generated by splicing in trans of a common 5’-end precursor RNA with 26 unique 3’-end precursors15. IL5 contained seven peptides derived from Mod(Mdg4) (99% confidence). Whereas four of them mapped to the common N-terminal 402 residues, three were specific to the C-terminus of a particular form, Mod(Mdg4)-67.2 (Extended Data Figs. E1i, j). No peptides specific to other splice forms were detected. We raised an antibody to the C-terminus of Mod(Mdg4)-67.2, designated ModT antibody, and analyzed size exclusion column fractions by immunoblotting with SUUR and ModT antibodies. Consistent with our SWATH analyses (Figs. 1c, d) ∼100-kDa SUUR and Mod(Mdg4)-67.2 polypeptides copurified as a complex with an apparent molecular mass of ∼250 kDa (Fig. 1g). Finally, we confirmed that SUUR is specifically co-immunoprecipitated with Mod(Mdg4)-67.2 from crude extracts (Fig. 1h). As a control, XNP co-immunoprecipitated with HP1a as shown previously16, but did not with SUUR or Mod(Mdg4). We conclude that in vivo SUUR and Mod(Mdg4) form a stable stoichiometric complex that we term SUMM4.
Biochemical activities of recombinant SUMM4 in vitro
We reconstituted recombinant SUMM4 complex by co-expressing FLAG-SUUR with Mod(Mdg4)-67.2-His6 in Sf9 cells (Fig. 2a). As expected, they co-purified by FLAG affinity chromatography. Mod(Mdg4)-67.2 is the predominant splice form of Mod(Mdg4) expressed in embryos (e.g., Fig. 1h). Thus, minor SUUR-Mod(Mdg4) complexes may have failed to be identified by IDA in IL5 (Extended Data Fig. E1i). We discovered that FLAG-SUUR did not co-purify with another splice form, Mod(Mdg4)-59.1 (Extended Data Figs. E1k, Fig. 2a).

a, Recombinant SUMM4. Mod(Mdg4)-His6, 67.2 (p100, cyan arrowhead) and 59.1 (p75, green arrowhead) splice forms were co-expressed with FLAG-SUUR (red arrowheads, p130 and p65) or separately in Sf9 cells and purified by FLAG or Ni-NTA affinity chromatography. Mod(Mdg4)-67.2 forms a specific complex with SUUR. b, ATPase activities of recombinant FLAG-ISWI (green bars), FLAG-SUUR (red bars) and SUMM4 (FLAG-SUUR + Mod(Mdg4)-67.2-His6, purple bars). Equimolar proteins were analyzed in reactions in the absence or presence of plasmid DNA or equivalent amounts of reconstituted oligonucleosomes, ±H1. rSUUR(KA) and rMMD4, ATPases activities of K59A mutant of SUUR (gray bars) and Mod(Mdg4)-67.2-His6 (cyan bars). Hydrolysis rates were converted to moles ATP per mole protein per minute. All reactions were performed in triplicate, error bars represent standard deviations. p-values for statistically significant differences are indicated (Mann-Whitney test). c, DNA- and nucleosome-dependent stimulation or inhibition of ATPase. The activities were analyzed as in (b). Statistically significant differences are shown (Mann-Whitney test). d, Nucleosome sliding activities by EpiDyne®-PicoGreen™ assay (see Methods) with 5 nM of recombinant ISWI, SUUR or SUMM4. Reaction time courses are shown for terminally (6-N-66) and centrally (50-N-66) positioned mononucleosomes (Extended Data Figs. E2g-j). RFU, relative fluorescence units produced by PicoGreen fluorescence.
Therefore, the shared N-terminus of Mod(Mdg4) (1-402) is not sufficient for interactions with SUUR. However, this result does not exclude a possibility that SUUR may form complex(es) with some of the other, low-abundance 24 splice forms of Mod(Mdg4). The SUUR-Mod(Mdg4)-67.2 interaction is specific, as the second-best candidate from our correlation analyses (Drosophila SetDB1 ortholog EGG; Fig. 1f) did not form a complex with FLAG-SUUR (Extended Data Fig. E2a), although it associated with its known partner WDE, an ortholog of hATF7IP/mAM17.
The N-terminus of SUUR contains a region homologous with SNF2-like DEAD/H helicase domains. Although SUUR requires its N-terminal domain to function in vivo14, it has been hypothesized to be inactive as an ATPase18. We directly measured the ATPase activities of recombinant SUUR and SUMM4 (Fig. 2a) in comparison with that of recombinant Drosophila ISWI (Fig. 2b). Purified recombinant Mod(Mdg4)-67.2 and a variant SUUR protein with a point mutation in the putative Walker A motif (K59A) were used as negative controls (Fig. 2a, Extended Data Fig. E2b). Contrary to the prediction18, both SUUR and SUMM4 efficiently hydrolyzed ATP. Notably, SUMM4 was 1.4- to 2-fold more active than SUUR alone, indicating that Mod(Mdg4)-67.2 stimulates SUUR enzymatic activity. We also examined whether SNF2 ATPase cofactors (DNA and nucleosomes) can stimulate the activity of SUUR. To this end, we reconstituted oligonucleosomes on plasmid DNA (Extended Data Figs. E2bc-e). Linker histone H1-containing chromatin was also used as a substrate/cofactor, because SUUR has been demonstrated to physically interact with H119. In contrast to ISWI, SUUR was not stimulated by addition of DNA or nucleosomes and moderately (by about 70%) activated by H1-containing oligonucleosomes (Fig. 2c). SUMM4 was weakly activated by nucleosomes, whereas both ISWI and SUMM4 were inhibited by H1 assembled into chromatin.
We next examined the nucleosome remodeling ability of SUUR and SUMM4; specifically, their ability to expose a positioned DNA motif in the EpiDyne®-PicoGreen™ assay (Methods and Extended Data Fig. E2f). Centrally or terminally positioned mononucleosomes were efficiently mobilized by ISWI and human BRG1 in a concentration- and time-dependent manner (Extended Data Figs. E2g-j). In contrast, SUUR and SUMM4 did not reposition either nucleosome (Fig. 2d). Thus, SUUR and SUMM4 do not possess a detectable remodeling activity. They resemble certain other SNF2-like enzymes (e.g., RAD54) that instead utilize the energy of ATP hydrolysis to mediate alternate DNA translocation reactions20.
The distribution of SUMM4 complex in vivo
We examined the localization patterns of SUMM4 subunits in polytene chromosomes by indirect immunofluorescence (IF) and discovered their strong overlap (Fig. 3a). In late endo-S phase when SUUR exhibited a characteristic pattern of distribution, enriched at IH and PH domains, it invariably co-localized with Mod(Mdg4)-67.2, except for the chromocenter that did not show appreciable occupancy by Mod(Mdg4)-67.2. In fact, Mod(Mdg4)-67.2 was present at classical regions of SUUR enrichment, such as UR domains in 75C and 89E (Extended Data Fig. E3a). In contrast, there were multiple sites of Mod(Mdg4)-67.2 localization that were free of SUUR. This finding suggests that there are additional native form(s) of Mod(Mdg4)-67.2, either as an individual polypeptide or in complex(es) other than SUMM4. When we fractionated Drosophila nuclear extract using a different progression of FPLC steps (Extended Data Fig. E3b), we found that Mod(Mdg4)-67.2 can form a megadalton-size complex that did not contain SUUR (Extended Data Figs. E3c-e). Therefore, a more intricate pattern of Mod(Mdg4)-67.2 distribution in polytene chromosomes likely reflects loading of both SUMM4 and the alternative complex.

a, Colocalization of SUUR and Mod(Mdg4)-67.2 in wild-type polytene chromosomes. Localization patterns of Mod(Mdg4)-67.2 and SUUR in L3 polytene chromosomes were analyzed by indirect IF staining. The polytene spread fragment (3L and 3R arms) corresponds to a nucleus in late endo-S phase, according to PCNA staining (Extended Data Fig. E3a). ModT (green) and SUUR (red) signals overlap extensively in euchromatic arms. The additional strong ModT IF loci that are SUUR-free and Mod(Mdg4)-67.2-free SUUR in the chromocenter are obvious. DAPI staining shows the overall chromosome morphology. b, SUUR loading into chromosomes during early endo-S phase is compromised in mod(mdg4) mutants. SuUR mutation does not appreciably change the distribution of Mod(Mdg4)-67.2. Polytene chromosomes were prepared from wild-type and mutant salivary glands and stained with ModT and SUUR antibodies as in (a). Endo-S timing was established by PCNA staining (Extended Data Fig. E3g). c, Abnormal subcellular distribution of SUMM4 subunits in mod(mdg4) mutants. L3 salivary glands were fixed and whole-mount-stained with DAPI, ModT and SUUR antibodies. Whereas both polypeptides are mostly nuclear in the wild type, they are partially mis-localized to cytoplasm in mod(mdg4)u1 mutant.
We tested whether SUUR and Mod(Mdg4) loading into polytene chromosomes were mutually dependent using mutant alleles of SuUR and mod(mdg4). SuURES is a null allele of SuUR21. mod(mdg4)m9 is a null allele encompassing a 12,016-bp deficiency that removes gene regions of the shared 5’-end precursor of all Mod(Mdg4) splice variants in addition to eight specific 3’-precursors22. mod(mdg4)u1 contains an insertion of a Stalker mobile element in the last coding exon of Mod(Mdg4)-67.2 3’-precursor and can only affect the expression of Mod(Mdg4)-67.25. SuURES and mod(mdg4)u1 are homozygous viable, and mod(mdg4)m9 is recessive adult pharate lethal. Consistently, we could not detect Mod(Mdg4)-67.2 expression in homozygous mod(mdg4)m9 L3 salivary glands, whereas mod(mdg4)u1 expressed a truncated polypeptide (cf, ∼70 kDa and ∼100 kDa, Extended Data Fig. E3f). The truncated 70-kDa polypeptide failed to load into polytene chromosomes (Fig. 3b, Extended Data Fig. E3g). Also, as shown previously, SUUR cannot be detected in SuURES polytene chromosomes. Since homozygous mod(mdg4)m9 L3 larvae were produced by inter se crosses of heterozygous parents, the very low amounts of Mod(Mdg4)-67.2 in mod(mdg4)m9 polytene chromosomes (barely above the detection limit) were presumably maternally contributed, although diluted >1,000 fold during development and possibly degraded.
Importantly, the absence (or drastic decrease) of Mod(Mdg4)-67.2 also strongly reduced the loading of SUUR (Fig. 3b, Extended Data Fig. 3g). The normal distribution pattern of SUUR in polytene chromosomes is highly dynamic12, 19. SUUR is initially loaded in chromosomes at the onset of endo-S phase and then re-distributes, while constantly remaining partially co-localized with the replication fork (PCNA), through very late endo-S when SUUR becomes accumulated in UR domains and PH. The deposition of SUUR and its co-localization with PCNA has been proposed to depend on direct physical interaction with components of the replisome12. In both mod(mdg4) mutants, we observed a striking absence of SUUR in polytene chromosomes during early endo-S, which indicates that the initial deposition is dependent on its interactions with Mod(Mdg4). Although SUUR deposition slightly recovered by late endo-S, it was still several fold weaker than that in wild type. Potentially, in the absence of Mod(Mdg4), SUUR may be tethered to IH and PH loci by direct binding with linker histone H1 as shown previously19, albeit with a lower efficiency. Finally, the gross subcellular distribution of SUUR also strongly correlated with that of Mod(Mdg4): a mis-localization of truncated Mod(Mdg4)-67.2 from nuclear to partially cytoplasmic was accompanied by a similar mis-localization of SUUR (Fig. 3c). This result indicates that the truncation of Mod(Mdg4) in mod(mdg4)u1 may likely have an antimorphic effect by mis-localization and deficient chromatin binding of interacting polypeptides, including SUUR and others (Fig, 3c, Extended Data Figs. 3b-e).
The role of SUMM4 as an effector of the insulator/chromatin barrier function
Mod(Mdg4)-67.2 does not directly bind DNA but instead is tethered to chromatin by a physical association with zinc finger factor Suppressor of Hairy Wing, Su(Hw). Su(Hw) directly binds to consensus sequences that are present in gypsy transposable elements and are also widely distributed across the Drosophila genome in thousands of copies23. Mod(Mdg4)-67.2 was previously shown to be essential for the insulator activity of gypsy5, which functions in vivo to disrupt enhancer-promoter interactions and establish a barrier to the propagation of chromatin forms24, 25. We therefore tested whether SUMM4 contributes to gypsy insulator function. The ct6 allele of Drosophila contains a gypsy element inserted between the wing enhancer and promoter of the gene cut that inactivates cut expression and results in abnormal wing development (Fig. 4a). We discovered that both mod(mdg4)u1 and SuURES mutations partially suppressed this phenotype (Fig. 4a). Thus, both subunits of SUMM4 are required to mediate the full enhancer- blocking activity of gypsy. Another Drosophila in vivo insulator assay makes use of a collection of P{SUPor-P} insertions that contain the white reporter gene flanked by 12 copies of gypsy Su(Hw)-binding sites. When P{SUPor-P} is inserted in heterochromatin, white is protected from silencing resulting in red eyes26. Again, both mod(mdg4)u1 and SuURES relieved the chromatin barrier function of Su(Hw) sites, causing repression of white (Fig. 4b). SuUR has been previously characterized as a weak suppressor of variegation of the whitem4h X chromosome inversion allele, which places the white gene near PH27. In contrast, SuUR mutation enhances variegation in the context of insulated, PH-positioned white. We conclude that SUMM4 is an insulator complex that mediates the chromatin boundary function of gypsy.

a, SUMM4 subunits are required for the enhancer-blocking activity at ct6. Top: schematic diagram of the ct6 reporter system; the gypsy retrotransposon is inserted in between the wing enhancer and promoter of cut 61. Bottom left: the appearance of wild type adult wing; bottom right: the appearance of ct6 adult wing in the wild-type background. SuURES and mod(mdg4)u1 alleles are recessive suppressors of the ct6 phenotype. Red and black arrowheads point to distinct anatomical features of the wing upon SuUR mutation. b, SUMM4 subunits are required for the chromatin barrier activity of Su(Hw) binding sites. Top: schematic diagram of the P{SUPor-P} reporter system62; clustered 12 copies of gypsy Su(Hw) binding sites flanks the transcription unit of white. KV00015 and KV00138 are P{SUPor-P} insertions in pericentric heterochromatin of 2L. SuURES and mod(mdg4)u1 alleles are recessive suppressors of the boundary that insulates white from heterochromatin encroaching. c, Schematic model for the function of SUMM4 in blocking enhancer-promoter interactions in the ct6 locus. d, Schematic model for the function of SUMM4 in establishing a chromatin barrier in heterochromatin- inserted P{SUPor-P} elements. e, Schematic model for a putative function of SUMM4 in blocking/retardation of replication fork progression in IH domains. f, DNA copy numbers were determined by real-time qPCR. Copy numbers were calculated relative to embryonic DNA and normalized to a control intergenic region. The X-axis shows chromosome positions (in megabase pairs) of target amplicons. Error bars represent the confidence interval (see Methods). Black arrowheads, positions of mapped Su(Hw) binding sites59. Yellow boxes show approximate boundaries of cytogenetic bands. The right column shows representative images of DAPI-stained polytene chromosome fragments corresponding to this genomic region; genotypes of the animals are as indicated, locations of cytological bands 75C1 and C2 are shown in yellow. The disk thickness and DAPI staining of 75C1-2 is strongly increased in mutants. Close-up view of DNA copy numbers in 75C (3L) from high-throughput sequencing data are presented as in (g). g, Analyses of DNA copy numbers in Drosophila salivary gland cells. DNA from L3 salivary glands was subjected to high-throughput sequencing. DNA copy numbers (normalized to diploid embryonic DNA) are shown across the 3L chromosome arm. Genomic coordinates in Megabase pairs are indicated at the bottom. The control trace (w1118 allele) is shown as semitransparent light gray in the foreground; SuURES, mod(mdg4)u1 and mod(mdg4)m9 traces are shown in the background in red, cyan and green, respectively; their overlaps with w1118 traces appear as lighter shades of color. Black box, 75C cytological region shown in (g).
Although a SuUR mutation decreased the activity of the gypsy insulator, the suppression was universally weaker than that by mod(mdg4)u1 (Figs. 4a-b). It is possible that SUUR is not absolutely required for the establishment of the insulator. For instance, the loss of SUMM4 may be compensated by the alternative complex of Mod(Mdg4)-67.2 (Extended Data Figs. 3b-e).
Furthermore, the mod(mdg4)u1 allele is expected to be particularly strong due to its likely antimorphic function, since it can mis-localize interacting partner proteins, including SUUR itself (Figs. 3b, c).
The role of SUMM4 in regulation of DNA replication in polytene chromosomes
A similar, chromatin partitioning-related mechanism may direct the function of SUUR in the establishment of UR in late-replicating IH domains of polytene chromosomes (Fig. 4e). It has been long known that 3D chromosome partitioning maps show an “uncanny alignment” with replication timing maps6. To examine the possible roles of SUMM4 in UR, we first analyzed DNA copy numbers in salivary glands of w1118 control, SuUR and mod(mdg4) mutant L3 larvae by qPCR at two known SUUR target loci (cytological regions 75C and 4D). As shown before, we observed an almost complete reversal of UR by SuUR mutation, whereas in mod(mdg4) mutants there was a moderate recovery of DNA copy number (Fig. 4f, Extended Data Fig. 4a).
Furthermore, cytological evidence in 75C region supported the molecular analyses in that all mutants universally exhibited a brighter DAPI staining of the 75C1-2 band than that in w1118, indicative of higher DNA content (Fig. 4f). We thus measured DNA copy number genome-wide by next generation sequencing (NGS). In w1118 salivary glands, the DNA copy profile revealed large (>100-kbp) domains of reduced ploidy (Extended Data Fig. E4b), similar to a previous report19. Excluding pericentric and sub-telomeric heterochromatin, we called 70 UR regions (Extended Data Table E1) in euchromatic arms, as described in Methods. In both SuUR and mod(mdg4) larvae, we observed suppression of UR in IH (Fig. 4f, Extended Data Fig. E4b, Extended Data Table E1). Consistent with its distribution in vivo (Fig. 3a), Mod(Mdg4)-67.2 was dispensable for UR in PH. The NGS data also strongly correlated with qPCR measurements of DNA copy numbers in 75C and 4D.
Uniformly, SuUR mutation gave rise to a stronger relief of UR than that produced by even the null mutation mod(mdg4)m9 (Extended Data Table E1). This result can be explained by considering embryonic deposition of functional Mod(Mdg4) proteins and RNA by heterozygous mothers (see above). Although third instar larvae are ∼1,000-fold larger, volume-wise, than the embryos, persistent Mod(Mdg4)-67.2 can still be detected in these larvae by IF despite its dilution and degradation (Extended Data Fig. E3g). Unlike L3, first instar larvae are nearly identical in size to the embryos. Therefore, since the endoreplication cycles initiate in embryos, in mod(mdg4)m9 animals, the first few out of 10-11 rounds of chromosome polytenization take place with an almost normal amount of Mod(Mdg4) present, which may substantially limit the effect of mod(mdg4)m9 mutation on UR as measured in L3. Some UR loci exhibited a stronger recovery in the mod(mdg4)u1 mutant, which is homozygous viable and thus not subject to the maternal loading effect (Fig. 4g, Extended Data Fig. E4d). Interestingly, the UR of yet another class of regions exhibited strong suppression by the null allele but was completely unresponsive to mod(mdg4)u1 (Extended Data Fig. E4d), suggesting a possibility that SUUR forms SUMM4- like complex(es) with Mod(Mdg4) splice forms other than Mod(Mdg4)-67.2, the only one affected by mod(mdg4)u1. These additional complexes may be required for UR in IH domains that are suppressible by mod(mdg4)m9 but not mod(mdg4)u1. Finally, an important frequent feature of the partially suppressed UR was its asymmetry (Fig. 4f, Extended Data Figs. E4a-d), which is consistent with a unidirectional penetration of the UR domain by a replication fork that fires from the nearest external origin (Fig. 4e).
We conclude that the SUMM4 complex is required for the establishment of UR in the IH domains of Drosophila polytene chromosome. SUMM4 likely causes UR by forming a barrier to replication fork progression. The barrier may be created as a direct physical obstacle to MCM2-7 DNA-unwinding helicase or other enzymatic activities of the replisome. Alternatively, SUMM4 may inhibit the replication machinery indirectly by assembling at the insulator a DNA/chromatin structure that is incompatible with replisome translocation. This putative inhibitory structure may involve epigenetic modifications of chromatin as proposed earlier28 and may also be dependent on Rif1, a negative DNA replication regulator that acts downstream of SUUR14 and/or linker histone H1 as shown previously19.
Discussion
Our work demonstrates for the first time that insulator complexes assembled on chromatin can attenuate the progression of replication forks in salivary glands in vivo. Despite distinct cell cycle programs in dividing and endoreplicating cells, the biochemical composition of replication forks in both cell types is identical9. Therefore, similar insulator-driven control mechanisms for DNA replication are likely conserved in mitotically dividing diploid cells. Our data thus implicate insulator/chromatin boundary elements as a critical component of DNA replication control. Our model suggests that delayed replication of repressed chromatin (e.g., IH) during very late S phase can be imposed in a simple, two-stroke mechanism (Fig. 4e). (1) It requires that an extended genomic domain is completely devoid of functional origins of replication. The assembly and licensing of proximal pre-RC complexes can be repressed epigenetically or at the level of DNA sequence. And (2), this domain has to be separated from flanking chromatin by a barrier element associated with an insulator complex, such as SUMM4. This structural organization is capable of preventing or delaying the entry of external forks fired from distal origins. The current paradigm of replication timing largely focuses on the existence of “early” and “late” origins that are ordained during early S or G1 phase8. Our model offers an additional mechanism to establish a locus-specific late replication program. Insulator complexes and other genome architectural proteins are highly abundant in the genome and assembled in a sequence- specific manner throughout interphase. Even if all origins fire simultaneously (or stochastically, depending on availability of limiting factors) at the onset of S phase, any given DNA replication fork is forced to operate in a dense milieu of abundant, pre-positioned insulator complexes, continuously negotiating with them to get cleared for passage. When these barriers are eventually cleared, the outcome would be indistinguishable from that of an RC firing at “late origin” if analyzed cytologically (by incorporation of labeled nucleotides) or at the level of ChIP.
It is interesting to consider the possible role for SUMM4 in the functions of insulator.
Insulator elements organize the genome into chromatin loops5 that are involved in the formation of topologically associating domains, TADs29–31 . In mammals, CTCF-dependent loop formation requires ATP-driven motor activity of SMC complex cohesin32. In contrast, CTCF and cohesin are thought to be dispensable for chromatin 3D partitioning in Drosophila33. Instead, the larger, transcriptionally inactive domains (canonical TADs) are interspersed with smaller active compartmental domains, which themselves represent TAD boundaries31. It has been proposed that in Drosophila, domain organization does not rely on architectural proteins but is established by transcription-dependent, A-A compartmental (gene-to-gene) interactions31. On the other hand, Drosophila TAD boundaries are enriched for architectural proteins other than CTCF34, and their roles have not been tested directly in loss-of-function models. Thus, it is possible that in Drosophila, instead of CTCF, the 3D partitioning of the genome is facilitated by another group of insulator proteins, such as Su(Hw) and SUMM4 that together associate with class 3 insulators35. Moreover, SUUR may provide the DNA motor function to help establish chromosome contact domains (Figs. 4c-e). Given the noted high-affinity interactions between SUUR and linker histone H119, it is also possible that SUUR favors unidirectional translocation from its initial sites of deposition towards H1-enriched, repressed chromatin, which would promote a physical separation of active and inactive compartmental domains (Figs 4d-e). In fact, this hypothesis is supported by observations of an asymmetric, selective propagation of SUUR towards inside of IH regions (heavily enriched for H119) but not outside (Extended Data Fig. E4e)36.
Our model explains previous observations about other biological functions of SUUR. For instance, global epigenetic modifications observed in the SuUR mutant likely do not directly arise from de-repression of the replisome as suggested3 but, rather, result from the coordinate insulator-dependent regulatory functions of SUUR in both the establishment of a chromatin barrier and DNA replication control (cf Figs. 4d, e). Also, the apparent co-localization of SUUR with PCNA throughout endo-S phase (Extended Data Fig. E3g) may be caused by a replication fork retardation at insulator sites. Initially, SUUR is deposited in chromosomes as a subunit of SUMM4 complex at thousands of loci by tethering via MMD4-Su(Hw) interactions. As replication forks progress through the genome, they encounter insulator complexes where replication machinery pauses for various periods of time before resolving the obstacle. Thus, the increased co-residence time of PCNA and SUUR manifests cytologically as their partial co- localization. With the progression of endo-S phase, some of the SUMM4 insulator complexes are evicted and thus, the number of SUUR-positive loci is decreased, until eventually, the replication fork encounters nearly completely impenetrable insulators demarcating UR domain boundaries. This mechanism is especially plausible given that boundaries of IH loci very frequently encompass multiple, densely clustered Su(Hw) binding sites (e.g., Fig. 4f, Extended Data Fig. E4c). We examined the data from genome-wide proteomic analyses for Su(Hw) and SUUR performed by DamID in Kc167 cells36. Strikingly, Su(Hw) DamID-measured occupancy does not exhibit a discrete pattern expected of a DNA-binding factor. Instead, it appears broadly dispersed, together with SUUR, up to tens of kbp away from mapped Su(Hw) binding sites (Extended Data Fig. E4e). This observation strongly corroborates the translocation model for SUMM4 mechanism of action. According to this model, upon tethering to DNA-bound Su(Hw), SUMM4 traverses the UR region, which helps to separate it in a contact domain. As DNA within the UR region is tracked by SUUR (Figs. 4e), it is brought into a transient close proximity with both SUMM4 and the associated Su(Hw) protein, which is detected by DamID (or ChIP) as an expanded occupancy pattern.
In a recent paper37, Su(Hw) binding sites in S2 cells and in vivo in pupae were found to strongly correlate (within a 5-kbp window) with the occupancy of pre-RC components, ORC2/3, MCM2-7 and CDC45, biased towards origins in repressive “blue” and “black” chromatin. The correlation has been interpreted as Su(Hw) creating a “landing platform” for the assembly of pre- RC. Interestingly, the strongest (by orders of magnitude) co-occupancy was observed for MCM2-7, a hexameric unwinding helicase that is a component of both the licensed pre-RC and active replisome. Incidentally, MCM2-7 would be the first replisome component to encounter any block to replication elongation. Moreover, the correlation between Su(Hw) and CDC45 does not fit the original conclusion, because CDC45 is specific to an activated RC, rather than pre-RC. Thus, an alternative interpretation of the co-occupancy of Su(Hw) with MCM2-7 and CDC45 is replisome slowing down at Su(Hw)-bound insulators, which increases their co-residence time.
An apparent but much weaker correlation with ORC proteins may stem from juxtaposition of origins to a small subset of paused forks that failed to relocate >5 kbp after firing and prior to slowing down by an insulator.
Finally, we present here a facile method, termed MERCI, to rapidly identify subunits of stable native complexes by only partial chromatographic purification. It allows one to circumvent the conventional, rate-limiting approach to purify proteins to an apparent homogeneity. Since a multi-step FPLC scheme invariably leads to an exponential loss of material (Extended Data Fig. 1e), reducing the number of purification steps allows identification of rare complexes, such as SUMM4, which may be present in trace amounts in native sources. On the other hand, MERCI obviates introduction of false-positives frequently associated with tag purification of ectopically expressed targets, which renders its results less reliable. Notably, MERCI is not limited to analyses of known polypeptides, since it is readily amenable to fractionation of native factors based on a correlation with their biochemical activities in vitro.
In conclusion, we used a newly developed MERCI approach to identify a stable stoichiometric complex termed SUMM4 that comprises SUUR, a previously known effector of replication control, and Mod(Mdg4), an insulator protein. SUMM4 subunits cooperate to mediate transcriptional repression and chromatin boundary functions of gypsy-like (class 3) insulators and regulate DNA replication by slowing down replication fork progression through the boundary element. Thus, SUMM4 is required for coordinate regulation of gene expression, chromatin partitioning and DNA replication timing. The insulator-dependent regulation of DNA replication offers a novel mechanism for the establishment of replication timing in addition to the currently accepted paradigm of variable timing of replication origin firing.
Methods
No statistical methods were used to predetermine sample size. The experiments were not randomized and the investigators were not blinded to allocation during experiments and outcome assessment.
Recombinant proteins
Sf9 cells
All baculovirus constructs were cloned by PCR with Q5 DNA polymerase (New England Biolabs) and Gibson assembly with NEBuilder HiFi DNA Assembly Cloning kit (New England Biolabs) into pFastBac vector (Thermo Fisher) under control of polyhedrin promoter. All constructs were validated by Sanger sequencing. Baculoviruses were generated according to the protocol by Thermo Fisher. The baculoviruses were isolated by plaque purification, amplified three times, and their titers were measured by plaque assay. FLAG-SUUR construct was cloned from SuUR-RA cDNA (LD13959, DGRC). The following open reading frame (ORF) was expressed: MDYKDDDDKH-SUUR-PA(1..962)-VEACGTKLVEKY*. To generate ATPase-dead mutant, SUUR-PA(K59) codon was replaced with an alanine codon by PCR and Gibson cloning. Mod(Mdg4)-67.2-V5-His6 and Mod(Mdg4)-59.1-V5-His6 constructs were cloned from cDNAs mod(mdg4)-RT and mod(mdg4)-RI synthesized as gBlocks by IDT, Inc. The following ORFs were expressed: Mod(Mdg4)-67.2(1..610)-GILEGKPIPNPLLGLDSTGASVEHHHHHH* and Mod(Mdg4)-59.1(1..541)-GILEGKPIPNPLLGLDSTGASVEHHHHHH*. EGG-FLAG and EGG (untagged) were cloned by PCR from egg-RA cDNA (IP14531). The following ORF was expressed: EGG-PA(1..1262)-DYKDDDDK* and EGG-PA(1..1262)-*. FLAG-WDE was cloned by PCR from wde-RA cDNA (LD26050). The following ORF was expressed: MDYKDDDDK-WDE-PA(2..1420)-*. The sequences of FLAG and V5 tags are highlighted in bold typeface. Whereas, typically, amplified virus stocks had titers above 5•109 pfu/ml, FLAG-SUUR viruses reached no more than 2-4•108 pfu/ml, presumably, due to the inhibitory effect of over-expressed protein on viral DNA replication.
Cells, 2•106/ml in Sf-900 II SFM medium (Gibco), were infected at multiplicity of infection (MOI) of ∼10 in PETG shaker flasks (Celltreat, Inc.). After infection for 48-72 hours at 27°C, cells were harvested, and recombinant proteins were purified by FLAG or Ni-NTA affinity chromatography38. Recombinant FLAG-ISWI was prepared as described39. Typical yields were >100 µg purified recombinant protein from 1 L Sf9 cell culture with the exception of SUUR polypeptides that produced no more than 2 µg from 1 L culture, which also adversely affected the protein purity. Full-length recombinant human BRG1 (SMARCA4, EpiCypher) was produced in Sf9 cells and obtained from EpiCypher, Inc.
E. coli
Human TXNRD1 sequence was cloned from a cDNA provided by Addgene (#38863), and TXNRD2 was synthesized as a gBlock gene fragment by IDT, Inc. Both full-length ORFs were inserted in a pET backbone vector in frame with a C-terminal intein-CBD (chitin-binding domain) tag. Protein expression was induced by IPTG in Rosetta 2 cells, and proteins were purified in non-denaturing conditions by chitin affinity chromatography and intein self- cleavage40 followed by anion exchange chromatography (Source 15Q) on FPLC. Detailed cloning and purification methods are available upon request. Note that the cloned human thioredoxin reductase ORFs do not express the C-terminal selenocysteines. They were thus presumed catalytically inactive41, 42 and designated hTXNRD1ci and hTXNRD2ci. They were used exclusively as spike-in mass standards in LCMS acquisitions of Drosophila proteins.
Polypeptide corresponding to the C-terminal specific region of Mod(Mdg4)-67.2 was cloned in pET24b vector in frame with a C-terminal His6 tag. M-Mod(Mdg4)-67.2(403..610)- GILEHHHHHH* was expressed in Rosetta 2 in non-denaturing conditions and purified by Ni- NTA affinity chromatography. The polypeptide (ModT) was dialyzed into PBS (137 mM NaCl, 3 mM KCl, 8 mM NaH2PO4, 2 mM KH2PO4) and used as an antigen for immunizations (see below). All recombinant proteins were examined by SDS-PAGE along with Pierce BSA mass standards (Thermo Fisher), and their concentrations were calculated from infrared scanning of Coomassie-stained gels (Odyssey Fc Imaging System, LI-COR Biosciences).
Crude cell extracts
Nuclear extract from Drosophila embryos ∼1 kg or ∼200 g wild-type (Oregon R) Drosophila embryos were collected 0-12 h after egg deposition (AED) from population cages. The embryos were dechorionated, and nuclear extracts were prepared as described43. Protein concentration was measured by Pierce BCA assay (Thermo Fisher).
E. coli lysate
40-ml Rosetta 2 overnight culture was harvested by centrifugation, resuspended in 20 ml HEG (25 mM HEPES, pH 7.6, 0.1 mM EDTA, 10% glycerol) supplemented with 0.1 M KCl, 1 mM DTT and 2 mM CaCl2. Cells were disrupted by sonication and centrifuged to remove insoluble material. Nucleic acids were digested with 15 units micrococcal nuclease (Sigma Aldrich) for 20 min at 37°C, and the proteins were precipitated with 2 M ammonium sulfate. The pellet was resuspended in 10 ml HEG + 0.1 M KCl + 1 mM DTT with protease inhibitors (0.5 mM benzamidine, 0.2 mM PMSF) and dialyzed against the same buffer. After centrifugation, the concentration of soluble protein was measured by BCA assay, the E. coli lysate was diluted to 1 mg/ml using 100 mM ammonium bicarbonate (ABC) and stored at -80°C.
Fractionation of Drosophila embryonic nuclear extracts
Drosophila nuclear extracts were fractionated by FPLC (Fig. 1b and Extended Data Fig. E3b) on AKTA PURE system (Cytiva Life Sciences). Aliquots of chromatographic fractions were examined by quantitative shotgun proteomics or western blot analyses as described below. Peak SUUR or MMD4-PT fractions were diluted to appropriate ionic strength (if applicable) and used as a starting material for the next chromatographic step. Details on FPLC column sizes and run parameters are available upon request.
Mass-spectroscopy samples
Column fractions
For each chromatographic step, 14 to 20 fractions were selected based on the protein fractionation profile according to the UV (A280) absorbances measurements. 50-100 µl aliquots of chromatographic fractions, starting material (SM) and column flow-through (FT, if applicable) were saved, and protein concentrations were estimated based on their UV absorbances (1,000 mU A280 was considered to be equivalent to 5 mg/ml total protein). Equal volumes of each fraction, SM and FT were used for MS acquisitions, so that no more than 40 µg total protein was processed in each reaction. As a reference, the reactions were supplemented with 1.5 µg each of purified recombinant human thioredoxin reductases 1 and 2 (hTXNRD1ci and hTXNRD2ci, catalytically inactive) expressed in E. coli. Dithiotreitol (DTT) was added to the protein samples to 10 mM and NP-40 – to 0.02%. Reaction volumes were brought to 85 µl with 50 mM ammonium bicarbonate (ABC). All reagents, including water, were HPLC/MS grade. The proteins were reduced for 1 h at 37°C and then alkylated with 30 mM iodoacetamide (IAA, 15 µl 200 mM IAA in water) for 45 min at room temperature in the dark. Alkylated proteins were desalted into 50 mM ABC using ZebaSpin columns (40 kDa MWCO) and digested with 1 µg trypsin for 2 h at 37°C. 1 µg more trypsin was added, and the digestion progressed at 37°C overnight. Tryptic peptides were lyophilized for 2 h on SpeedVac with heat and resuspended in 100 µl Sample Buffer: 1% acetonitrile (ACN) and 0.1% formic acid (FA) in water. Equal volumes (23 µl) of samples were used for IDA and SWATH acquisitions (in triplicate) as described below.
Recombinant SUUR
To generate the recombinant SUUR reference spectral library (ILR), ∼0.5 µg purified recombinant FLAG-SUUR (both 130 and 65 kDa bands, Fig. 1a) was mixed with 1.5 µg each of hTXNRD1ci and hTXNRD2ci and processed for an IDA acquisition as described above, except for 0.5 µg trypsin was used in each cleavage step, and the peptide sample was resuspended in 30 µl Sample Buffer. For SWATH titration of SUUR (Extended Data Figs. E1b, c), 1 µg recombinant FLAG-SUUR was mixed with 25 µg E. coli lysate protein and 1.5 µg each of hTXNRD1ci and hTXNRD2ci. 10-fold serial dilutions down to 10 fg SUUR were also prepared using the mixture of E. coli lysate with reference proteins. The samples were processed for SWATH acquisitions in triplicate as described above, 30 µl of sample per injection.
In-gel digestion of recombinant proteins for LCMS identification
Recombinant SUUR purified by FLAG immunoaffinity chromatography was resolved on SDS-PAGE, stained with Coommassie Blue (Fig. 1a), and eight most prominent protein bands were excised. The gel slices were transferred to 1.5-ml Eppendorf tubes, gently crushed with a RotoDounce pestle and destained with 25 mM ABC in 50% methanol and then with 25 mM ABC in 50% ACN (30 min each at room temperature). The proteins were reduced by 10 mM DTT for 1 h at 55°C and alkylated with 30 mM IAA for 45 min at room temperature in the dark. The gel fragments were washed with 25 mM ABC in 50% ACN, dehydrated with 100% ACN, dried in a SpeedVac, rehydrated by addition of 50 µl 50 mM ABC and digested with 0.25 µg trypsin overnight at 37°C. The peptides were extracted once with 50 µl 10% FA and once with 100 µl 3% FA in 60% ACN, both extracts were combined, dried in a SpeedVac and resuspended in 50 µl Sample Buffer. 40 µl of each sample was injected for IDA acquisitions as described below.
Mass-spectroscopy acquisition methods
Instrument settings
LC-MS/MS analyses were performed on a TripleTOF 5600+ mass spectrometer (AB SCIEX) coupled with M5 MicroLC system (AB SCIEX/Eksigent) and PAL3 autosampler. LC separation was performed in a trap-elute configuration, which consists of a trapping column (LUNA C18(2), 100 Å, 5 μm, 20 × 0.3 mm cartridge, Phenomenex) and an analytical column (Kinetex 2.6 µm XB- C18, 100 Å, 50 × 0.3 mm microflow column, Phenomenex). The mobile phase consisted of water with 0.1% FA (phase A) and 100% ACN containing 0.1% FA (phase B). 200 ng to 10 μg total protein was injected for each acquisition. Peptides in Sample Buffer were injected into a 50-µl sample loop, trapped and cleaned on the trapping column with 3% mobile phase B at a flow rate of 25 μl/min for 4 min before being separated on the analytical column with a gradient elution at a flow rate of 5 μl/min. The gradient was set as follows: 0 to 48 min: 3% to 35% phase B, 48 to 54 min: 35% to 80% phase B, 54 to 59 min: 80% phase B, 59 to 60 min: 80% to 3% phase B, and 60 to 65 min at 3% phase B. An equal volume of each sample (23 µl) was injected four times, once for information-dependent acquisition (IDA), immediately followed by data-independent acquisition (DIA/SWATH) in triplicate. Acquisitions of distinct samples were separated by a blank injection to prevent sample carry-over. The mass spectrometer was operated in positive ion mode with EIS voltage at 5,200 V, Source Gas 1 at 30 psi, Source Gas 2 at 20 psi, Curtain Gas at 25 psi and source temperature at 200°C.
Information-dependent acquisitions (IDA) and data analyses
IDA was performed to generate the reference spectral libraries for SWATH data quantification. The IDA method was set up with a 250-ms TOF-MS scan from 400 to 1250 Da, followed by MS/MS scans in a high sensitivity mode from 100 to 1500 Da of the top 30 precursor ions above 100 cps threshold (100 ms accumulation time, 100 ppm mass tolerance, rolling collision energy and dynamic accumulation) for charge states (z) from +2 to +5. IDA data files were searched using ProteinPilot (version 5.0.2, ABSciex) with a default setting for tryptic digest and IAA alkylation against a protein sequence database. The Drosophila proteome FASTA file with 21,970 protein entries downloaded from UniProt on 3/21/2020 (UP000000803) augmented with sequences for common contaminants as well as hTXNRD1 and hTXNRD2 was used as a reference for the search. Up to two missed cleavage sites were allowed. Mass tolerance for precursor and fragment ions was set to 100 ppm. A false discovery rate (FDR) of 5% was used as the cutoff for peptide identification.
SWATH acquisitions and data analyses
For SWATH acquisitions44, one 50-ms TOF-MS scan from 400 to 1250 Da was performed, followed by MS/MS scans in a high sensitivity mode from 100 to 1500 Da (15-ms accumulation time, 100 ppm mass tolerance, +2 to +5 z, rolling collision energy) with a variable-width SWATH window45. DIA data were quantified using PeakView (version 2.2.0.11391, ABSciex) with SWATH Acquisition MicroApp (version 2.0.1.2133, ABSciex) against selected spectral libraries generated in ProteinPilot. Retention times for individual SWATH acquisitions were calibrated using 20 or more peptides for hTXNRD1ci and hTXNRD2ci. The following software settings were utilized: up to 25 peptides per protein, 6 transitions per peptide, 95% peptide confidence threshold, 5% FDR for peptides, XIC extraction window 20 minutes, XIC width 100 ppm. Protein peak areas were exported as Excel files (Supplementary Table S2) and processed as described below.
MERCI
MERCI is a novel approach for rapid identification of native protein complexes. It combines gradual enrichment for a target subunit of a putative complex by consecutive FPLC steps with parallel quantitative shotgun proteomics of chromatographic fractions. Crude nuclear extract from Drosophila embryos was fractionated as in Fig. 1a. At every step, 40 µg or less total protein from each of 10-20 fractions (equal volumes) was supplemented with a fixed amount (1.5 µg each) of two exogenous reference proteins (human thioredoxin reductases for isolation of Drosophila complexes), reduced, alkylated and digested with trypsin (see above). MS1 and MS2 spectra of tryptic peptides were acquired by IDA, and relative SUUR abundance in fractions was measured by data-independent acquisition (DIA/SWATH, in triplicate). SWATH data were quantified using cognate IDA-derived ion libraries. Protein areas for all quantified proteins were normalized to the sum of those for reference proteins. The relative numbers were averaged across triplicates, with standard deviations calculated. The average numbers for all quantified proteins were further normalized by converting them to Z-scores (see Supplementary Table S2 for an example of calculations). Peak SUUR fractions (typically, 1-5) were then subjected to the next FPLC/MERCI step. After five column steps, the ion library from the ultimate FPLC step (IL5) was used to re-quantify SWATH data from all steps. Z-scores for all purification steps were stitched together, and the large array encompassing all data points for every protein was analyzed by Pearson correlation with SUUR (Supplementary Table S2). The most closely correlated purification profiles served as an indication for protein co-purification, potentially, as subunits of a stable complex.
The dissection of protein interactome by extract fractionation on orthogonal FPLC columns and MS-based approaches has been previously attempted46, 47. However, unlike the newly developed MERCI approach, these studies were aimed at comprehensive, proteome-wide analyses, which managed to only yield data for the most abundant complexes. The major distinction of the MERCI protocol is that it is targeted towards a particular protein (SUUR in this study). The crucial final stage of the MERCI algorithm is re-quantification of all acquired SWATH data using a library acquired from fractions of the last column (IL5, Figs. 1a, d). The target protein and co-purifying polypeptides are substantially enriched after several chromatographic steps (Extended Data Fig. E1e) and thus, yield a greater number of detected peptides, which helps a more precise quantification. Although SWATH allows reliable measurement of picogram amounts of proteins (Extended Data Fig. E1c), the range of quantified polypeptides is limited by those present in IDA acquisitions. For low-abundance proteins, such as SUUR and Mod(Mdg4), specific peptides are not detectable by IDA in earlier chromatographic steps (Supplementary Table S1). Consequently, SWATH quantification using only the cognate ion libraries would not discern the near perfect co-fractionation of SUUR and Mod(Mdg4) in all five steps (Fig. 1d), precluding identification of the SUUR- Mod(Mdg4) complex (Figs. 1d-f).
Biochemical assays with recombinant proteins
Oligonucleosome substrates
Oligonucleosomes were reconstituted in vitro as described48 from supercoiled plasmid DNA (3.2 kb, pGIE-0), native core histones and H1 prepared from Drosophila embryos49 by gradient salt dialysis in the presence of 0.2 mg/ml nuclease-free bovine serum albumin (BSA, New England Biolabs). Quality of reconstitution was assessed by MNase and chromatosome stop assays (Extended Data Figs. E2d, e).
ATPase assay
40 nM recombinant proteins were incubated in 25 µl reaction buffer containing 20 mM HEPES, pH 7.6, 0.15 M NaCl, 4 mM MgCl2, 1 mM ATP, 0.1 mM EDTA, 0.02% (v/v) NP-40 and 0.1 mg/ml nuclease-free BSA for 60 min at 27°C. Some reactions additionally contained 10 nM pGIE-0 plasmid DNA or equivalent amounts of oligonucleosomes ±H1. ATPase assays were performed using ADP-Glo Max kit (Promega). All reactions were performed in triplicate, the results were normalized to the ADP-ATP titration curve according to the kit manual and converted to enzymatic rates (molecules of ATP hydrolyzed per molecule of enzyme per minute). Averages and standard deviations were calculated. Statistical differences were calculated by Mann-Whitney test.
EpiDyne®-PicoGreen™ nucleosome remodeling assay
EpiDyne®-PicoGreen™ is a restriction-enzyme accessibility assay format modified for increased throughput and sensitivity (Extended Data Fig. 2f). In brief, a recombinant ATPase over a concentration range (Extended Data Figs. E2g-j) was mixed with 10 nM EpiDyne biotinylated nucleosome remodeling substrate (EpiCypher) , terminally positioned 6-N-66 (219 bp DNA fragment) or centrally positioned 50-N-66 (263 bp) and 1 mM ATP in 20 µL remodeling buffer, 20 mM Tris-HCl, pH 7.5, 50 mM KCl, 3 mM MgCl2, 0.01% (v/v) Tween-20, 0.01% (w/v) BSA. The remodeling reactions were incubated at 23°C in 384-well format. At indicated time points, the reactions were quenched, and nucleosome substrates were immobilized on an equal volume of streptavidin-coated magnetic beads (NEB), pre-washed and resuspended in 2x quench buffer, 20 mM Tris-HCl, pH 7.5, 600 mM KCl, 0.01% (v/v) Tween-20 and 0.01% (w/v) BSA. Beads were successively washed by collection on a magnet (three times with wash buffer, 20 mM Tris-HCl, pH 7.5, 300 mM KCl, 0.01% (v/v) Tween-20) and buffer replacement (once with RE buffer, 20 mM Tris-HCl, pH 7.5, 50 mM KCl, 3 mM MgCl2, 0.01% (v/v) Tween- 20). Beads were resuspended in 20 µl restriction enzyme mix, 50 units/ml Dpn II (NEB) in RE buffer, and incubated at 23°C for 30 min, collected on a magnet, and supernatants from all wells were transferred to a new plate. They were mixed with an equal volume of Quant-iT™ PicoGreen™ dsDNA reagent (ThermoFisher, Component A) and 1 unit/ml thermolabile proteinase K (NEB) in TE and incubated at 23°C for 1 hr. Fluorescence intensity was detected on an Envision microplate reader with excitation at 480 nm and emission at 531 nm, and data expressed as relative fluorescence units (RFU) through the EnVision Workstation (version 1.13.3009.1409).
Drosophila population culture, mutant stocks and genetics
Wild-type (Oregon R) flies were maintained in population cages on agar-grape juice and yeast paste plates at 26°C, 60% humidity with 12-h dark-light cycle. Mutant flies were reared, and crosses were performed at 26°C on standard cornmeal/molasses medium with dry yeast added to the surface. SuURES was a gift of Igor Zhimulev, and mod(mdg4)m9 was a gift of Yuri Schwartz. All other alleles were obtained from the Bloomington Stock Center, Indiana.
Combinations of alleles were produced either by crosses with appropriate balancers and segregation of markers or by female germline meiotic recombination. Intra-chromosomal recombination events were confirmed by PCR of genomic DNA. Details and PCR primer sequences are available upon request.
Fly wings were dissected from ∼5 days old adult males and transferred to the drop of PBS + 0.1% Triton X-100 (PBST). The wings were soaked in 80% glycerol in PBST and photographed using Zeiss AxioVert 200M microscope with EC Plan-Neofluar 2.5X/0.075 lens in bright field and CCD monochrome camera AxioCam MRm. Adult fly eye images were taken on live, CO2- anesthetized 2-day-old females on Zeiss stereomicroscope Discovery.V12 using CCD color camera AxioCam MRc.
Antibodies, immunoblots and immunoprecipitation (IP)
Polyclonal antibody (anti-ModT) was raised in Guinea pigs by Pocono Rabbit Farm & Lab.
Rabbit polyclonal antibody to the C-terminus of Drosophila XNP/ATRX (anti-XNP) was described previously16. Rabbit and Guinea pig polyclonal antibodies to Drosophila SUUR were a gift of Alexey Pindyurin and Igor Zhimulev. Rabbit polyclonal MMD4(FL) antibody to full- length Mod(Mdg4)-67.2 that recognizes all splice forms of Mod(Mdg4) was a gift of Jordan Rowley and Victor Corces. Mouse monoclonal anti-FLAG (M2, Sigma Aldrich), anti-PCNA (PC10, Cell Signaling), anti-β-tubulin and anti-HP1a (AA12.1 and C1A9, Developmental Studies Hybridoma Bank) were obtained commercially.
Western blotting was performed using standard techniques. For FPLC column fraction analyses, 5-10 µl of starting material and flow-through (if applicable) and 5-15 µl of column fractions were loaded per lane. For expression analyses in salivary glands, 10 salivary glands from L3 larvae of indicated genotype were frozen and thawed, boiled extensively in 40 µl 2x SDS-PAGE loading buffer, centrifuged, and the material equivalent to four salivary glands was loaded per lane. The following dilutions were used: 1:200,000 anti-ModT, 1:1,000 anti- MMD4(FL), 1:1,000 Guinea pig and rabbit anti-SUUR, 1:1,000 anti-HP1a, 1:1,000 anti-β- tubulin and 1:2,000 anti-FLAG. Infrared-labeled secondary antibodies: donkey anti-Guinea pig IRDye 800CW, goat anti-mouse IRDye 800CW, goat anti-rabbit IRDye 800CW, goat anti-rabbit IRDye 680CW and goat anti-mouse IRDye 680RD – were obtained from Li-COR Biosciences and used at 1:10,000. The blots were scanned on Odyssey Fc Imaging System (LI-COR Biosciences).
Immunoprecipitation experiments were performed as described50. 400 µl Drosophila embryonic nuclear extracts (∼10 mg total protein) were incubated with 10 µl Guinea pig anti- ModT, 30 µl rabbit anti-SUUR or 20 µl rabbit anti-XNP antibodies for 3 h at 4°C.
Immunocomplexes were collected by addition of 25 µl protein A-agarose plus (Thermo Fisher) for 2 h at 4°C. After washing four times with 1 ml of buffer HEG (25 mM HEPES, pH 7.6, 0.1 mM EDTA, 10% glycerol) + 0.15 M NaCl, the immunoprecipitated proteins were eluted with 80 µl 2x SDS-PAGE loading buffer and analyzed by SDS-PAGE and western blot using Guinea pig or rabbit anti-SUUR and anti-Mod(Mdg4) and mouse anti-HP1a antibodies. For Mod(Mdg4) and HP1a, 8 µl of immunoprecipitated material (equivalent to 1 mg nuclear extract proteins) and 5% input (2 µl nuclear extract, 50 µg total protein) were analyzed. For SUUR, 20 µl of immunoprecipitated material (equivalent to 2.5 mg nuclear extract proteins) and 10% input (10 µl nuclear extract, 250 µg total protein) were analyzed.
Polytene chromosomes and indirect immunofluorescence (IF) analyses
Polytene chromosomes were prepared and analyzed as described previously19. For all cytological experiments, larvae were reared and collected at 18°C. Salivary glands from wandering third instar larvae were dissected in PBS. Glands were transferred into a formaldehyde-based fixative (one ∼15-μl drop of 3% lactic acid, 45% acetic acid, 3.7% formaldehyde on a coverslip) for 2 min51, squashed, and frozen in liquid N2. The coverslips were removed, and slides were placed in 70% ethanol for 20 min and stored at −20°C. The slides were washed three times for 5 min in PBST. Primary antibodies were incubated overnight at 4°C in PBST + 0.1% BSA and washed three times for 5 min each with PBST. Secondary antibodies were incubated for 2 h at room temperature in PBST + 0.1% BSA and washed three times for 5 min each with PBST.
DNA was stained with 0.1 μg/ml DAPI in PBST for 3 min, and squashes were mounted in Prolong Glass anti-fade mountant (Molecular Probes). Primary and secondary antibodies were used at the following dilutions: Guinea pig anti-ModT, 1:50,000; rabbit anti-SUUR, 1:100; mouse anti-PCNA, 1:1,000; mouse anti-FLAG, 1:100; Alexa Fluor 488 highly cross-absorbed (HCA) goat anti-mouse, Alexa Fluor 568 HCA goat anti-Guinea pig and Alexa Fluor 647 plus HCA goat anti-rabbit, all 1:800. Indirect immunofluorescence (IF) images were obtained with Zeiss AxioVERT 200M microscope and AxioCam MRm mono microscopy camera using a 40x/1.3 Plan-Neofluar or 63x/1.40 Plan-Apochromat lenses with oil immersion. Images were acquired using AxioVision software.
For whole-mount IF staining, L3 larvae were reared at 18°C, and salivary glands were dissected in PBS and fixed in 3.7% formaldehyde (Sigma Aldrich) for 20 min at room temperature. The glands were washed in PBS + 0.3% Triton X-100 and permeabilized for 30 min at 37°C in PBS + 1% Triton X-100. Blocking was performed for 30 min at room temperature in PBS+ 0.3% Triton X-100 supplemented with 10% fetal calf serum and 1% BSA. The glands were incubated with primary antibodies diluted in blocking solution for 48 h at 4°C, washed three times with PBS + 0.3% Triton X-100 for 30 min, and incubated with secondary antibodies in blocking solution overnight at 4°C. The stained glands were washed three times with PBS + 0.3% Triton X-100 for 30 min, stained with DAPI (0.1 μg/ml) for 30 min, and mounted in Prolong Gold anti-fade (Invitrogen). IF images were obtained on a Leica SP8 confocal microscope using a 20X/0.75 PLAPO lens and processed using ImageJ software (Fiji).
Next generation sequencing analyses (NGS)
Salivary glands from female wandering third-instar larvae were isolated and flash-frozen in liquid N2 until all samples were collected. Genomic DNA for sequencing was prepared from 25 L3 salivary gland pairs or 10 mg embryos (0-6 h AED) using DNeasy Blood and Tissue kit (Qiagen). Each sample was prepared in triplicate. The tissues were soaked in 180 µl buffer ATL + 20 µl proteinase K (15 mg/ml) and lysed for 2-3 h at 55°C. The reactions were cooled to room temperature, supplemented with 4 µl RNase A, ∼40 mg/ml (Sigma Aldrich), and RNA was digested for 10 min at room temperature. The genomic DNA was fragmented with 0.002 units DNase I (Thermo Fisher) in 100-µl reactions containing 10 mM Tris-HCl, pH 7.5, 10 mM MnCl2, 0.1 mM CaCl2, 0.1 mg/ml RNase A and 0.2 mg/ml nuclease-free BSA (1x reaction buffer) for 15 min at 37°C. (DNAse I dilutions were prepared using 1x reaction buffer.) Reactions were stopped by adding 5 µl 0.5 M EDTA, and DNase I was inactivated for 20 min at 65°C. The fragmented DNA was purified on QiaQuick columns using PCR purification kit (Qiagen) and eluted in 40 µl 10 mM Tris-HCl, pH 8.0. The size distribution of DNA fragments (200-600 bp, average ∼400 bp) was confirmed and DNA concentration was measured on 2100 BioAnalyzer (Agilent). Libraries were prepared from 20 ng of fragmented genomic DNA with the ThruPLEX DNA-seq kit using SMARTer® DNA Unique Dual Indexes (TakaraBio) and sequenced 150-bp paired-end reads on an NovaSeq 6000 (Novagene).
The sequencing quality of each sample was assessed using FASTQC version 0.11.752. Raw paired-end reads were trimmed of adapters using BBDuk from the BBTools software version 38.71 using the parameters: ktrim=r ref=adapters rcomp=t tpe=t tbo=t hdist=1 mink=1153. Reads were aligned to the BDGP Release 6 of the Drosophila melanogaster genome (dm6)54 using Bowtie2 version 2.3.4.155 and parameters -q --local - -very-sensitive-local --no-unal --no-mixed --no-discordant -- phred33 -I 10 -X 700. Duplicate reads were marked using Picard 2.2.456 and SAM files were converted to BAM format, filtered for quality (-bq 5), and removed of duplicates (-bF 0x400) using Samtools version 1.957. For visualization, replicates were merged (samtools merge) and coverage was calculated across 50-bp bins and normalized to counts per million (CPM) using deeptools version 3.2.0: bamCoverage -bs 50 –normalizeUsing CPM58. Each genotype was scaled to the diploid Oregon R embryo signal in 5-kb bins: bigWigCompare –-operation first -bs 5000. DamID-chip data for SUUR and Su(Hw) were retrieved from GSE2206936. Su(Hw) insulator class II elements were also used59.
UR domains were called using a custom R script to identify regions at least 100 kb in length that fell below the average chromosomal read count as described19. Visualization of all data was performed on the UCSC Genome browser using the dm6 release of the Drosophila genome60.
Each data set was auto-scaled to its own min and maximum and the data were windowed by mean with 16-pixel smoothing applied.
Quantitative real-time PCR
Genomic DNA samples prior to DNase I fragmentation (see above) were diluted to ∼0.25 ng/µl. Real-time PCR was performed using 0.5 ng genomic DNA on a ViiA7 thermocycler (Applied Biosystems) with a three-step protocol (95°C 15 sec, 60°C 30 sec, 68°C 60 sec) and iTaq Universal SYBR Green Supermix (Bio-Rad). Primer sequences are provided in Extended Data Table E2. Each reaction was performed in three technical replicates for each of the three biological samples (N=9). For each amplicon, the average Ct value (<CT<) was calculated and normalized to the average Ct value for a random intergenic genomic sequence as a loading control. Further, for each template, the ΔCt was normalized to the average Ct value for embryonic DNA (diploid control). Standard deviation (σCt) for each reaction in triplicate was also calculated. The following ΔΔCt formula was used: <ΔΔCt> = (<CTTARGET> – <CTINTERGENIC86D>)SG – (<CTTARGET>– <CTINTERGENIC86D>)embryo. Standard deviations for <ΔΔCt> were calculated as σΔΔCt = square root of (σ2target + σ2intergenic86D)/2. ΔΔCt’s were converted to DNA copy numbers as 2−<ΔΔCt>. The confidence interval was calculated in the range of 2−<ΔΔCt>–σ and 2−<ΔΔCt>+σ.
Contributions
E.N.A. designed and performed quantitative proteomic, genetic and cytological experiments, prepared DNA for NGS and analyzed the data. A.V.E. purified native proteins by FPLC, cloned, expressed and purified recombinant proteins, designed and performed biochemical assays in vitro, performed real-time PCR analyses and analyzed the data. M.N. and C.H. prepared DNA libraries for NGS and analyzed the data. L.S. performed biochemical assays with recombinant proteins in vitro and analyzed the data. E.V. prepared nuclear extracts and performed western blot analyses. M.C.K. supervised L.S., analyzed and interpreted the data. R.J. D. supervised M.N. and C.H., analyzed and interpreted the data and co-wrote the manuscript (with D.V.F.). A.I.S. supervised E.N.A., analyzed and interpreted the data and co-wrote the manuscript (with D.V.F.). D.V.F. conceptualized the study, supervised E.N.A. and A.V.E., analyzed and interpreted the data and wrote the manuscript. All authors contributed to editing of the final version of the manuscript.
Ethics declarations
Competing interests
L.S. and M.C.K. are employed by Epicypher, Inc., a commercial developer and supplier of the EpiDyne® nucleosomes and associated remodeling assay platforms used in this study. The remaining authors declare no competing interests.
Supplementary information
Supplementary Table S1.xlsx. Identities of proteins and peptide spectra from ion libraries used for MERCI quantification of SUMM4.
Supplementary Table S2.xlxs. Raw protein area data from SWATH acqusitions quantified by IL5 and MERCI correlation analyses.
Extended data figures and tables

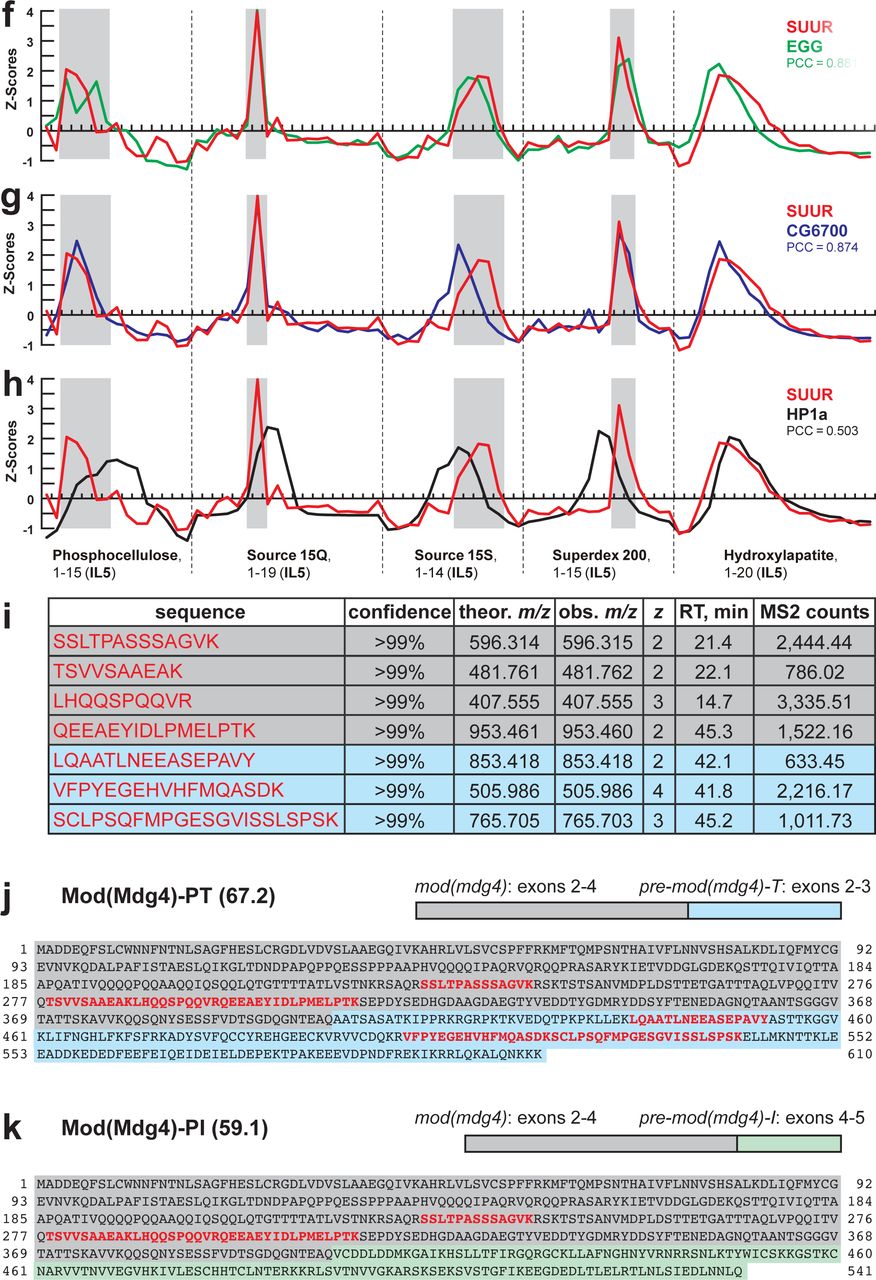
a, Representation of SUUR in ion libraries ILR and IL1-5 (Fig. 1b, Suppl. Table S1). Total number of identified proteins and the confidence rank of SUUR among them as well as the total number of detected peptides (95% confidence) and the number of SUUR-specific peptides are shown. b, Schematic of SWATH quantification of recombinant SUUR, nuclear extract (starting material) and FPLC fractions for SUUR using ion library ILR. c, SUUR titration curve obtained by SWATH quantitation of 10 fg – 1 µg recombinant FLAG- SUUR in the presence of 25 µg E. coli lysate; both axes are logarithmic (log10). Red rectangle, SUUR quantification in 25 µg nuclear extract; error bars, standard deviations (N=3). d, SWATH quantitation profiles of SUUR fractionation across individual FPLC steps. Ion library ILR was used for SWATH quantification, and relative amounts were converted to estimated ng SUUR per fraction. Error bars, standard deviations (N=3); colored boxes, peak fractions of SUUR. e, SUUR purification by FPLC. Total protein was measured by BCA assay, and SUUR was measured as in (d). Relative purity, purification factor in each step and cumulative purification factor are shown. f-h, SWATH quantitation profiles of SUUR (red), EGG (green), CG6700 (blue) and HP1a (black) fractionation across five FPLC steps as in Fig. 1d. Pearson correlation coefficients are shown (Fig. 1e). i, Mod(Mdg4)-specific peptides from ion library IL5 (Suppl. Table S1). Gray shading, peptides specific to the common part (coding exons 2-4) of Mod(Mdg4); cyan shading, peptides specific to polypeptide Mod(Mdg4)-67.2 encoded by pre-mod(mdg4)-T, exons 2-3. j, Mod(Mdg4)-67.2 polypeptide sequence. The common part is shaded in gray, splice form-specific part is shaded in cyan. Peptides from ion library IL5 (as in i) are highlighted in bold red. k, Mod(Mdg4)-59.1 polypeptide sequence. The common part is shaded in gray, splice form-specific part is shaded in green.
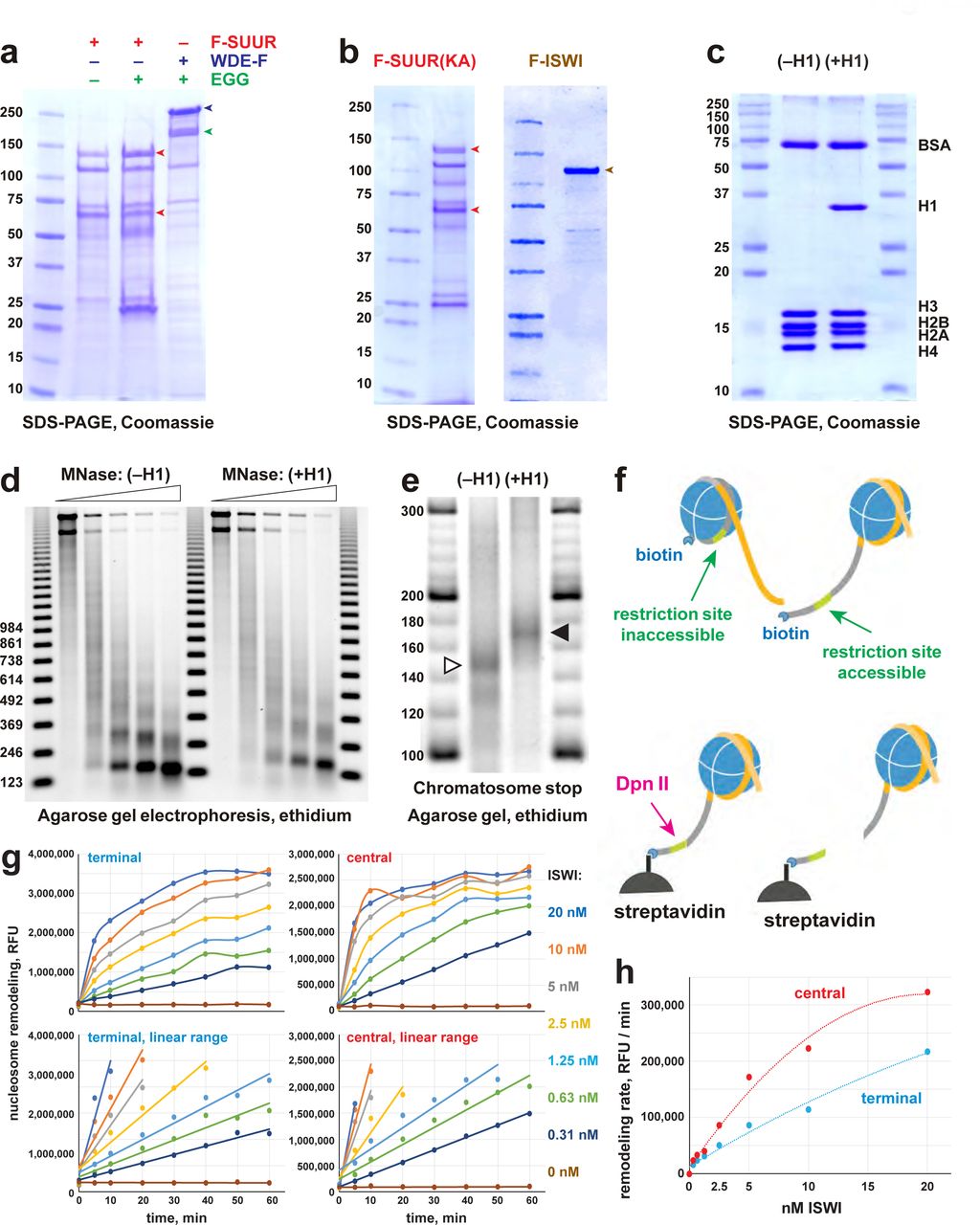

a, Physical interactions of recombinant EGG, SUUR and WDE. Untagged EGG (green arrowhead) was co-expressed with FLAG-SUUR (red arrowheads, p130 and p65) or WDE-FLAG (purple arrowhead) in Sf9 cells and purified by FLAG affinity chromatography. EGG forms a specific complex with WDE but not SUUR. b, Recombinant FLAG-SUUR(K59A) and FLAG-ISWI expressed in Sf9 cells. See legend to Fig. 1b. c, Protein composition of in vitro reconstituted chromatin. Oligonucleosomes prepared from plasmid DNA and core histones with (+H1) or without H1 (–H1) were analyzed by SDS-PAGE and Coomassie staining. Positions of BSA, H1 and core histone bands are indicated on the right; molecular mass markers (kDa) are shown on the left. d, Micrococcal nuclease (MNase) analysis of reconstituted chromatin. Partial digestion with five different dilutions of MNase was performed on H1-free (– H1) and H1-containing (+H1) oligonucleosomes. Deproteinated DNA fragments were analyzed by agarose gel electrophoresis and stained with ethidium. Note the increased nucleosome repeat length in (+H1) lanes consistent with H1 incorporation. Triangles at the top indicate increasing MNase concentrations; 123 bp ladder was used as a molecular mass marker. e, Chromatosome stop assay. Oligonucleosomes assembled with or without H1 were subjected to partial MNase digestion, and DNA was analyzed by agarose gel electrophoresis and ethidium bromide staining. Positions of the core particle and chromatosome DNA are indicated by arrowheads. DNA fragment sizes in the 20-bp DNA ladder marker are shown. f, EpiCypher® EpiDyne®- PicoGreen™ assay design. EpiDyne nucleosomes encompass a restriction site shielded by the initial nucleosome position but exposed for Dpn II cleavage upon remodeling (sliding or displacement). Biotinylated substrates are immobilized on streptavidin magnetic beads. Digest by Dpn II releases the substrates from beads, and supernatant is quantified by PicoGreen™ (dsDNA detection reagent) fluorescence. g, Titration of Drosophila ISWI remodeling activity using terminally (6-N-66) or centrally (50-N-66) positioned mononucleosomes. Early reaction time points were separately plotted to indicate linear ranges. RFU, relative fluorescence units. h, Early remodeling rates for ISWI were calculated by linear regression analyses of data in respective linear ranges. ISWI exhibits a stronger remodeling activity with a centrally positioned nucleosome substrate. i, Titration of human BRG1 remodeling activity. Data are presented as in (g). j, Early remodeling rates for BRG1 were calculated and plotted as in (h). BRG1 does not exhibit a bias towards remodeling centrally or terminally positioned nucleosomes.
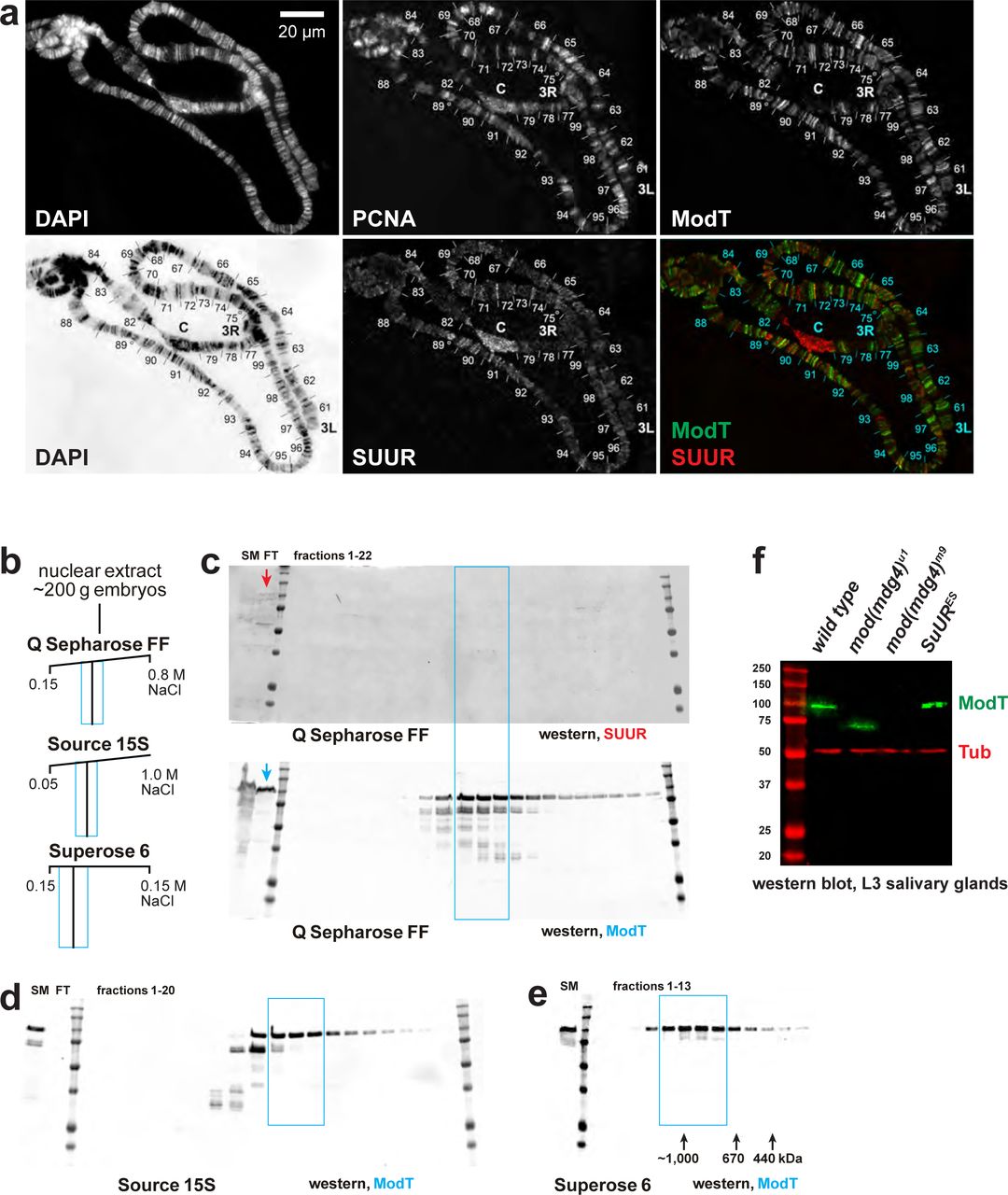

a, Colocalization of SUUR and Mod(Mdg4)-67.2 in wild-type polytene chromosomes. See legend to Fig. 3a. Positions of 3L and 3R telomeres are indicated; approximate boundaries of cytological regions are shown according to63; positions of IH regions 75C and 89E that are under-replicated and responsive to SuUR mutation are marked by circles. b, Schematic of partial FPLC purification of an alternative complex of Mod(Mdg4)-67.2. Cyan boxes, fraction ranges used for the next chromatographic step. c, Western blot analyses of Q Sepharose FF fractions with SUUR and ModT antibodies. SUUR and ∼25% total Mod(Mdg4)-67.2 present in the starting material (SM) fractionate in the flow-through (FT, arrows), whereas Mod(Mdg4)-67.2 also fractionates as an additional, SUUR-free peak (cyan box). Molecular mass markers are as in Fig. 1g. d, Western blot analysis of Source 15S fractions with the ModT antibody. e, Western blot analyses of Superose 6 fractions with the ModT antibody. Black arrows, expected peaks of globular proteins with indicated molecular masses in kDa. f, Western blot analyses of lysates of whole salivary glands. L3 salivary glands from homozygous animals of indicated genotypes were probed with ModT (green) and β-tubulin antibodies (red, loading control). Mass marker sizes (kDa) are shown on the left. g, Abnormal spatiotemporal distribution of SUUR in polytene chromosomes of mod(mdg4) mutants. See legend to Fig. 3b. Although SUUR is not properly loaded into mod(mdg4) chromosomes during early endo-S phase (as in wild type), its deposition partially recovers during late endo-S.


a, qPCR- and NGS-measured DNA copy numbers in region 4D. The data were obtained and presented as for the 75C region (Fig. 4f). b, Genome-wide analyses of DNA copy numbers in Drosophila salivary gland cells (w1118 control). Chromosome arms are shown on the left. Brown- and green-shades boxes, mapped pericentric and telomeric heterochromatin regions64, respectively. Asterisks, positions of UR domains (Extended Data Table E1). See legend to Fig. 4g for other designations. c, Genome-wide analyses of DNA copy numbers in Drosophila salivary gland cells in chromosomes X, 2L, 2R and 3R. The data were obtained and presented as for the 3L arm (Fig. 4g). d, Close-up views of DNA copy numbers by high-throughput sequencing for additional genomic regions. Approximate cytogenetic locations are indicated at the top of each panel. Short vertical bars at the bottom, positions of mapped Su(Hw) binding sites59. See (c) for other designations. e, Sample plots of DamID profiles for SUUR (red) and Su(Hw) (purple), log2 enrichment over Dam-only control36. Positive values are plotted in dark colors and negative values in light colors for contrast. DNA copy numbers in salivary gland cells (black) indicate UR IH domains. Vertical bars, Su(Hw) binding sites59.
Domains of under-replication (UR) in euchromatic arms of polytene chromosomes were called in w1118 as described in Methods. Their genomic coordinates, approximate cytological location (“Cyto band”) and average DNA copy numbers (“<CN>”) in homozygous w1118, SuURES, mod(mdg4)m9 and mod(mdg4)u1 L3 larvae are shown. <CN> numbers were normalized to the average DNA copy numbers across euchromatic genome. Percent UR recovery levels were calculated as (<CN>mut – <CN>w) / (1 – <CN>w). UR was called as suppressible by a mutant if Recovery > 12.5%. Averages of <CN> across all called UR domains and averages of percent Recovery across all suppressible UR domains (“<Recovery>”, bottom row) were adjusted for each UR domain length. Calculation errors = standard deviations.
Genomic coordinates indicate full amplicons, including the length of each primer. Coordinates refer to the BDGP R6/dm3 assembly.
Acknowledgments
This paper is dedicated to the memory of Jonathan R. Warner who participated in initial discussions that have led to the development of MERCI technology. We thank B. Bartholdy, K. Beirit, B. Birshtein V. Elagin, M. Gamble, T. Kolesnikova, A. Lusser, A. Pindyurin, Y. Schwartz, S. Sidoli and I. Zhimulev for helpful discussions and critical reading of the manuscript. We thank Y. Schwartz and Bloomington Stock Center for fly stocks and V. Corces, A. Pindyurin, J. Rowley and I. Zhimulev for antibodies. We are grateful to A. Aravin and B. Godneeva for cloning EGG and WDE baculovirus constructs. We thank A. Kumar and N. Baker for help with confocal microscopy, and M. Rogers and J. Secombe for the use of Zeiss Discovery.V12. Confocal images were obtained at the Analytical Imaging Facility (Einstein). This research was supported by the National Institutes of Health (NIH) grants R01 GM074233 to D.V.F., R01 GM129244 to A.I.S, R01 GM124201 to R.J.D. and R44 GM123869 to M.C.K. (EpiCypher). M.N. was supported by postdoctoral training grants K12 GM000678 and T32 CA217824. LCMS instrument was purchased with an equipment supplement from the National Institute of General Medical Sciences (NIGMS) to D.V.F. and A.I.S. We thank P. Schultes for help with maintaining the instrument.
Footnotes
↵† equally contributing authors





{kind=link}
{kind=link}
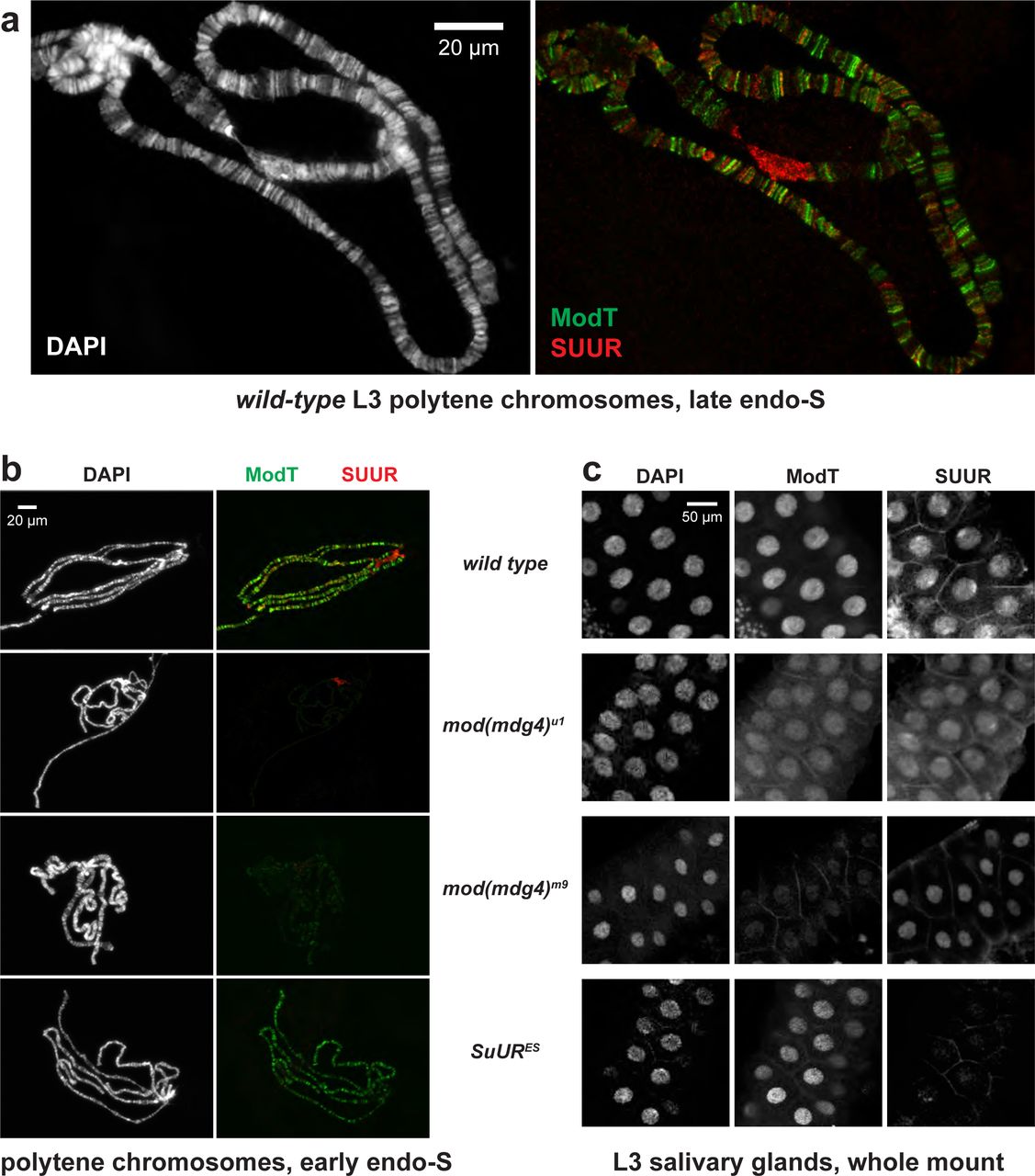{kind=link}
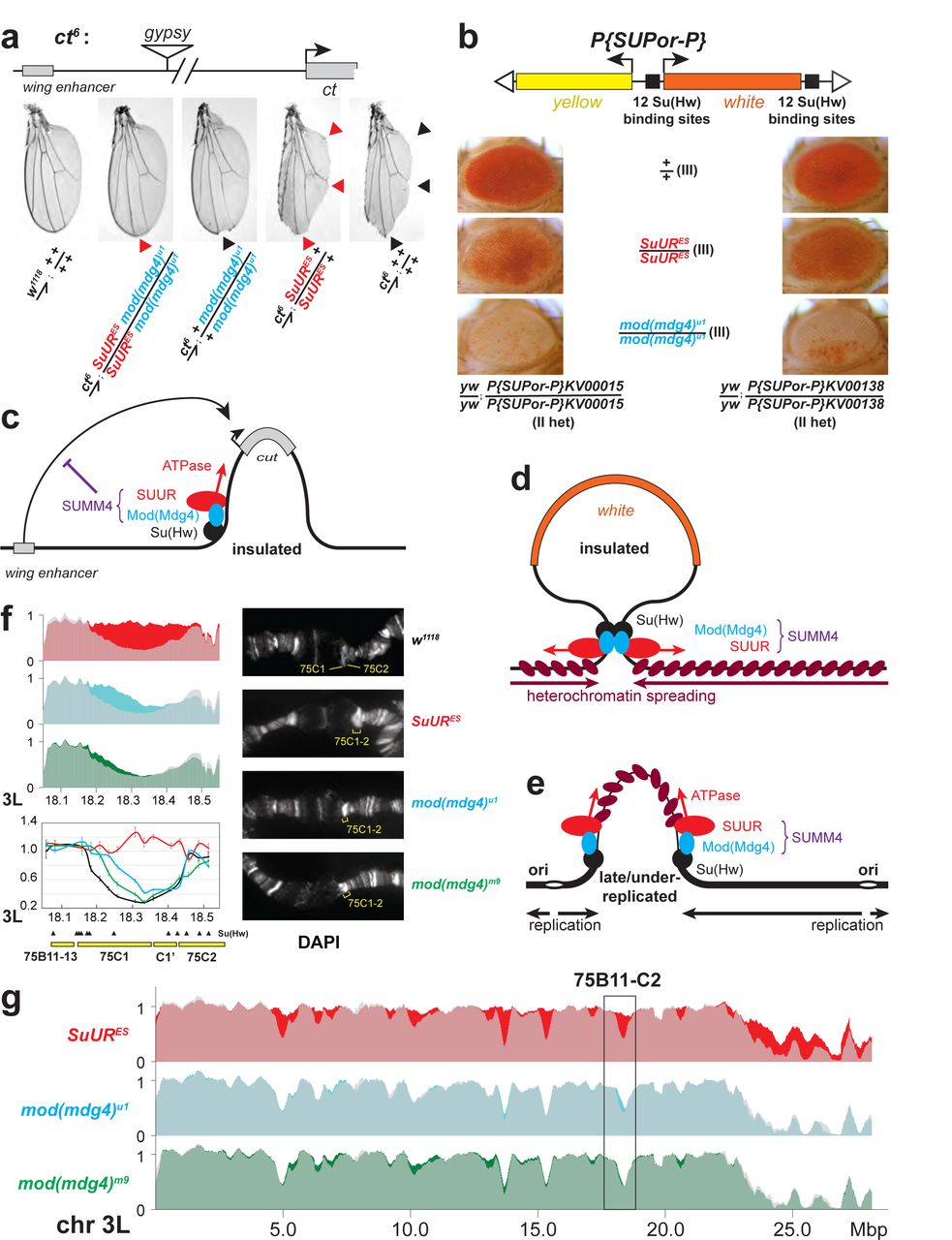{kind=link}
{kind=link}
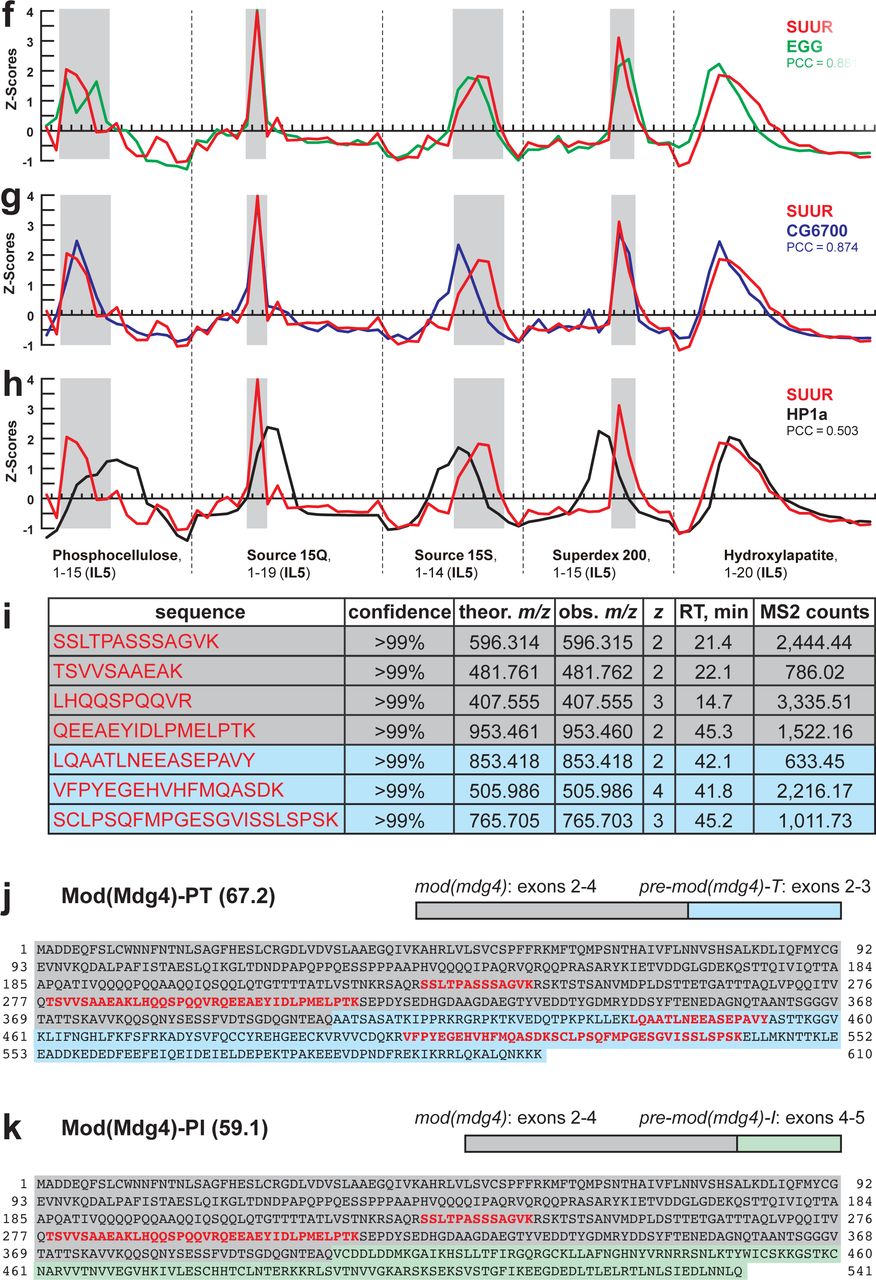{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}